
CS231n課程學習筆記(七)——資料預處理、批量歸一化和Dropout
資料預處理
均值減法
它對資料中每個獨立特徵減去平均值,從幾何上可以理解為在每個維度上都將資料雲的中心都遷移到原點。
#numpy
X -= np.mean(X, axis=0)歸一化
是指將資料的所有維度都歸一化,使其數值範圍都近似相等。在影象處理中,由於畫素的數值範圍幾乎是一致的(都在0-255之間),所以進行這個額外的預處理步驟並不是很必要。
X /= np.std(X, axis=0)。PCA和白化(Whitening)
在這種處理中,先對資料進行零中心化處理,然後計算協方差矩陣,它展示了資料中的相關性結構。
# 假設輸入資料矩陣X的尺寸為[N x D]
X -= np.mean 我們可以對資料協方差矩陣進行SVD(奇異值分解)運算:
U,S,V = np.linalg.svd(cov)U的列是特徵向量,S是裝有奇異值的1維陣列(因為cov是對稱且半正定的,所以S中元素是特徵值的平方)。為了去除資料相關性,將已經零中心化處理過的原始資料投影到特徵基準上:
Xrot = np.dot(X,U) # 對資料去相關性注意U的列是標準正交向量的集合(正規化為1,列之間標準正交),所以可以把它們看做標準正交基向量。因此,投影對應x中的資料的一個旋轉,旋轉產生的結果就是新的特徵向量。
np.linalg.svd的一個良好性質是在它的返回值U中,特徵向量是按照特徵值的大小排列的。我們可以利用這個性質來對資料降維。這個操作也被稱為主成分分析( Principal Component Analysis 簡稱PCA)降維:
Xrot_reduced = np.dot(X, U[:,:100]) # Xrot_reduced 變成 [N x 100]最後一個在實踐中會看見的變換是白化(whitening)。白化操作的輸入是特徵基準上的資料,然後對每個維度除以其特徵值來對數值範圍進行歸一化。該變換的幾何解釋是:如果資料服從多變數的高斯分佈,那麼經過白化後,資料的分佈將會是一個均值為零,且協方差相等的矩陣。該操作的程式碼如下:
# 對資料進行白化操作:
# 除以特徵值
Xwhite = Xrot / np.sqrt(S + 1e-5)警告:誇大的噪聲。注意分母中添加了1e-5(或一個更小的常量)來防止分母為0。該變換的一個缺陷是在變換的過程中可能會誇大資料中的噪聲。這是因為它將所有維度都拉伸到相同的數值範圍,這些維度中也包含了那些只有極少差異性(方差小)而大多是噪聲的維度。在實際操作中,這個問題可以用更強的平滑來解決(例如:採用比1e-5更大的值)。
注意:任何預處理策略(比如資料均值)都只能在訓練集資料上進行計算,演算法訓練完畢後再應用到驗證集或者測試集上。例如,如果先計算整個資料集影象的平均值然後每張圖片都減去平均值,最後將整個資料集分成訓練/驗證/測試集,那麼這個做法是錯誤的。應該怎麼做呢?應該先分成訓練/驗證/測試集,只是從訓練集中求圖片平均值,然後各個集(訓練/驗證/測試集)中的影象再減去這個平均值。
權重初始化
錯誤:全零初始化。
如果網路中的每個神經元都計算出同樣的輸出,然後它們就會在反向傳播中計算出同樣的梯度,從而進行同樣的引數更新。換句話說,如果權重被初始化為同樣的值,神經元之間就失去了不對稱性的源頭。
小隨機數初始化
因此,權重初始值要非常接近0又不能等於0。解決方法就是將權重初始化為很小的數值,以此來打破對稱性。
W = 0.01 * np.random.randn(D,H)警告:並不是小數值一定會得到好的結果。例如,一個神經網路的層中的權重值很小,那麼在反向傳播的時候就會計算出非常小的梯度(因為梯度與權重值是成比例的)。這就會很大程度上減小反向傳播中的“梯度訊號”,在深度網路中,就會出現問題。
使用1/sqrt(n)校準方差
上面做法存在一個問題,隨著輸入資料量的增長,隨機初始化的神經元的輸出資料的分佈中的方差也在增大。我們可以除以輸入資料量的平方根來調整其數值範圍,這樣神經元輸出的方差就歸一化到1了。也就是說,建議將神經元的權重向量初始化為:
w = np.random.randn(n) / sqrt(n)其中n是輸入資料的數量。這樣就保證了網路中所有神經元起始時有近似同樣的輸出分佈。實踐經驗證明,這樣做可以提高收斂的速度。
稀疏初始化(Sparse initialization)
另一個處理非標定方差的方法是將所有權重矩陣設為0,但是為了打破對稱性,每個神經元都同下一層固定數目的神經元隨機連線(其權重數值由一個小的高斯分佈生成)。一個比較典型的連線數目是10個。
偏置(biases)的初始化
通常將偏置初始化為0,這是因為隨機小數值權重矩陣已經打破了對稱性。
實踐當前的推薦是使用ReLU啟用函式,並且使用
w = np.random.randn(n) * sqrt(2.0/n)來進行權重初始化。
批量歸一化(Batch Normalization)
其做法是讓啟用資料在訓練開始前通過一個網路,網路處理資料使其服從標準高斯分佈。因為歸一化是一個簡單可求導的操作,所以上述思路是可行的。在實現層面,應用這個技巧通常意味著全連線層(或者是卷積層)與啟用函式之間新增一個BatchNorm層。
在實踐中,使用了批量歸一化的網路對於不好的初始值有更強的魯棒性。最後一句話總結:批量歸一化可以理解為在網路的每一層之前都做預處理,只是這種操作以另一種方式與網路整合在了一起。
正則化(Regularization)
