
Week 9:Anomaly Detection課後習題解答
大家好,我是Mac Jiang,今天和大家分享Coursera-Stanford University-Machine Learning-Week 8:Anomaly Detection的課後習題解答。注意:每個同學的習題的引數和選項都是不同的,在參考時不要照抄,避免帶來錯誤!我的分析也不一定是正確的,如果各位博友發現錯誤,請留言聯絡,謝謝。希望我的部落格能給你帶來一些學習上的幫助!
1.第一題

(1)題意:異常檢測演算法適合解決下列哪些問題?
1.給定一張人臉圖片,辨別他是不是一個名人
2.從大量初級保健病人記錄,確定誰可能有不正常的健康問題
3.從信用卡交易中得到的資料,按購買型別進行分類(食品,運輸,服裝)
4.從信用卡的交易資料中,確定不正常的交易,因此我們可以確定它們是不是被盜刷了
(2)分析:異常檢測是從大量正確的樣本中找出明顯偏離的錯誤樣本,絕大多數的樣本都是正確的,是一個偏斜類。而有監督學習的各種類別的樣本數都較多,一般不是偏斜類。
1.錯誤。名人也是人,名人並不是錯誤樣本,而且名人非常多,不能說每個名人都是錯誤的吧
2.正確。這些保健人群大多數是健康人,很少是有不正常的健康問題,這些不健康的就是異常點,可以用異常檢測
3.錯誤。這顯然是有監督學習裡的分類
4.正確。信用卡的絕大部分資料都是本人使用時產生的,如果被盜刷,則這個資料很可能偏離本人使用習慣,及產生異常。
(3)答案:2,4
2.第二題

(1)題意:你訓練了一個異常檢測系統,當p(x)的值小於ipsilon,當你利用驗證樣本驗證時發現,出現太多錯誤的0(1表示異常,0表示正常。太多錯誤的0就是說很多異常的被錯誤的認為是正常的),我們應該怎麼辦?
1.增大ipsilon
2.減小ipsilon
(2)分析:太多的異常點未被標為異常,說明ipsilon太小了,應該增大
(3)答案:1
3.第三題

(1)題意:你在利用異常檢測系統來測試飛機引擎,你用的模型如上面公式。你有兩個特徵,x1是發動機的震動強度,x2是發動機的發熱狀況,x1和x2取值都在0-1之間。正常的引擎的x1約等於x2。常見的一種異常是傳送機震動得非常快但是不會產生大量熱(x1很大,x2很小),而此時x1和x2的值卻都在0-1內,並未超過這個範圍。如果你要建立一個特徵來解決這個問題,你選擇哪個?
(2)分析:現在的異常情況是傳送機震動的非常快,但是產熱很少,及x1很大,x2很小。
1.x3 = 1/x2。錯誤,因為有的發動機產熱和他一樣低,但是震動很慢,他是正常的,不能和此異常區別
2.x3 = 1/x1。錯誤,因為有的發動機震動速度和他一樣快,但是產熱高,利用這個不能區別。
3.x3 = x1 + x2。錯誤,完全有發動機震動一般快,發熱一般多,但兩者之和與這個異常發動機一樣。
4.x3 = x1/x2。正確
(3)答案:4
4.第四題

(1)題意:選出所有正確的陳述
1.如果你的所有資料被歸為y=0類,此時仍然能學習異常檢測函式p(x),但是如何評價這個系統,或選擇好的ipsilon將成為一個問題
2.當為異常檢測系統選擇特徵時,尋找異常大或者異常小的特徵是一個好辦法
3.如果有大量正樣本的大量負樣本,異常檢測演算法和有監督學習演算法(如SVM)的表現一樣好
4.如果你在開發一個異常檢測系統,沒有辦法利用標記的資料來改進你的系統
(2)分析:1.正確。在訓練異常檢測系統時用的一般是全部正常的資料,及y=0,但是任然可以建立系統。只是在驗證時需要一些異常樣本,用於確定ipsilon的大小
2.正確,異常的或異常小的特徵可以幫助樣本脫離正常區域,方便分類進行
3.錯誤,異常檢測適合處理的是絕大多數樣本是正常,少數樣本是異常的偏斜類,而有監督學習適合處理的是兩者都有相當數量的資料
4.錯誤,比如你可以用標記為異常的樣本y=1來尋找最優的ipsolon
(3)答案:1,2
5.第五題
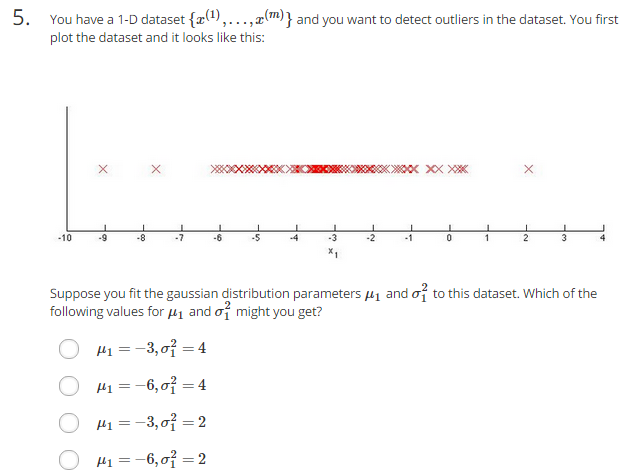
(1)題意:有一位資料集{x(1)…x(m)},你想檢測裡面的離群值,做出上圖所示的圖形。假設你用高斯分佈你和他,則mu1和sigma^2分別為什麼
(2)分析:可以發現最密的地方在-3左右,mu為-3;至於sigma^2博主真的是無能為力了,不知道怎麼算。不過以前學過,正太分佈在[u-sigma,u+sigma]範圍內的概率為68%左右,不知道對這道題有沒有幫助。
(3)答案:博主親測,答案選1