
對混淆矩陣、F1-Score、ROC曲線、AUC和KS曲線的理解
阿新 • • 發佈:2019-02-18
(一)混淆矩陣
混淆矩陣是除了ROC曲線和AUC之外的另一個判斷分類好壞程度的方法。下面給出二分類的混淆矩陣
| Predicted as Positive | Predicted as Negative | |
| Labeled as Positive | True Positive(TP) | False Negative(FN) |
| Labeled as Negative | False Positive(FP) | True Negative(TN) |
* 真正(True Positive, TP):被模型分類正確的正樣本;
* 假負(False Negative, FN):被模型分類錯誤的正樣本;
* 假正(False Positive, FP):被模型分類錯誤的負樣本;
* 真負(True Negative, TN):被模型分類正確的負樣本;
進一步可以推出這些指標:
* 真正率(True Positive Rate, TPR),又名靈敏度(Sensitivity):分類正確的正樣本個數佔整個正樣本個數的比例,即:
* 假負率(False Negative Rate, FNR):分類錯誤的正樣本的個數佔正樣本的個數的比例,即:
* 假正率(False Positive Rate, FPR):分類錯誤的負樣本個數佔整個負樣本個數的比例,即:
* 真負率(True Negative Rate, TNR):分類正確的負樣本的個數佔負樣本的個數的比例,即:
進一步,由混淆矩陣可以計算以下評價指標:
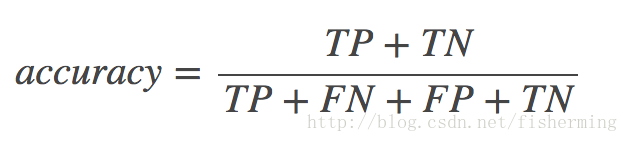
* 平均準確率(Average per-class accuracy):每個類別下的準確率的算術平均,即:
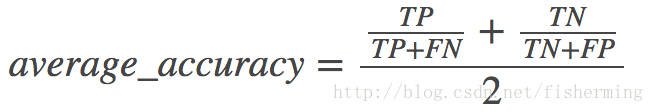
* 精確率(Precision):分類正確的正樣本個數佔分類器分成的所有正樣本個數的比例(注意:精確率和準確率不同),即:
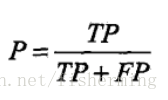
* 召回率(Recall):分類正確的正樣本個數佔正樣本個數的比例,即:
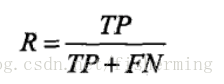
(二) F1-Score
在介紹F1-Score之前,首先介紹調和平均值,調和平均值為:總體各統計量的倒數的算術平均數的倒數;
F1值為精確率和召回率的調和均值。

例如:某工廠購進材料三批,每批價格及採購金額資料如下表:
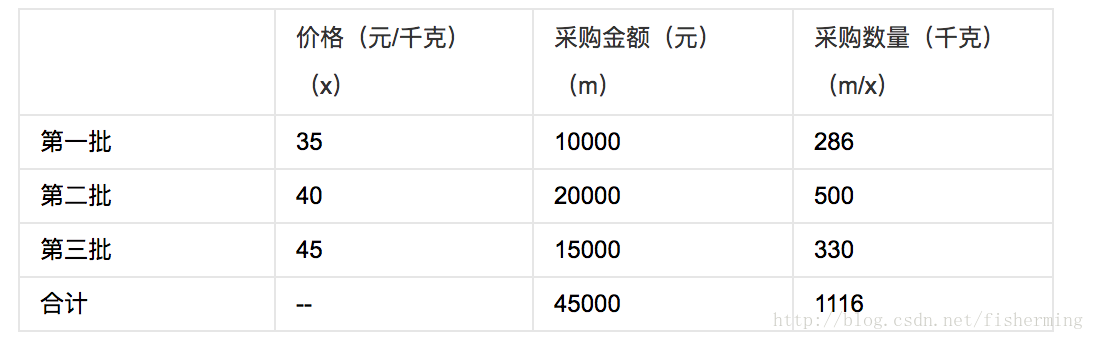
那麼調和平均值為: 