在實踐中,使用了批量歸一化的網路對於不好的初始值有更強的魯棒性。最後一句話總結:批量歸一化可以理解為在網路的每一層之前都做預處理,只是這種操作以另一種方式與網路整合在了一起。
L2正則化
可以通過懲罰目標函式中所有引數的平方將其實現。即對於網路中的每個權重
L1正則化
L1正則化是另一個相對常用的正則化方法。對於每個w我們都向目標函式增加一個
最大正規化約束(Max norm constraints)
另一種形式的正則化是給每個神經元中權重向量的量級設定上限,並使用投影梯度下降來確保這一約束。在實踐中,與之對應的是引數更新方式不變,然後要求神經元中的權重向量
隨機失活(Dropout)
隨機失活(Dropout)是一個簡單又極其有效的正則化方法。該方法由Srivastava在論文Dropout: A Simple Way to Prevent Neural Networks from Overfitting中提出的,與L1正則化,L2正則化和最大正規化約束等方法互為補充。在訓練的時候,隨機失活的實現方法是讓神經元以超引數
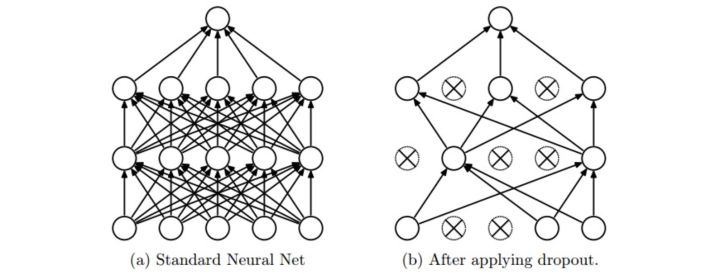
圖片來源自論文,展示其核心思路。在訓練過程中,隨機失活可以被認為是對完整的神經網路抽樣出一些子集,每次基於輸入資料只更新子網路的引數(然而,數量巨大的子網路們並不是相互獨立的,因為它們都共享引數)。在測試過程中不使用隨機失活,可以理解為是對數量巨大的子網路們做了模型整合(model ensemble),以此來計算出一個平均的預測。
一個3層神經網路的普通版隨機失活可以用下面程式碼實現:
""" 普通版隨機失活: 不推薦實現 (看下面筆記) """
p = 0.5 # 啟用神經元的概率. p值更高 = 隨機失活更弱
def train_step(X):
""" X中是輸入資料 """
# 3層neural network的前向傳播
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = np.random.rand(*H1.shape) < p # 第一個隨機失活遮罩
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = np.random.rand(*H2.shape) < p # 第二個隨機失活遮罩
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
# 反向傳播:計算梯度... (略)
# 進行引數更新... (略)
def predict(X):
# 前向傳播時模型整合
H1 = np.maximum(0, np.dot(W1, X) + b1) * p # 注意:啟用資料要乘以p
H2 = np.maximum(0, np.dot(W2, H1) + b2) * p # 注意:啟用資料要乘以p
out = np.dot(W3, H2) + b3在上面的程式碼中,train_step函式在第一個隱層和第二個隱層上進行了兩次隨機失活。在輸入層上面進行隨機失活也是可以的,為此需要為輸入資料X建立一個二值的遮罩。反向傳播保持不變,但是肯定需要將遮罩U1和U2加入進去。
注意:在predict函式中不進行隨機失活,但是對於兩個隱層的輸出都要乘以
上述操作不好的性質是必須在測試時對啟用資料要按照p進行數值範圍調整。既然測試效能如此關鍵,實際更傾向使用反向隨機失活(inverted dropout),它是在訓練時就進行數值範圍調整,從而讓前向傳播在測試時保持不變。這樣做還有一個好處,無論你決定是否使用隨機失活,預測方法的程式碼可以保持不變。反向隨機失活的程式碼如下:
"""
反向隨機失活: 推薦實現方式.
在訓練的時候drop和調整數值範圍,測試時不做任何事.
"""
p = 0.5 # 啟用神經元的概率. p值更高 = 隨機失活更弱
def train_step(X):
# 3層neural network的前向傳播
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = (np.random.rand(*H1.shape) < p) / p # 第一個隨機失活遮罩. 注意/p!
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = (np.random.rand(*H2.shape) < p) / p # 第二個隨機失活遮罩. 注意/p!
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
# 反向傳播:計算梯度... (略)
# 進行引數更新... (略)
def predict(X):
# 前向傳播時模型整合
H1 = np.maximum(0, np.dot(W1, X) + b1) # 不用數值範圍調整了
H2 = np.maximum(0, np.dot(W2, H1) + b2)
out = np.dot(W3, H2) + b3在隨機失活釋出後,很快有大量研究為什麼它的實踐效果如此之好,以及它和其他正則化方法之間的關係。如果你感興趣,可以看看這些文獻:
實踐:通過交叉驗證獲得一個全域性使用的L2正則化強度是比較常見的。在使用L2正則化的同時在所有層後面使用隨機失活也很常見。
p 值一般預設設為0.5 ,也可能在驗證集上調參。