
資料探勘演算法-Logistic迴歸
(一)認識Logistic迴歸(LR)分類器
首先,Logistic迴歸雖然名字裡帶“迴歸”,但是它實際上是一種分類方法,主要用於兩分類問題,利用Logistic函式(或稱為Sigmoid函式),自變數取值範圍為(-INF, INF),自變數的取值範圍為(0,1),函式形式為:
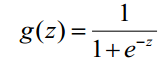
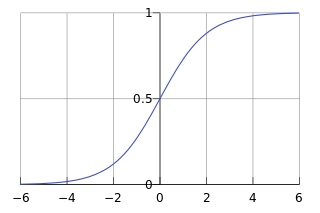
由於sigmoid函式的定義域是(-INF, +INF),而值域為(0, 1)。因此最基本的LR分類器適合於對兩分類(類0,類1)目標進行分類。Sigmoid 函式是個很漂亮的“S”形,如下圖所示:
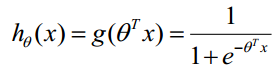
函式的值表示結果為1的概率,就是特徵屬於y=1的概率。因此對於輸入x分類結果為類別1和類別0的概率分別為:
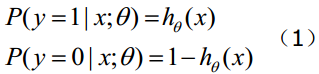
當我們要判別一個新來的特徵屬於哪個類時,按照下式求出一個z值:
(x1,x2,...,xn是某樣本資料的各個特徵,維度為n)
進而求出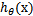
Logistic迴歸可以也可以用於多分類的,但是二分類的更為常用也更容易解釋。所以實際中最常用的就是二分類的Logistic迴歸。LR分類器適用資料型別:數值型和標稱型資料。其優點是計算代價不高,易於理解和實現;其缺點是容易欠擬合,分類精度可能不高。
(二)Logistic迴歸數學推導
1,梯度下降法求解Logistic迴歸
首先,理解下述數學推導過程需要較多的導數求解公式,可以參考“常用基本初等函式求導公式積分公式”。
假設有n個觀測樣本,觀測值分別為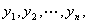
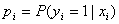
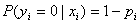
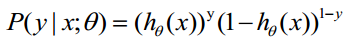
因為各項觀測獨立,所以它們的聯合分佈可以表示為各邊際分佈的乘積:
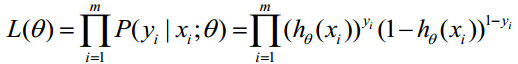
上式稱為n個觀測的似然函式。我們的目標是能夠求出使這一似然函式的值最大的引數估計。於是,最大似然估計的關鍵就是求出引數,使上式取得最大值。
對上述函式求對數:
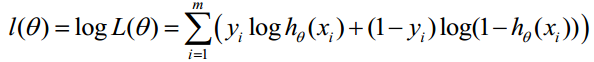
最大似然估計就是求使上式取最大值時的θ,這裡可以使用梯度上升法求解,求得的θ就是要求的最佳引數。在Andrew Ng的課程中將J(θ)取為下式,即:J(θ)=-(1/m)l(θ),J(θ)最小值時的θ則為要求的最佳引數。通過梯度下降法求最小值。θ的初始值可以全部為1.0,更新過程為:
(j表樣本第j個屬性,共n個;a表示步長--每次移動量大小,可自由指定)
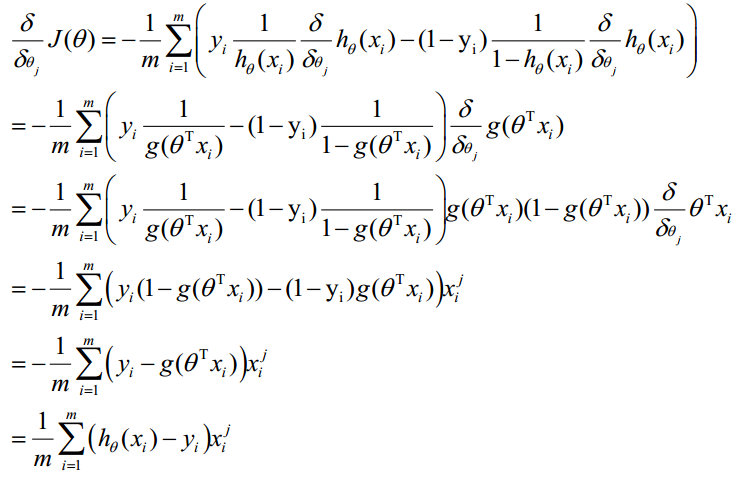
因此,θ(可以設初始值全部為1.0)的更新過程可以寫成:
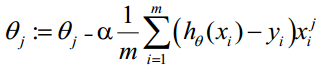
該公式將一直被迭代執行,直至達到收斂(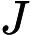
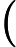
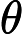
 在每一步迭代中都減小,如果某一步減少的值少於某個很小的值
在每一步迭代中都減小,如果某一步減少的值少於某個很小的值 ()(小於0.001), 則其判定收斂)或某個停止條件為止(比如迭代次數達到某個指定值或演算法達到某個可以允許的誤差範圍)。
()(小於0.001), 則其判定收斂)或某個停止條件為止(比如迭代次數達到某個指定值或演算法達到某個可以允許的誤差範圍)。
2,向量化Vectorization求解
Vectorization是使用矩陣計算來代替for迴圈,以簡化計算過程,提高效率。如上式,Σ(...)是一個求和的過程,顯然需要一個for語句迴圈m次,所以根本沒有完全的實現vectorization。下面介紹向量化的過程:
約定訓練資料的矩陣形式如下,x的每一行為一條訓練樣本,而每一列為不同的特稱取值:

g(A)的引數A為一列向量,所以實現g函式時要支援列向量作為引數,並返回列向量。由上式可知hθ(x)-y可由g(A)-y一次計算求得。
θ更新過程可以改為:
