
筆記(總結)-序列標註問題與求解
在講述了大量的概率圖模型後,本篇介紹下它發揮作用的主要場景——序列標註(Sequence Labaling)。序列包括時間序列以及general sequence,但兩者無異。連續的序列在分析時也會先離散化處理。常見的序列有如:時序資料、本文句子、語音資料、等等。常見的序列問題有:
- 擬合、預測未來節點(走勢分析,如股票預測、銷量預測等)
- 判定序列所屬類別,即分類問題(如語音識別,判斷聲音序列所屬來源)
- 判定序列中各個節點的類別,即序列標註問題
我們討論的是序列標註問題。可以看到,常見的機器學習演算法,無論是分類還是迴歸,都是給定了一個處理物件,然後給定一個整體的標籤。而序列標註問題是針對一個處理物件(即序列)對其中的各個部分貼標籤,這在處理思路上是完全不同的。傳統的序列標註問題主要是用概率圖模型求解,而近年來,隨著深度學習的發展,適用於序列問題建模的RNN類模型大放異彩。本篇將介紹概率圖和RNN-Based的兩大類模型。
NLP中的序列標註問題
自然語言處理中,由於主要處理物件是語言,在以句子為單位進行處理時,很自然的就對應到了狀態圖。句子中不同的“詞”(其實是句子中基本元素,可能是詞、字或其它語素)就對應著序列的各個節點。句子中各個“詞”的出現時有先後關係的,正如說話的過程有的話先說出來有的後說處理,因此這種序列又天然的可以用時間作為序列的測度。所以NLP中的問題通常建模為時間序列問題。許多NLP問題都可以轉化為序列標註問題,常見的如:
- 中文分詞(Chinese Word Segmentation):將給定句子切分為具有合理語義的詞序列。在分詞問題中,序列節點的“詞”對應為句子中的每個字,節點的標籤空間為{B,I,E,S}。B表示這個字是某個詞的開頭,I表示這個字是某個詞的中間部分,E表示這個字是某個詞的結尾,S表示這個字單獨成詞。每個字最終都會打上對應標籤,最終根據標籤序列來確定分詞結果。
- 詞性標註(Part-of-Speech Tagging):給定已分詞的句子,將句子中的所有詞標記詞性。這裡的“詞”對應的就是已分詞的詞序列中的詞,節點的標籤空間為詞性標記空間如{noun,verb,adj,…}。每個詞最終都會打上詞性標籤。
