
小白學 Python 爬蟲(33):爬蟲框架 Scrapy 入門基礎(一)

人生苦短,我用 Python
前文傳送門:
小白學 Python 爬蟲(1):開篇
小白學 Python 爬蟲(2):前置準備(一)基本類庫的安裝
小白學 Python 爬蟲(3):前置準備(二)Linux基礎入門
小白學 Python 爬蟲(4):前置準備(三)Docker基礎入門
小白學 Python 爬蟲(5):前置準備(四)資料庫基礎
小白學 Python 爬蟲(6):前置準備(五)爬蟲框架的安裝
小白學 Python 爬蟲(7):HTTP 基礎
小白學 Python 爬蟲(8):網頁基礎
小白學 Python 爬蟲(9):爬蟲基礎
小白學 Python 爬蟲(10):Session 和 Cookies
小白學 Python 爬蟲(11):urllib 基礎使用(一)
小白學 Python 爬蟲(12):urllib 基礎使用(二)
小白學 Python 爬蟲(13):urllib 基礎使用(三)
小白學 Python 爬蟲(14):urllib 基礎使用(四)
小白學 Python 爬蟲(15):urllib 基礎使用(五)
小白學 Python 爬蟲(16):urllib 實戰之爬取妹子圖
小白學 Python 爬蟲(17):Requests 基礎使用
小白學 Python 爬蟲(18):Requests 進階操作
小白學 Python 爬蟲(19):Xpath 基操
小白學 Python 爬蟲(20):Xpath 進階
小白學 Python 爬蟲(21):解析庫 Beautiful Soup(上)
小白學 Python 爬蟲(22):解析庫 Beautiful Soup(下)
小白學 Python 爬蟲(23):解析庫 pyquery 入門
小白學 Python 爬蟲(24):2019 豆瓣電影排行
小白學 Python 爬蟲(25):爬取股票資訊
小白學 Python 爬蟲(26):為啥買不起上海二手房你都買不起
小白學 Python 爬蟲(27):自動化測試框架 Selenium 從入門到放棄(上)
小白學 Python 爬蟲(28):自動化測試框架 Selenium 從入門到放棄(下)
小白學 Python 爬蟲(29):Selenium 獲取某大型電商網站商品資訊
小白學 Python 爬蟲(30):代理基礎
小白學 Python 爬蟲(31):自己構建一個簡單的代理池
小白學 Python 爬蟲(32):非同步請求庫 AIOHTTP 基礎入門
引言
首先恭喜看到這篇文章的各位同學,從這篇文章開始,整個小白學 Python 爬蟲系列進入最後一部分,小編計劃是介紹一些常用的爬蟲框架。
說到爬蟲框架,首先繞不過去的必然是 Scrapy 。
Scrapy 是一個基於 Twisted 的非同步處理框架,是純 Python 實現的爬蟲框架,其架構清晰,模組之間的耦合程度低,可擴充套件性極強,可以靈活完成各種需求。
