
反反爬技術,破解貓眼網加密數字
一、背景
字型反爬應用還是很普遍。這兩天有朋友諮詢如何實現貓眼票房資料的爬取,這裡其實與上面的文章核心思想是一致的,但是操作更復雜一些,本文做一個更詳細的破解實踐。
有對字型反爬還比較陌生的,請參考前文。
二、查詢字型源
貓眼電影是美團旗下的一家集媒體內容、線上購票、使用者互動社交、電影衍生品銷售等服務的一站式電影網際網路平臺。2015年6月,貓眼電影覆蓋影院超過4000家,這些影院的票房貢獻佔比超過90%。目前,貓眼佔網絡購票70%的市場份額,每三張電影票就有一張出自貓眼電影,是影迷下載量較多、使用率較高的電影應用軟體。同時,貓眼電影為合作影院和電影製片發行方提供覆蓋海量電影消費者的精準營銷方案,助力影片票房。
我們使用Chrome瀏覽頁面,並檢視原始碼,發現售票中涉及數字的,在頁面顯示正常,在原始碼中顯示一段span包裹的不可見文字。
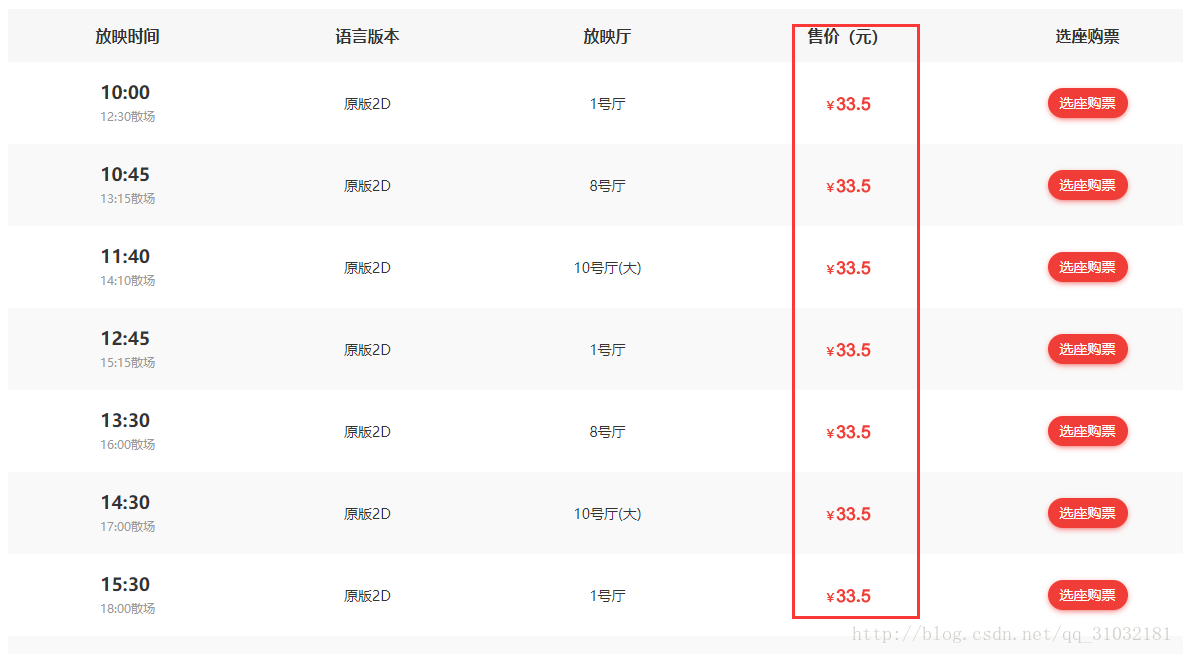
上面其實就是自定義字型搞的鬼。根據網頁原始碼中,
<span class="stonefont">.</span>
使用了自定義的stonefont字型,我們在網頁中查詢stonefont,很快有了發現,這就是標準的@font-face定義方法。且每次訪問,字型檔案訪問地址都會隨機變化。

我們訪問其中woff檔案的地址,可將woff字型檔案下載到本地。前文中fonttools並不能直接解析woff字型,我們需要將woff字型轉換成otf字型。百度可以直接轉換字型 ,地址:http://fontstore.baidu.com/static/editor/index.html
三、字型解析
otf就是我們常用的字型檔案,可以使用系統自帶的字型檢視器檢視,但是難以看到更多有效的資訊,我們使用一個專用工具Font Creator檢視。

可以看到,這個字型裡有12個字(含一個空白字),每個字顯示其字形和其字形編碼。這裡比之前字型解析更復雜的是,這裡不僅字型編碼每次都會變,字型順序每次也會變,很難直接通過編碼和順序獲取實際的數字。
因此,我們需要預先下載一個字型檔案,人工識別其對應數值和字型,然後針對每次獲取的新的字型檔案,通過比對字型字形資料,得到其真實的數字值。
下面是使用fontTools.ttLib獲取的單個字元的字形資料。
<TTGlyph 使用下面語句可以獲取順序的字元編碼值,
# 解析字型庫font檔案
baseFont = TTFont('base.otf')
maoyanFont = TTFont('maoyan.otf')
uniList = maoyanFont['cmap'].tables[0].ttFont.getGlyphOrder()
numList = []
baseNumList = ['.', '3', '5', '1', '2', '7', '0', '6', '9', '8', '4']
baseUniCode = ['x', 'uniE64B', 'uniE183', 'uniED06', 'uniE1AC', 'uniEA2D', 'uniEBF8',
'uniE831', 'uniF654', 'uniF25B', 'uniE3EB']
for i in range(1, 12):
maoyanGlyph = maoyanFont['glyf'][uniList[i]]
for j in range(11):
baseGlyph = baseFont['glyf'][baseUniCode[j]]
if maoyanGlyph == baseGlyph:
numList.append(baseNumList[j])
break
四、內容替換
關鍵點攻破了,整個工作就好做了。先訪問需要爬取的頁面,獲取字型檔案的動態訪問地址並下載字型,讀取使用者帖子文字內容,替換其中的自定義字型編碼為實際文字編碼,就可復原網頁為頁面所見內容了。
完整程式碼如下:
# -*- coding:utf-8 -*-
import requests
from lxml import html
import re
import woff2otf
from fontTools.ttLib import TTFont
from bs4 import BeautifulSoup as bs
#抓取maoyan票房
class MaoyanSpider:
#頁面初始化
def __init__(self):
self.headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.8",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36"
}
