
Kafka理論概述和應用場景
1.Kafka概述
Kafka是一種高吞吐量的分散式釋出訂閱訊息系統,它可以處理消費者規模的網站中的所有動作流資料。簡單地說,Kafka就相比是一個郵箱,生產者是傳送郵件的人,消費者是接收郵件的人,Kafka就是用來存東西的,只不過它提供了一些處理郵件的機制。
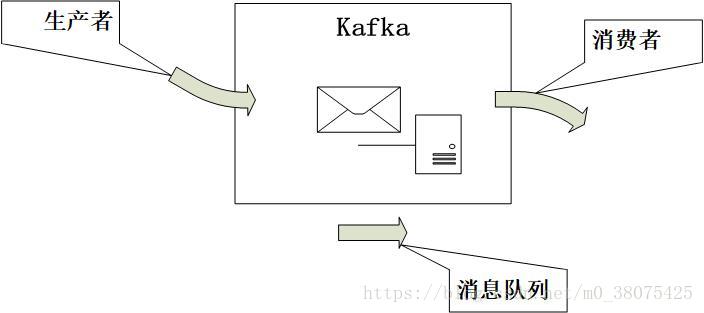
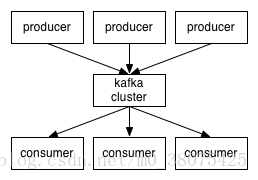
2.Kafka相關名詞分析
- Broker:Kafka節點,一個Kafka節點就是一個broker,多個broker可以組成一個Kafka叢集
- Topic:一類訊息,訊息存放的目錄即主題,例如page view日誌、click日誌等都可以以topic的形式存在,Kafka叢集能夠同時負責多個topic的分發
- massage: Kafka中最基本的傳遞物件。
- Partition:topic物理上的分組,一個topic可以分為多個partition,每個partition是一個有序的佇列
- Segment:partition物理上由多個segment組成,每個Segment存著message資訊
- Producer : 生產者,生產message傳送到topic
- Consumer : 消費者,訂閱topic並消費message, consumer作為一個執行緒來消費
- Consumer Group:消費者組,一個Consumer Group包含多個consumer
- Offset:偏移量,理解為訊息partition中的索引即可
下面做進一步說明:
broker即kafka程式,kafka程式運行於zookeeper之上,zookeeper是一個分散式的,分散式應用程式的協調服務,其提供的功能包括:配置維護、域名服務、分散式同步、組服務等。在此處,zookeeper協調kafka節點的配置、同步操作等。