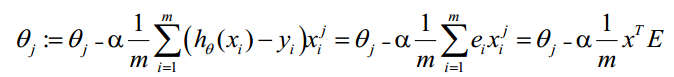
綜上所述,Vectorization後θ更新的步驟如下:
(1)求A=X*θ(此處為矩陣乘法,X是(m,n+1)維向量,θ是(n+1,1)維列向量,A就是(m,1)維向量)
(2)求E=g(A)-y(E、y是(m,1)維列向量)
(3)求 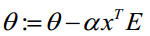
3,步長a的選擇
a的取值也是確保梯度下降收斂的關鍵點。值太小則收斂慢,值太大則不能保證迭代過程收斂(邁過了極小值)。要確保梯度下降演算法正確執行,需要保證 J(θ)在每一步迭代中都減小。如果步長a取值正確,那麼J(θ)應越來越小。所以a的取值判斷準則是:如果J(θ)變小了表明取值正確,否則減小a的值。
選擇步長a的經驗為:選取一個a值,每次約3倍於前一個數,如果迭代不能正常進行(J增大了,步長太大,邁過了碗底)則考慮使用更小的步長,如果收斂較慢則考慮增大步長,a取值示例如:
…, 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1…。
4,特徵值歸一化
Logistic 迴歸也是一種迴歸演算法,多維特徵的訓練資料進行迴歸採取梯度法求解時其特徵值必須做scale,確保特徵的取值範圍在相同的尺度內計算過程才會收斂(因為特徵值得取值範圍可能相差甚大,如特徵1取值為(1000-2000),特徵2取值為(0.1-0.2))。feature scaling的方法可自定義,常用的有:
1) mean normalization (or standardization)
(X - mean(X))/std(X),std(X)表示樣本的標準差
2) rescaling
(X - min) / (max - min)
5,演算法優化--隨機梯度法
梯度上升(下降)演算法在每次更新迴歸係數時都需要遍歷整個資料集, 該方法在處理100個左右的資料集時尚可,但如果有數十億樣本和成千上萬的特徵,那麼該方法的計算複雜度就太高了。一種改進方法是一次僅用一個樣本點來更新迴歸係數,該方法稱為隨機梯度演算法。由於可以在新樣本到來時對分類器進行增量式更新,它可以在新資料到來時就完成引數更新,而不需要重新讀取整個資料集來進行批處理運算,因而隨機梯度演算法是一個線上學習演算法。(與“線上學習”相對應,一次處理所有資料被稱作是“批處理”)。隨機梯度演算法與梯度演算法的效果相當,但具有更高的計算效率。
(三)Python實現Logistic迴歸演算法
上節通過Andrew Ng的課程對J(θ)=-(1/m)l(θ)採取梯度下降法求解說明了Logistic迴歸的求解過程,本節Python實現演算法的過程依然直接對J(θ)採取梯度上升法或者隨機梯度上升法求解,LRTrain物件同時實現了採取梯度上升法或者隨機梯度上升法求解過程。
LR分類器學習包中包含lr.py/object_json.py/test.py三個模組。lr模組通過物件logisticRegres實現了LR分類器,支援gradAscent('Grad') and randomGradAscent('randomGrad')兩種求解方法(二選一,classifierArray只儲存一種分類求解結果,當然你也可以定義兩個classifierArray同時支援兩種求解方法)。
test模組中是利用LR分類器根據疝氣病症預測病馬死亡率的應用。該資料存在一個問題--資料由30%的丟失率,這裡採用特殊值0替代,因為0不會影響LR分類器的權值更新。
訓練資料中樣本特徵值的部分缺失是很棘手的問題,很多文獻致力於解決該問題,因為資料直接丟掉太可惜,重新獲取代價也昂貴。一些可選的資料丟失處理方法包括:
□使用可用特徵的均值來填補缺失值;
□使用特殊值來±真補缺失值,如-1;
□忽略有缺失值的樣本;
□使用相似樣本的均值添補缺失值;
□使用另外的機器學習演算法預測缺失值。
LR分類器演算法學習包下載地址是:
(四)Logistic迴歸應用
Logistic迴歸的主要用途:
尋找危險因素:尋找某一疾病的危險因素等;
預測:根據模型,預測在不同的自變數情況下,發生某病或某種情況的概率有多大;
判別:實際上跟預測有些類似,也是根據模型,判斷某人屬於某病或屬於某種情況的概率有多大,也就是看一下這個人有多大的可能性是屬於某病。
Logistic迴歸主要在流行病學中應用較多,比較常用的情形是探索某疾病的危險因素,根據危險因素預測某疾病發生的概率,等等。例如,想探討胃癌發生的危險因素,可以選擇兩組人群,一組是胃癌組,一組是非胃癌組,兩組人群肯定有不同的體徵和生活方式等。這裡的因變數就是是否胃癌,即“是”或“否”,自變數就可以包括很多了,例如年齡、性別、飲食習慣、幽門螺桿菌感染等。自變數既可以是連續的,也可以是分類的。