當然第一件事兒還是各種官方地址:
Scrapy 官網: https://scrapy.org/
Github:https://github.com/scrapy/scrapy
官方文件:https://scrapy.org/doc/
架構概述
首先看一下 Scrapy 框架的架構體系圖:
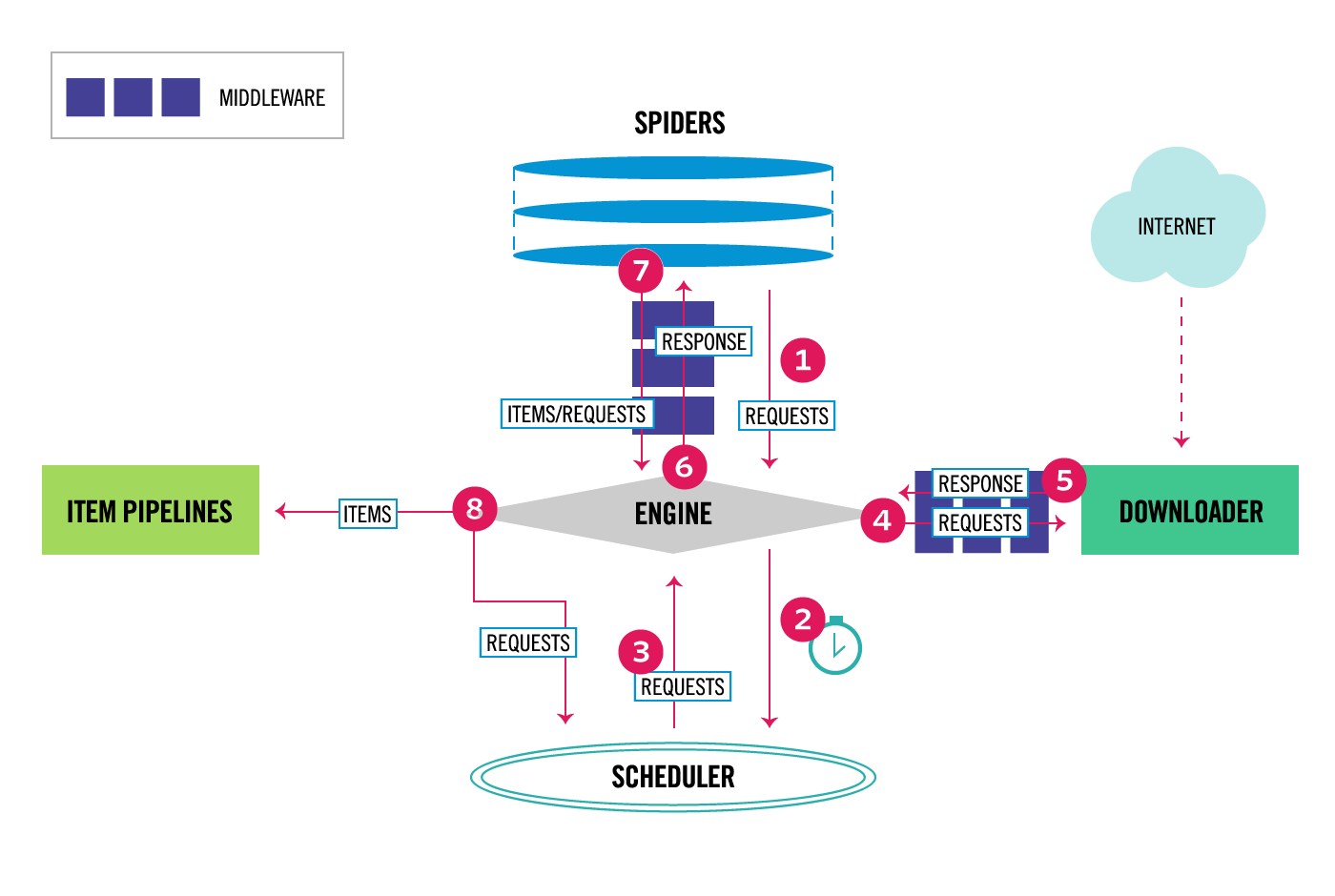
從這張圖中,可以看到 Scrapy 分成了很多個元件,每個元件的含義如下:
- Engine 引擎:引擎負責控制系統所有元件之間的資料流,並在發生某些操作時觸發事件。
- Item 專案:它定義了爬取結果的資料結構,爬取的資料會被賦值成該物件。
- Scheduler 排程器:用來接受引擎發過來的請求並加入佇列中,並在引擎再次請求的時候提供給引擎。
- Downloader 下載器:下載器負責獲取網頁並將其饋送到引擎,引擎又將其饋給蜘蛛。
- Spiders 蜘蛛:其內定義了爬取的邏輯和網頁的解析規則,它主要負責解析響應並生成提取結果和新的請求。
- Item Pipeline 專案管道:負責處理由蜘蛛從網頁中抽取的專案,它的主要任務是清洗、驗證和儲存資料。
- Downloader Middlewares 下載器中介軟體:下載器中介軟體是位於引擎和Downloader之間的特定掛鉤,它們在從引擎傳遞到Downloader時處理請求,以及從Downloader傳遞到Engine的響應。
- Spider Middlewares 蜘蛛中介軟體:蜘蛛中介軟體是位於引擎和蜘蛛之間的特定掛鉤,並且能夠處理蜘蛛的輸入(響應)和輸出(專案和請求)。
上面這張圖的資料流程如下:
- 該引擎獲取從最初請求爬行 蜘蛛。
- 該引擎安排在請求 排程程式和要求下一個請求爬行。
- 該計劃返回下一請求的引擎。
- 該引擎傳送請求到 下載器,通過 下載器中介軟體。
- 頁面下載完成後, Downloader會生成一個帶有該頁面的響應,並將其傳送到Engine,並通過 Downloader Middlewares。
- 該引擎接收來自響應 下載器並將其傳送到所述 蜘蛛進行處理,通過蜘蛛中介軟體。
- 該蜘蛛處理響應並返回刮下的專案和新的要求(跟隨)的 引擎,通過 蜘蛛中介軟體。
- 該引擎傳送處理的專案,以 專案管道,然後把處理的請求的排程,並要求今後可能請求爬行。
- 重複該過程(從步驟1開始),直到不再有Scheduler的請求為止 。
這張圖的名詞有些多,記不住實屬正常,不過沒關係,後續小編會配合著示例程式碼,和各位同學一起慢慢的學習。
基礎示例
先來個最簡單的示例專案,在建立專案之前,請確定自己的環境已經正確安裝了 Scrapy ,如果沒有安裝的同學可以看下前面的文章,其中有介紹 Scrapy 的安裝配置。