topic即主題,kafka中釋出訊息、訂閱訊息的物件是topic。我們可以為每類資料建立一個topic。一個topic中的訊息資料按照多個partition組織,分割槽是kafka訊息佇列組織的最小單位(並不是物理上的最小單位),一個分割槽可以看作是一個FIFO( First Input First Output的縮寫,先進先出佇列)的佇列。如下圖:
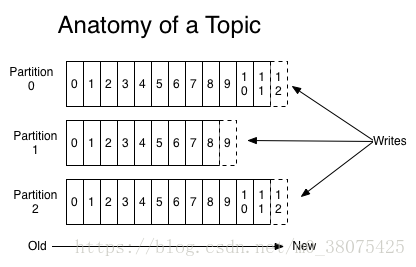
例如,在上圖中,一個topic被分成了3個分割槽(即partition0~2),使用者釋出message時,可以指定message所處topic的partition,如果沒有指定,則隨機分佈到該topic的partition。釋出的訊息(其實是邏輯日誌)將在partition尾部插入。
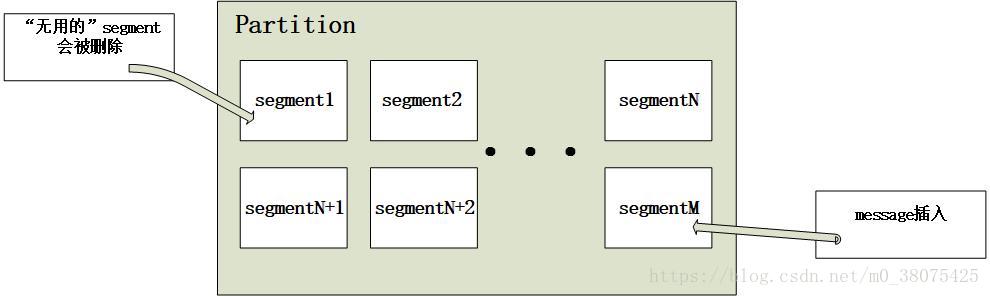
segment是partition的物理儲存單元,kafka收到message後,會向對應partition的最後一個segment上新增該訊息,當某個segment上的訊息條數達到配置值或訊息釋出時間超過閾值時,segment上的訊息會被儲存到磁碟,只有被儲存到磁碟上的訊息consumer才能消費,segment達到一定的大小後將不會再往該segment寫資料,kafka會建立新的segment。其實,每個partition相當於分配到多個大小相等segment資料檔案中。但每個segment訊息數量不一定相等,這種特性方便無用的segment快速被刪除,segment檔案生命週期由服務端配置引數決定。如下圖:
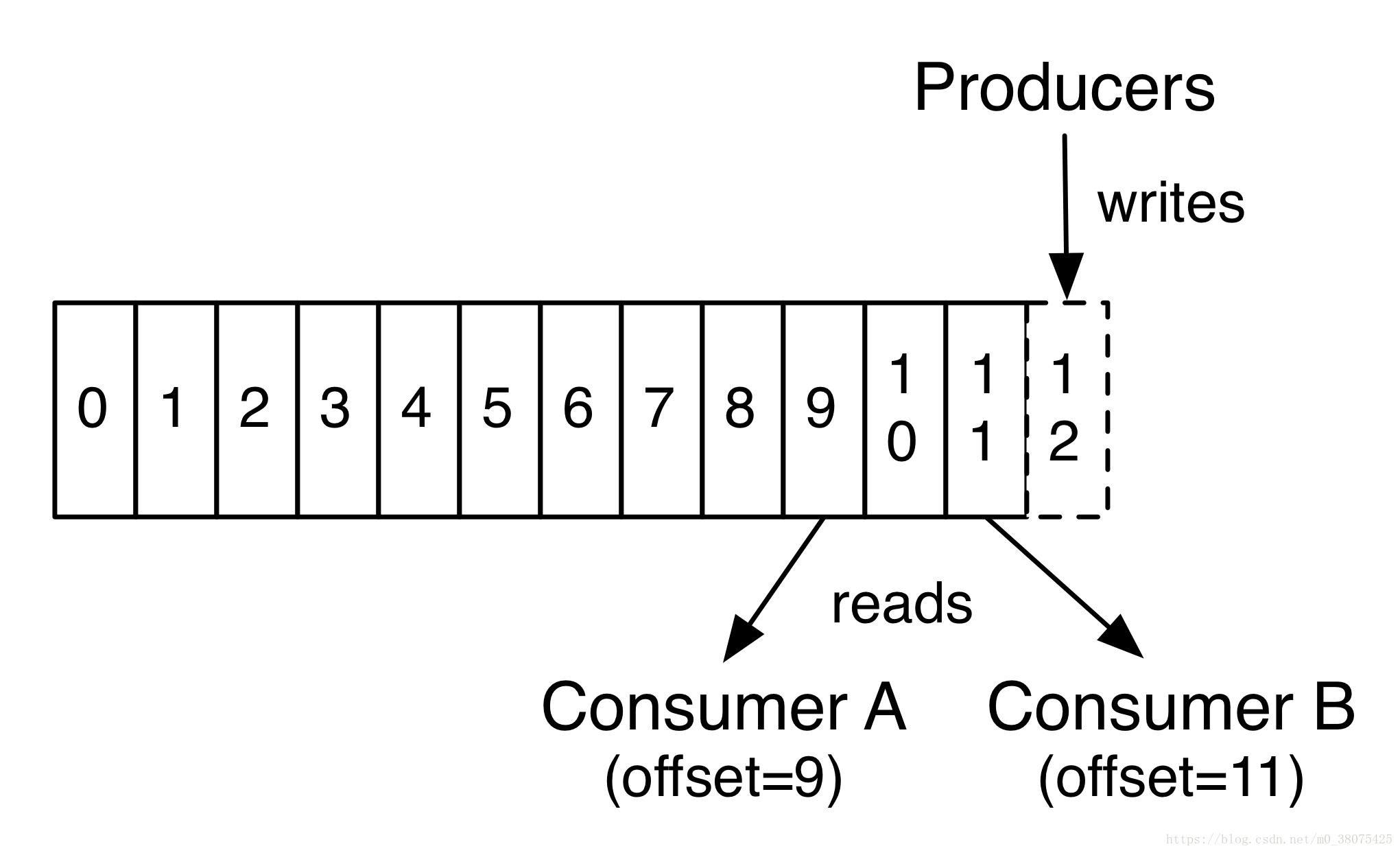
consumer和consumer group,一個consumer group包含多個consumer,使用者可以指定consumer的group。各個consumer可以組成一個group,partition中的每個message只能被一個group中的一個consumer消費,如果一個message想要被多個consumer消費的話,那麼這些consumer必須在不同的group。