
Keras上基於TensorFlow實現簡單線性迴歸模型
神經網路可以用來模擬迴歸問題。
首先回歸問題是什麼,迴歸問題通常是用來預測一個值,如預測房價、未來的天氣情況等等,例如一個產品的實際價格為500元,通過迴歸分析預測值為499元,我們認為這是一個比較好的迴歸分析。一個比較常見的迴歸演算法是線性迴歸演算法(LR)。另外,迴歸分析用在神經網路上,其最上層是不需要加上softmax函式的,而是直接對前一層累加即可。回強調內容歸是對真實值的一種逼近預測。
這裡我們就是用一條線段來對一些連續的資料進行擬合,進而我們可以通過這個曲線預測出新的輸出值。
首先是資料圖:
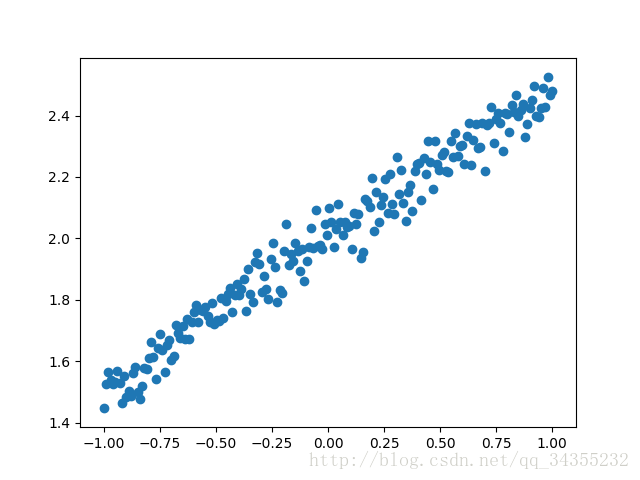
我們需要做的就是將其用一條直線將其取代。類似下圖:
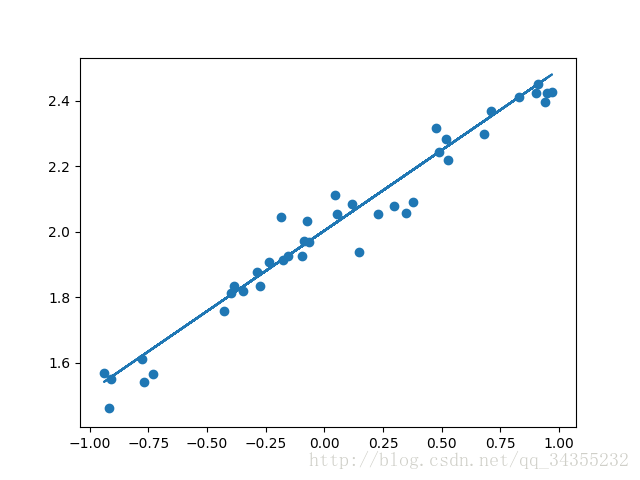
一、根據程式碼對其進行詳細解讀
1.匯入的模組
匯入本例子需要的模組,numpy、Matplotlib、kears.models和keras.models模組。Sequential()是多個網路層的線性堆疊。可以直接在其內部加入各個網路層或者通過 add()函式一個一個將網路層加入其中。Dense是全連線神經網路層。
model.add(Dense(64, input_dim=64, W_regularizer=l2(0.01), activity_regularizer=activity_l2(0.01)))
Dense層包括output_dim(輸出維度)、input_dim(輸入維度)、activation(啟用函式)、weights(權值)、W_regularizer(施加在權值上的正則項)、b_regularizer(施加在偏置向量上的正則項)、activity_regularizer(施加在輸出上的正則項)、W_constraints(施加在權值上的約束項)、b_constraints、bias(布林值,是否包含偏置向量)這些引數。
2.資料的生成
利用numpy中的linspace()函式生成200個-1~~1之間的等差數列X,然後根據線性函式生成Y,並對Y新增噪音。這樣就得到了資料,下面我們需要對資料進行分類分成兩類一類是訓練集一類是測試集。我們分配前160為訓練集,後40為測試集。
3.建立模型
因為迴歸問題比較簡單我們只需要一個層就可以了。
首先我們用Sequential建立一個模型,然後向其中新增Dense全連線神經層。引數這裡是一個是輸入資料的維度,另一個units代表神經元數,即輸出單元數。如果需要新增下一個神經層的時候,不用再定義輸入的緯度,因為它預設就把前一層的輸出作為當前層的輸入。在這個簡單的例子裡,只需要一層就夠了(這是基於TensorFlow,如果是Theano,則需要將引數units換為output_dim
4.編譯模型
model.compile()來編譯和啟用模型,這裡我們用的損失函式是mse均方誤差;優化器用的是sgd隨機梯度下降。
compile(self, optimizer, loss, metrics=[], loss_weights=None, sample_weight_mode=None)本函式編譯模型以供訓練,引數有
optimizer:優化器,為預定義優化器名或優化器物件,參考優化器
loss:目標函式,為預定義損失函式名或一個目標函式,參考目標函式
metrics:列表,包含評估模型在訓練和測試時的效能的指標,典型用法是 metrics=[‘accuracy’] 如果
Keras中文文件
要在多輸出模型中為不同的輸出指定不同的指標,可像該引數傳遞一個字典,例如 metrics=
{‘ouput_a’: ‘accuracy’}
sample_weight_mode:如果你需要按時間步為樣本賦權(2D權矩陣),將該值設為“temporal”。