- 命名實體識別(Named Entity Recognition):找出給定句子中的命名實體(常見的有人名、地名、機構名)。NER問題中,序列節點的“詞”對應為句子中的每個字,節點的標籤空間為{B,I,E,O}。B表示這個字是某個命名實體的開頭,I表示這個字是某個命名實體的中間部分,E表示這個字是某個命名實體的結尾,O表示這個字不屬於命名實體部分。根據最後的標籤序列確定識別結果。
- ……
概率圖模型
由於之前已經比較詳細地講解了各個概率圖模型的原理,在此只簡要描述問題解決過程。
給定隱馬爾科夫模型HMM,序列標註問題對應於HMM中的解碼問題,即給定觀測序列的基礎上,如何求隱狀態序列。“詞”對應的是序列節點,標籤對應的是隱狀態節點。使用Viterbi演算法進行求解,找到概率最大的標籤序列作為結果即可。
順帶一提。HMM中的評估問題,即給定觀測序列求其出現的概率,可以對應到是我們上面講的序列分類問題上。比如語音識別問題,給定音訊序列,如何判斷是人發出的聲音還是狗發出的聲音?我們利用人發聲的樣本集A和狗發聲的樣本集B分別訓練得到兩個HMM,。針對一條新的樣本,分別代入兩個模型中計算,比較計算出的概率大小,劃定為概率較高的模型對應建模類別即可。
給定最大熵模型(雖然最大熵模型不屬於概率圖模型的範疇,但按照之前講解的順序還是提一下),最大熵模型利用條件概率直接對標籤空間建模。由於最大熵模型基於特徵函式,所以在樣本構建時,除了原始序列節點外還需要加入每個節點的相關特徵。在求解時,最優標籤序列為,注意這裡的不再是單個標籤,而是一個標籤序列,這是理解概率圖建模的關鍵。
給定最大熵馬爾可夫模型MEMM,與最大熵模型相同,也是利用條件概率建模,但條件概率的求解中引入了狀態的概念。分解為每個狀態概率的連乘,每個狀態都用一個最大熵模型建模。求解的邏輯與最大熵模型是類似的。
給定條件隨機場CRF,序列標註問題對應於CRF中的解碼問題。CRF也是基於狀態,利用特徵函式,在全域性範圍內進行概率歸一。CRF由於使用了特徵函式,使得其能夠挖掘觀測序列之間的關係,解決了輸出獨立性問題;由於使用了全域性範圍內的概率歸一,解決了MEMM的標註偏置問題。求解的邏輯與HMM是類似的,也是使用Viterbi演算法求解。
可以看到,CRF綜合了HMM、最大熵模型、MEMM的優點,同時解決了它們各自具有的問題,在演算法設計是概率圖模型中最完備的。實際使用中,序列標註問題上CRF也是概率圖模型中效果最好的。