首先需要建立一個 Scrapy 的專案,建立專案需要使用命令列,在命令列中輸入以下命令:
scrapy startproject first_scrapy然後一個名為 first_scrapy 的專案就建立成功了,專案檔案結構如下:
first_scrapy/
scrapy.cfg # deploy configuration file
first_scrapy/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py- scrapy.cfg:它是 Scrapy 專案的配置檔案,其內定義了專案的配置檔案路徑、部署相關資訊等內容。
- items.py:它定義 Item 資料結構,所有的 Item 的定義都可以放這裡。
- pipelines.py:它定義 Item Pipeline 的實現,所有的 Item Pipeline 的實現都可以放這裡。
- settings.py:它定義專案的全域性配置。
- middlewares.py:它定義 Spider Middlewares 和 Downloader Middlewares 的實現。
- spiders:其內包含一個個 Spider 的實現,每個 Spider 都有一個檔案。
到此,我們已經成功建立了一個 Scrapy 專案,但是這個專案目前是空的,我們需要再手動新增一隻 Spider 。
Scrapy 用它來從網頁裡抓取內容,並解析抓取的結果。不過這個類必須繼承 Scrapy 提供的 Spider 類 scrapy.Spider,還要定義 Spider 的名稱和起始請求,以及怎樣處理爬取後的結果的方法。
建立 Spider 可以使用手動建立,也可以使用命令建立,小編這裡演示一下如何使用命令來建立,如下:
scrapy genspider quotes quotes.toscrape.com將會看到在 spider 目錄下新增了一個 QuotesSpider.py 的檔案,裡面的內容如下:
# -*- coding: utf-8 -*-
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
pass
可以看到,這個類裡面有三個屬性 name 、 allowed_domains 、 start_urls 和一個 parse() 方法。
- name,它是每個專案唯一的名字,用來區分不同的 Spider。
- allowed_domains,它是允許爬取的域名,如果初始或後續的請求連結不是這個域名下的,則請求連結會被過濾掉。
- start_urls,它包含了 Spider 在啟動時爬取的 url 列表,初始請求是由它來定義的。
- parse,它是 Spider 的一個方法。預設情況下,被呼叫時 start_urls 裡面的連結構成的請求完成下載執行後,返回的響應就會作為唯一的引數傳遞給這個函式。該方法負責解析返回的響應、提取資料或者進一步生成要處理的請求。
