
混淆矩陣、精度precision、召回率recall、準確率accuracy、F1值
混淆矩陣
True Positive(真正,TP):將正類預測為正類數
True Negative(真負,TN):將負類預測為負類數
False Positive(假正,FP):將負類預測為正類數誤報 (Type I error)
False Negative(假負,FN):將正類預測為負類數→漏報 (Type II error)
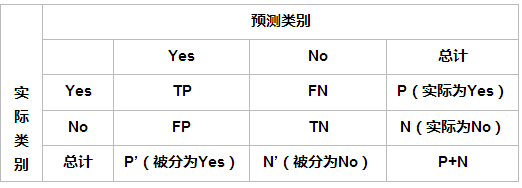
精度
表示被分為正例的示例中實際為正例的比例
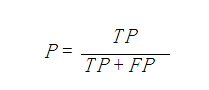
召回率
度量有多個正例被分為正例
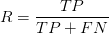
準確率
F1
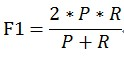
F
相關推薦
【機器學習-西瓜書】二、效能度量:召回率;P-R曲線;F1值;ROC;AUC
關鍵詞:準確率(查準率,precision);召回率(查全率,recall);P-R曲線,平衡點(Break-Even Point, BEP);F1值,F值;ROC(Receiver Operating Characteristic,受試者工作特徵);AUC(A
準確率accuracy、精確率precision和召回率recall
cal rac ive precision bsp trie true ron 所有 準確率:在所有樣本中,準確分類的數目所占的比例。(分對的正和分對的負占總樣本的比例) 精確率:分類為正確的樣本數,占所有被分類為正確的樣本數的比例。(分為正的中,分對的有多少) 召回率:分
二元分類中精確度precision和召回率recall的理解
精確度(precision) 是二元分類問題中一個常用的指標。二元分類問題中的目標類 別隻有兩個可能的取值, 而不是多個取值,其中一個類代表正,另一類代表負,精確度就 是被標記為“正”而且確實是“正”的樣本佔所有標記為“正”的樣本的比例。和精確度 一起出現的還有另一個指標召回率(r
準確率(accuracy),精確率(Precision)和召回率(Recall),AP,mAP的概念
先假定一個具體場景作為例子。假如某個班級有男生80人,女生20人,共計100人.目標是找出所有女生. 某人挑選出50個人,其中20人是女生,另外還錯誤的把30個男生也當作女生挑選出來了. 作為評估者的你需要來評估(evaluation)下他的工作 首先我們可以計算準確率(accuracy),其定
混淆矩陣、精度precision、召回率recall、準確率accuracy、F1值
混淆矩陣 True Positive(真正,TP):將正類預測為正類數 True Negative(真負,TN):將負類預測為負類數 False Positive(假正,FP):將負類預測為正類數誤報
推薦系統評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)
mda 統計 混雜 分類 sha 指標 lock 網頁 log 下面簡單列舉幾種常用的推薦系統評測指標: 1、準確率與召回率(Precision & Recall) 準確率和召回率是廣泛用於信息檢索和統計學分類領域的兩個度量值,用來評價結果的質量。其中精度是
系統評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)
綜合 gho 評估 static 指標 href net rec 出現 轉自:http://bookshadow.com/weblog/2014/06/10/precision-recall-f-measure/ 1、準確率與召回率(Precision & Reca
機器學習和推薦系統中的評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)簡介
模型 可擴展性 決策樹 balance rman bsp 理解 多個 缺失值 數據挖掘、機器學習和推薦系統中的評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)簡介。 引言: 在機器學習、數據挖掘、推薦系統完成建模之後,需要對模型的
機器學習演算法中的準確率(Precision)、召回率(Recall)、F值(F-Measure)
資料探勘、機器學習和推薦系統中的評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)簡介。 在機器學習、資料探勘、推薦系統完成建模之後,需要對模型的效果做評價。 業內目前常常採用的評價指標有準確率(Precision)、召回率(Recall)、F值(F-