預設為“None”,代表按樣本賦權(1D權)。如果模型有多個輸出,可以向該引數傳入指
定sample_weight_mode的字典或列表。在下面 fit 函式的解釋中有相關的參考內容。
kwargs:使用TensorFlow作為後端請忽略該引數,若使用Theano作為後端,kwargs的值將會傳遞
給 K.function
5.訓練模型
訓練的時候用 model.train_on_batch 一批一批的訓練 X_train, Y_train。預設的返回值是 cost,每100步輸出一下結果。
train_on_batch(self, x, y, class_weight=None, sample_weight=None)本函式在一個batch的資料上進行一次引數更新
函式返回訓練誤差的標量值或標量值的list,與evaluate的情形相同。
6.驗證模型
用到的函式是 model.evaluate,輸入測試集的x和y,輸出 cost,weights 和 biases。其中 weights 和 biases 是取在模型的第一層 model.layers[0] 學習到的引數。
evaluate(self, x, y, batch_size=32, verbose=1, sample_weight=None)本函式按batch計算在某些輸入資料上模型的誤差,其引數有:
x:輸入資料,與 fit 一樣,是numpy array或numpy array的list
y:標籤,numpy array
batch_size:整數,含義同 fit 的同名引數
verbose:含義同 fit 的同名引數,但只能取0或1
sample_weight:numpy array,含義同 fit 的同名引數
本函式返回一個測試誤差的標量值(如果模型沒有其他評價指標),或一個標量的list(如果模型還有
其他的評價指標)。
二、完整程式碼
import numpy as np
np.random.seed(1337)
from keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt
/*建立資料集*/
X=np.linspace(-1,1,200)
np.random.shuffle(X)
Y=0.5*X+2+np.random.normal(0,0.05,(200,))
/*視覺化*/
plt.scatter(X,Y)
plt.show()
X_train,Y_train=X[:160],Y[:160]
X_test,Y_test=X[160:],Y[160:]
/*建立神經網路模型*/
model=Sequential()
model.add(Dense(input_dim=1,units=1))
/*編譯,選定loss函式和優化器*/
model.compile(loss='mse',optimizer='sgd')
/*訓練過程*/
print('Training--------------')
for step in range(501):
cost=model.train_on_batch(X_train,Y_train)
if step%100==0:
print('train_cost: ',cost)
/*測試過程*/
print('\nTesting--------------')
cost=model.evaluate(X_test,Y_test,batch_size=40)
print('test cost:',cost)
W, b=model.layers[0].get_weights()
print('weight= ',W,'\nbiases=',b)
/*結果的視覺化*/
Y_pred=model.predict(X_test)
plt.scatter(X_test,Y_test)
plt.plot(X_test,Y_pred)
plt.show()