到這裡我們就清楚了, parse() 方法中的 response 是前面的 start_urls 中連結的爬取結果,所以在 parse() 方法中,我們可以直接對爬取的結果進行解析。
先看下網頁的 DOM 結構:
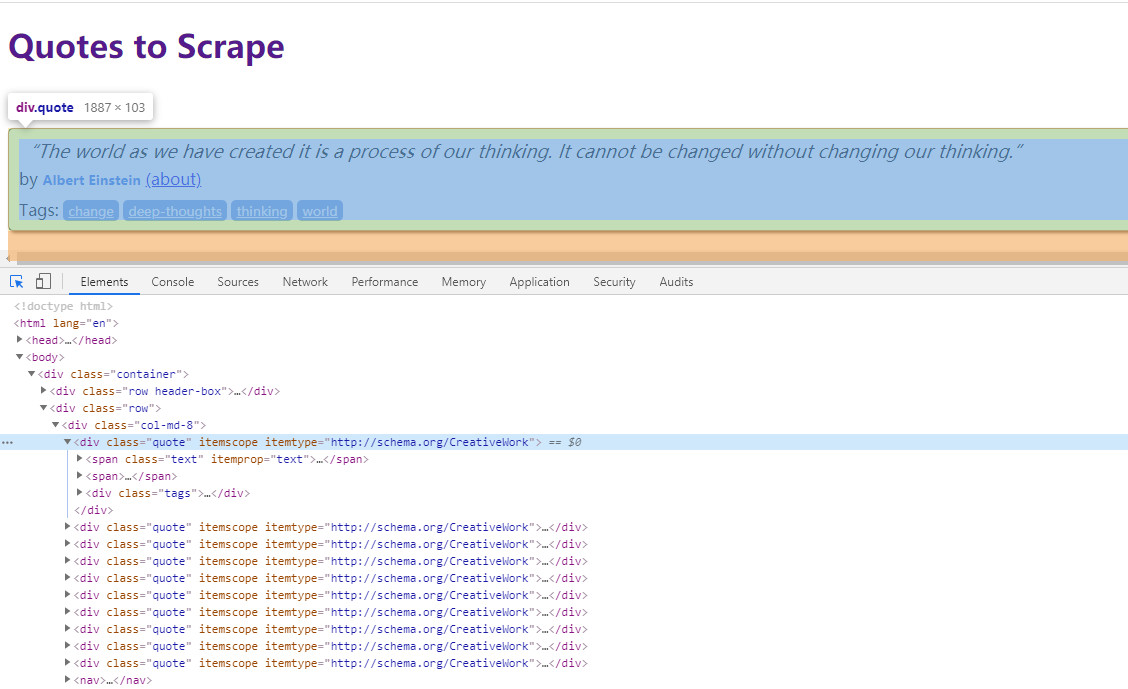
接下來要做的事情就比較簡單了,獲取其中的資料,然後將其打印出來。
資料提取的方式可以是 CSS 選擇器也可以是 XPath 選擇器,小編這裡使用的是 CSS 選擇器,將我們剛才的 parse() 方法進行一些簡單的改動,如下:
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
text = quote.css('.text::text').extract_first()
author = quote.css('.author::text').extract_first()
tags = quote.css('.tags .tag::text').extract()
print("text:", text)
print("author:", author)
print("tags:", tags)首先是獲取到所有的 class 為 quote 的元素,然後將所有元素進行迴圈後取出其中的資料,最後對這些資料進行列印。
程式到這裡就寫完了,那麼接下來的問題是,我們如何執行這隻爬蟲?
Scrapy 的執行方式同樣適用適用命令列的,首先要到這個專案的根目錄下,然後執行以下程式碼:
scrapy crawl quotes結果如下:
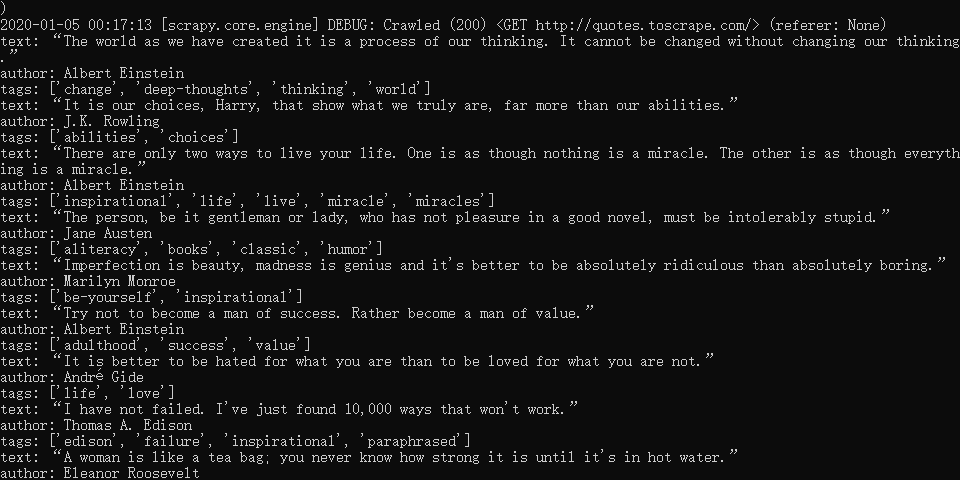
可以看到,我們剛才 print() 的內容正常的列印在了命令列中。
除了我們 print() 中的內容的列印,還可以看到在 Scrapy 啟動的過程中, Scrapy 輸出了當前的版本號以及正在啟動的專案名稱,並且在爬取網頁的過程中,首先訪問了 http://quotes.toscrape.com/robots.txt 機器人協議,雖然這個協議在當前這個示例中響應了 404的狀態碼,但是 Scrapy 會根據機器人協議中的內容進行爬取。
示例程式碼
本系列的所有程式碼小編都會放在程式碼管理倉庫 Github 和 Gitee 上,方便大家取用。
示例程式碼-Github
示例程式碼-Gitee
參考
https://docs.scrapy.org/en/latest/intro/tutorial.html
https://docs.scrapy.org/en/latest/topics/architecture.html
https://cuiqingcai.com/8337.h