效能度量:準確率(Precision)、召回率(Recall)、F值(F-Measure);P-R曲線;ROC;AUC
reference:https://blog.csdn.net/qq_29462849/article/details/81053135 資料探勘、機器學習和推薦系統中的評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)簡介。
Python3寫精確率(precision)、召回率(recall)以及F1分數(F1_Score)
1. 四個概念定義:TP、FP、TN、FN 先看四個概念定義: - TP,True Positive - FP,False Positive - TN,True Negative - FN,False Negative 如何理解記憶這四個概念定
推薦系統評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)_DM
下面簡單列舉幾種常用的推薦系統評測指標: 1、準確率與召回率(Precision & Recall) 準確率和召回率是廣泛用於資訊檢索和統計學分類領域的兩個度量值,用來評價結果的質量。其中精度是檢索出相關文件數與檢索出的文件總數的比率,衡量的是檢索系統的查準率;召
分類精度評價:混淆矩陣+總體精度OA、F1值等
整理 歸納 舉例 記錄一下 (一)混淆矩陣 混淆矩陣也稱誤差矩陣,是表示精度評價的一種標準格式,用n行n列的矩陣形式來表示。 Predicted as Positive(預測-正例) Predicted as Negative(預測-反例) Label
自然語言處理技術之準確率(Precision)、召回率(Recall)、F值(F-Measure)簡介
下面簡單列舉幾種常用的推薦系統評測指標: 1、準確率與召回率(Precision & Recall) 準確率和召回率是廣泛用於資訊檢索和統計學分類領域的兩個度量值,用來評價結果的質量。其中精度是檢索出相關文件數與檢索出的文件總數的比率,衡量的是檢索系統的查準
推薦系統評測指標—精準率(Precision)、召回率(Recall)、F值(F-Measure)
下面簡單列舉幾種常用的推薦系統評測指標: 1、精準率與召回率(Precision & Recall) 精準率和召回率是廣泛用於資訊檢索和統計學分類領域的兩個度量值,用來評價結果的質量。其中精度是檢索出相關文件數與檢索出的文件總數的比率,衡量的是檢索系統的查準
評估指標:準確率(Precision)、召回率(Recall)以及F值(F-Measure)
為了能夠更好的評價IR系統的效能,IR有一套完整的評價體系,通過評價體系可以瞭解不同資訊系統的優劣,不同檢索模型的特點,不同因素對資訊檢索的影響,從而對資訊檢索進一步優化。 由於IR的目標是在較短時間內返回較全面和準確的資訊,所以資訊檢索的評價指標通常從三個方面考慮:效
召回率Recall、精確度Precision、準確率Accuracy、F值
假設原始樣本中有兩類,其中:1:總共有 P個類別為1的樣本,假設類別1為正例。 2:總共有N個類別為0 的樣本,假設類別0為負例。 經過分類後:3:有 TP個類別為1 的樣本被系統正確判定為類別1,F
機器學習:準確率(Precision)、召回率(Recall)、F值(F-Measure)、ROC曲線、PR曲線
增注:雖然當時看這篇文章的時候感覺很不錯,但是還是寫在前面,想要了解關於機器學習度量的幾個尺度,建議大家直接看周志華老師的西瓜書的第2章:模型評估與選擇,寫的是真的很好!! 摘要: 資料探勘、機器學習和推薦系統中的評測指標—準確率(Precision)、召回率
深入理解——召回率(recall) 準確率(precision) 精度(accuracy) 錯誤率(error)
精度(accuracy)和錯誤率(error) 這個最常用,用在常見的分類任務中,比如有雞,鴨,鵝,狗,貓若干,讓模型一一回答他們的類別,見到扁嘴脖子長還會嘎嘎叫的,回答為鴨,預測正確,否則回答錯誤。最後 (回答正確個數) 除以 (雞鴨鵝狗貓總數) = 精度.
準確率(Accuracy) 精確率(Precision) 召回率(Recall)和F1-Measure
搜索 例如 總數 文檔 measure 目標 就是 原本 pos 先驗知識 我們首先將數據的類別統一分為兩類:正類和負類。例如:一個數據集中的數據一共有3類,小學生、中學生、高中生。我們的目標是預測小學生,那麽標記為小學生的數據就是正類,標記為其他類型的數據都是負類。