
馬氏距離+協方差公式+無偏估計
以下資源均來自網際網路
馬氏距離與其推導
馬氏距離就是用於度量兩個座標點之間的距離關係,表示資料的協方差距離。與尺度無關的(scale-invariant),即獨立於測量尺度。
基本思想(intuition)
如下圖的過程(以兩個維度作為例子),此例的資料重心為原點,P1,P2到原點的歐氏距離相同,但點P2在y軸上相對原點有較大的變異,而點P1在x軸上相對原點有較小的變異。所以P1點距原點的直觀距離是比P2點的小的。
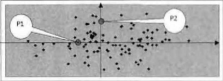
馬氏距離就是解決這個問題,它將直觀距離和歐式距離統一。它先將資料不同維度上的方差統一(即各維度上的方差相同),此時的歐式距離就是直觀距離

如圖:統一方差後的圖,P1到原點的距離小於P2。P1’到原點的歐式距離和P2的相同。以上所說的直觀距離就是馬氏距離
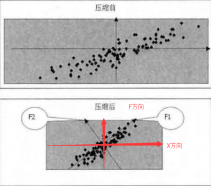
所以在F1方向和F2方向上壓縮資料才能達到較好的效果。所以需要將原始的在X座標系中的座標表示在F座標系中。然後再分別沿著座標軸壓縮資料。
所以,計算樣本資料的馬氏距離分為兩個步驟:
1. 座標旋轉
2. 資料壓縮
座標旋轉的目標:使旋轉後的各個維度之間線性無關,所以該旋轉過程就是主成分分析的過程。
資料壓縮的目標:所以將不同的維度上的資料壓縮成為方差都是1的的資料集。
推導過程
有一個原始的多維樣本資料Xn×mXn×m(m列,n行):

其中每一行表示一個測試樣本(共n個);
Xi表示樣本的第i個維度(共m個)
其協方差為:
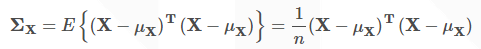
協方差矩陣是在具有一組樣本後,表示資料的各維度之間的關係的。其中n是樣本的數量
假設將原始資料集X通過座標旋轉矩陣U旋轉到新的座標系統中得到一個新的資料集F。(其實X和F表示的是同一組樣本資料集,只是由於其座標值不同,為了易於區分用了兩個字母表示)
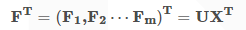
新資料集F的均值記為
由於將資料集旋轉後資料的各維度之間是不相關的,所以新資料集F的協方差矩陣
由於:
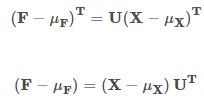
所以:
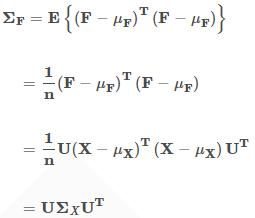
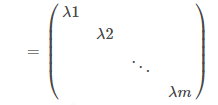
每個
由於
以上是準備知識,下面推導一個樣本點x=(x1,x2⋯xm)到重心μX=(μX1,μX2⋯μXm)的馬氏距離。等價於求點f=(f1,f2⋯fm)壓縮後的座標值到資料重心壓縮後的座標值μF=(μF1,μF2⋯μFm)的歐式距離。
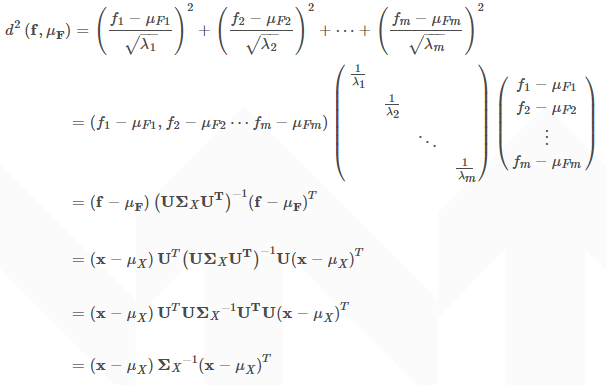
這就是馬氏距離的的計算公式了。
如果x是列向量
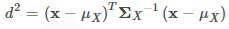
如果並把上文的重心點
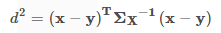
以上來自這裡
協方差公式
統計學的基本概念
學過概率統計的孩子都知道,統計裡最基本的概念就是樣本的均值,方差,或者再加個標準差。首先我們給你一個含有n個樣本的集合X={X1,…,Xn},依次給出這些概念的公式描述,這些高中學過數學的孩子都應該知道吧,一帶而過。
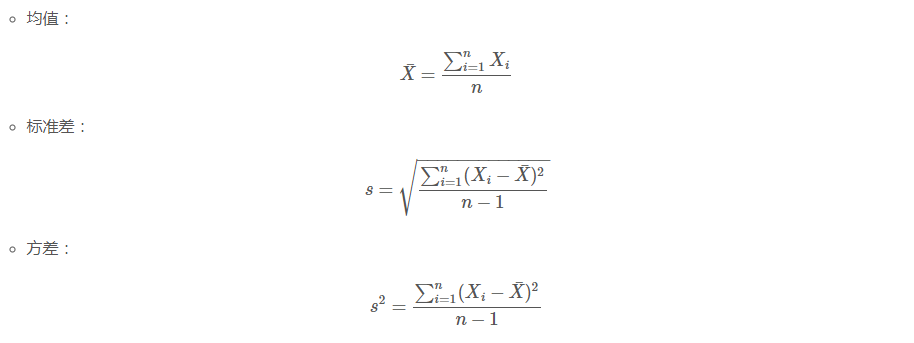
很顯然,均值描述的是樣本集合的中間點,它告訴我們的資訊是很有限的,而標準差給我們描述的則是樣本集合的各個樣本點到均值的距離之平均。以這兩個集合為例,[0,8,12,20]和[8,9,11,12],兩個集合的均值都是10,但顯然兩個集合差別是很大的,計算兩者的標準差,前者是8.3,後者是1.8,顯然後者較為集中,故其標準差小一些,標準差描述的就是這種“散佈度”。之所以除以n-1而不是除以n,是因為這樣能使我們以較小的樣本集更好的逼近總體的標準差,即統計上所謂的“無偏估計”。而方差則僅僅是標準差的平方。
為什麼需要協方差?
面幾個統計量看似已經描述的差不多了,但我們應該注意到,標準差和方差一般是用來描述一維資料的,但現實生活我們常常遇到含有多維資料的資料集,最簡單的大家上學時免不了要統計多個學科的考試成績。面對這樣的資料集,我們當然可以按照每一維獨立的計算其方差,但是通常我們還想了解更多,比如,一個男孩子的猥瑣程度跟他受女孩子歡迎程度是否存在一些聯絡啊,嘿嘿~協方差就是這樣一種用來度量兩個隨機變數關係的統計量,我們可以仿照方差的定義:
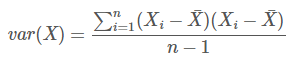
來度量各個維度偏離其均值的程度,標準差可以這麼來定義:
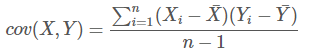
協方差的結果有什麼意義呢?如果結果為正值,則說明兩者是正相關的(從協方差可以引出“相關係數”的定義),也就是說一個人越猥瑣就越受女孩子歡迎,嘿嘿,那必須的~結果為負值就說明負相關的,越猥瑣女孩子越討厭,可能嗎?如果為0,也是就是統計上說的“相互獨立”。
從協方差的定義上我們也可以看出一些顯而易見的性質,如:
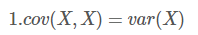