# 獲取票房
def getNote(self):
url = "http://maoyan.com/cinema/15887?poi=91871213"
host = {'host':'maoyan.com',
'refer':'http://maoyan.com/news',}
headers = dict(self.headers.items() + host.items())
# 獲取頁面內容
r = requests.get(url, headers=headers)
#print r.text
response = html.fromstring(r.text)
u = r.text
# 匹配ttf font
cmp = re.compile(",\n url\('(//.*.woff)'\) format\('woff'\)")
rst = cmp.findall(r.text)
ttf = requests.get("http:" + rst[0], stream=True)
with open("maoyan.woff", "wb") as pdf:
for chunk in ttf.iter_content(chunk_size=1024):
if chunk:
pdf.write(chunk)
# 轉換woff字型為otf字型
woff2otf.convert('maoyan.woff', 'maoyan.otf')
# 解析字型庫font檔案
baseFont = TTFont('base.otf')
maoyanFont = TTFont('maoyan.otf')
uniList = maoyanFont['cmap'].tables[0].ttFont.getGlyphOrder()
numList = []
baseNumList = ['.', '3', '5', '1', '2', '7', '0', '6', '9', '8', '4']
baseUniCode = ['x', 'uniE64B', 'uniE183', 'uniED06', 'uniE1AC', 'uniEA2D', 'uniEBF8',
'uniE831', 'uniF654', 'uniF25B', 'uniE3EB']
for i in range(1, 12):
maoyanGlyph = maoyanFont['glyf'][uniList[i]]
for j in range(11):
baseGlyph = baseFont['glyf'][baseUniCode[j]]
if maoyanGlyph == baseGlyph:
numList.append(baseNumList[j])
break
uniList[1] = 'uni0078'
utf8List = [eval("u'\u" + uni[3:] + "'").encode("utf-8") for uni in uniList[1:]]
# 獲取發帖內容
soup = bs(u,"html.parser")
index=soup.find_all('div', {'class': 'show-list'})
print '---------------Prices-----------------'
for n in range(len(index)):
mn=soup.find_all('h3', {'class': 'movie-name'})
ting=soup.find_all('span', {'class': 'hall'})
mt=soup.find_all('span', {'class': 'begin-time'})
mw=soup.find_all('span', {'class': 'stonefont'})
for i in range(len(mt)):
moviename=mn[i].get_text()
film_ting = ting[i].get_text()
movietime=mt[i].get_text()
moviewish=mw[i].get_text().encode('utf-8')
for i in range(len(utf8List)):
moviewish = moviewish.replace(utf8List[i], numList[i])
print moviename,film_ting,movietime,moviewish
spider = MaoyanSpider()
spider.getNote()
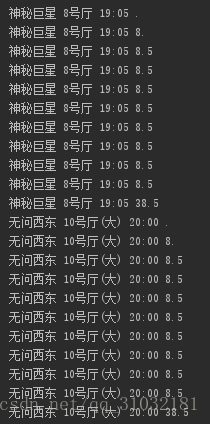
解析訪問,獲取資料(最後一列是加密破解後的資料)。
交流群:453908562