kafka不支援一個partition中的message同時由兩個或兩個以上的consumer thread來處理,即便是來自不同的consumer group的也不行。kafka為了保證吞吐量,只允許一個consumer去訪問一個partition。如果覺得效率不高,可以加partition的數量來橫向擴充套件,再加新的consumer去消費,充分發揮了橫向的擴充套件性,吞吐量極高。這也就形成了分散式消費的概念。如下圖:
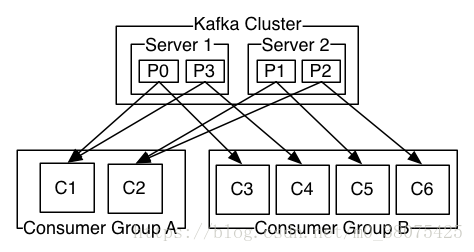
上圖中有兩個伺服器的kafka群集,它們有四個分割槽(P0-P3),其中有兩個group。group A有兩個消費者,group B有四個消費者。P0如果被C1消費後,則C2不能再消費,但是group B的C3或者其它的一個可以消費P0。
3.Kafka的優勢
- 高吞吐量、低延遲:kafka每秒可以處理幾十萬條訊息,它的延遲最低只有幾毫秒
- 可擴充套件性:kafka叢集支援熱擴充套件
- 永續性、可靠性:訊息被持久化到本地磁碟,並且支援資料備份防止資料丟失
- 容錯性:允許叢集中節點故障(若副本數量為n,則允許n-1個節點故障)
- 高併發:支援數千個客戶端同時讀寫
4.Kafka應用場景
- 日誌收集:一個公司可以用Kafka可以收集各種服務的log,通過kafka以統一介面服務的方式開放給各種consumer
- 訊息系統:解耦生產者和消費者、快取訊息等
- 使用者活動跟蹤:kafka經常被用來記錄web使用者或者app使用者的各種活動,如瀏覽網頁、搜尋、點選等活動,這些活動資訊被各個伺服器釋出到kafka的topic中,然後消費者通過訂閱這些topic來做實時的監控分析,亦可儲存到資料庫
- 運營指標:kafka也經常用來記錄運營監控資料。包括收集各種分散式應用的資料,生產各種操作的集中反饋,比如報警和報告
- 流式處理:比如spark streaming和storm;