協方差多了就是協方差矩陣
上一節提到的猥瑣和受歡迎的問題是典型二維問題,而協方差也只能處理二維問題,那維數多了自然就需要計算多個協方差,比如n維的資料集就需要計算
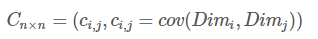
這個定義還是很容易理解的,我們可以舉一個簡單的三維的例子,假設資料集有{x,y,z}{x,y,z}三個維度,則協方差矩陣為:
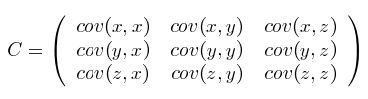
可見,協方差矩陣是一個對稱的矩陣,而且對角線是各個維度上的方差。
Matlab協方差實戰
上面涉及的內容都比較容易,協方差矩陣似乎也很簡單,但實戰起來就很容易讓人迷茫了。必須要明確一點,### 協方差矩陣計算的是不同維度之間的協方差,而不是不同樣本之間的。這個我將結合下面的例子說明,以下的演示將使用Matlab,為了說明計算原理,不直接呼叫Matlab的cov函式。
首先,隨機產生一個10*3維的整數矩陣作為樣本集,10為樣本的個數,3為樣本的維數。
MySample = fix(rand(10,3)*50)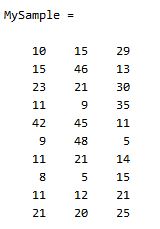
根據公式,計算協方差需要計算均值,那是按行計算均值還是按列呢,我一開始就老是困擾這個問題。前面我們也特別強調了,協方差矩陣是計算不同維度間的協方差,要時刻牢記這一點。樣本矩陣的每行是一個樣本,每列為一個維度,所以我們要### 按列計算均值。為了描述方便,我們先將三個維度的資料分別賦值:
dim1 = MySample(:,1);
dim2 = MySample(:,2);
dim3 = MySample(:,3);計算dim1與dim2,dim1與dim3,dim2與dim3的協方差:
sum( (dim1-mean(dim1)) .* (dim2-mean(dim2)) ) / ( size(MySample,1)-1 ) % 得到 74.5333
sum( (dim1-mean(dim1)) .* (dim3-mean(dim3)) ) / ( size(MySample,1)-1 ) % 得到 -10.0889
sum( (dim2-mean(dim2)) .* (dim3-mean(dim3)) ) / ( size(MySample,1)-1 ) % 得到 -106.4000搞清楚了這個後面就容易多了,協方差矩陣的對角線就是各個維度上的方差,下面我們依次計算:
std(dim1)^2 % 得到 108.3222
std(dim2)^2 % 得到 260.6222
std(dim3)^2 % 得到 94.1778這樣,我們就得到了計算協方差矩陣所需要的所有資料,呼叫Matlab自帶的cov函式進行驗證:
cov(MySample)
把我們計算的資料對號入座,是不是一摸一樣?
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Update:今天突然發現,原來協方差矩陣還可以這樣計算,先讓樣本矩陣中心化,即每一維度減去該維度的均值,使每一維度上的均值為0,然後直接用新的到的樣本矩陣乘上它的轉置,然後除以(N-1)即可。其實這種方法也是由前面的公式通道而來,只不過理解起來不是很直觀,但在抽象的公式推導時還是很常用的!同樣給出Matlab程式碼實現:
···
X = MySample - repmat(mean(MySample),10,1); % 中心化樣本矩陣,使各維度均值為0
C = (X’*X)./(size(X,1)-1);
···
總結
理解協方差矩陣的關鍵就在於牢記它計算的是不同維度之間的協方差,而不是不同樣本之間,拿到一個樣本矩陣,我們最先要明確的就是一行是一個樣本還是一個維度,心中明確這個整個計算過程就會順流而下,這麼一來就不會迷茫了~
以上來自這裡