RNN-Based模型
迴圈神經網路之前也做過總結,下圖中,對齊的many-to-many網路架構(最後一個)能夠很好的對應到序列標註問題:
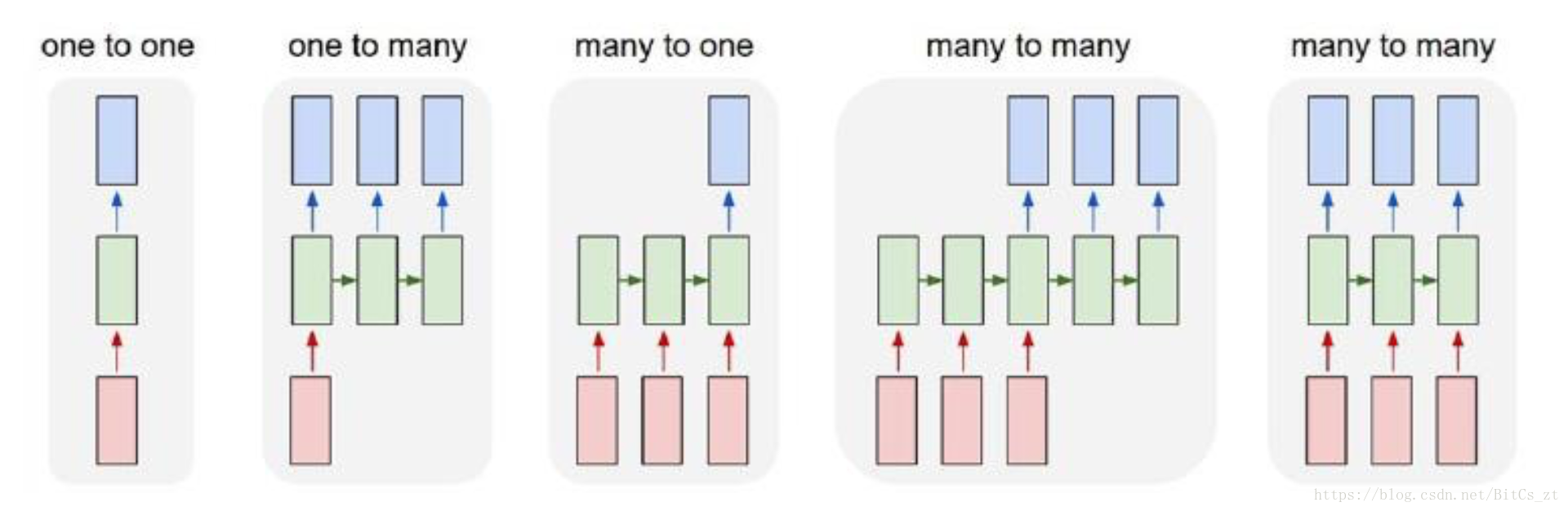
其中,紅色的block是輸入對應的是待標註的序列,綠色的block是核心網路負責進行特徵表示的學習,藍色的block是標籤解碼層負責輸出對應的標註。核心網路是設計的重點,一般採用的Bidirectional-RNN,雙向建模序列能融合上下文的特徵。NN模型的優勢是通過巨大的引數空間來擬合非線性的關係,但注意到,NN模型的輸出也是獨立的,這就導致會出現一些不合理的標籤序列。比如在分詞模型中,出現”B,B”之類的標籤段,而這是不合理的標籤。
Bi-RNN+CRF
由於RNN-Based模型存在輸出獨立性問題,我們考慮改進網路結構。參考概率圖模型中的最優代表CRF,它通過定義兩類特徵函式,關聯起了前後的隱狀態和觀測序列。如何將CRF的思想引入神經網路?我們考慮將Bi-RNN得到的表示特徵作為觀測序列,在輸出層(觀測序列)上新增一層神經元模擬CRF中隱狀態,架構圖如下(命名實體識別任務):
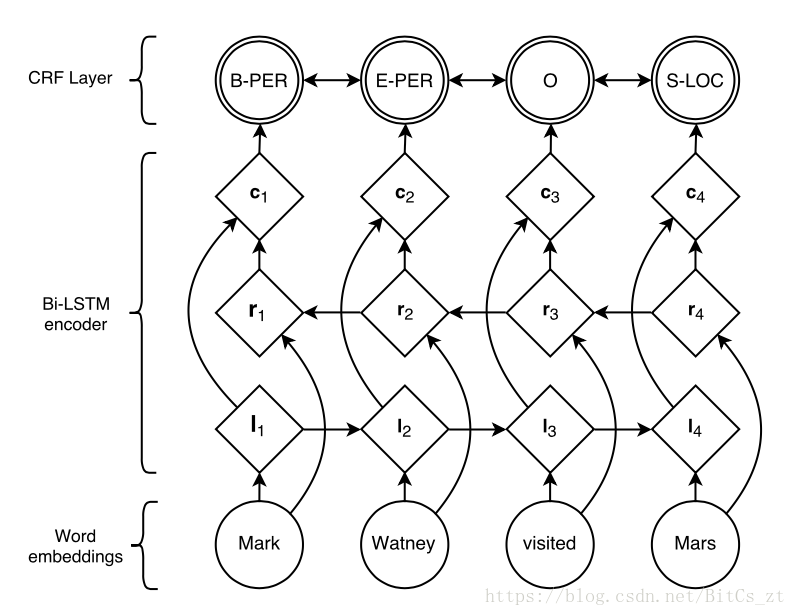
可以看到網路架構是三部分,詞向量轉化、Bi-RNN特徵提取層、CRF層。特徵提取層最終輸出為,把它作為CRF的觀測序列。接下來定義CRF的特徵函式。類似於HMM,定義狀態轉移打分矩陣和狀態觀測值打分矩陣,其中表示從隱狀態轉換到隱狀態的打分,表示觀測值在隱狀態下的打分。注意,這裡的矩陣並不是概率矩陣,因此沒有歸一化計算。基於這兩個矩陣,構造打分函式來模擬CRF的特徵函式的打分求和:
原始的Bi-RNN模型最終的輸出是一個向量,向量元素表示各類標籤的打分。我們只需要把每個節點的輸出向量合併起來,就得到了矩陣。對應到上述模型架構中,我們只需要將特徵對映為一個輸出向量,然後拼接起來就得到了。所以在上述打分函式中,實際上指的就是,代表的是序列在位置的觀測值。而矩陣則建模了標籤之間轉換的合理性,即可以避免”B,B”這種標籤段的出現,解決了輸出獨立的問題。基於上式的條件概率定義如下:
訓練過程的優化目標為:
採用梯度下降法進行BP訓練,更新包括在內的引數。在預測過程中,前饋計算得到,則標籤序列為: