
Adversarial Network Embedding論文解讀
Adversarial Network Embedding
摘要
現有的方法可以有效地將結構屬性編碼成低維向量表示,但是,他們大多缺少加強表示魯棒性的額外約束。本篇文章提出一個對抗網路表示(ANE)框架,利用對抗學習原則來規劃表示學習。框架由兩部分組成,一個結構保留部分和一個對抗學習部分,前者旨獲取網路結構屬性,後者致力於學習魯棒性表示,使結構保留部分生成的網路表示服從先驗分佈。
介紹
網路表示是一個具有挑戰性的研究難題。因為圖結構資料的高維、稀疏和非線性的原因。儘管現有的方法在結構保留方面很有效,但是缺乏魯棒性約束,當處理具有噪聲的網路資料時,這些無監督學習網路表示往往表現不好。因此,在表示學習過程中考慮一些不穩定因素是至關重要的。無監督中加強表示學習魯棒性的一個著名的技術是降噪自編碼器。它通過從輸入中剔除噪音來獲得穩定且魯棒的表示,這也是降噪的標準。近期,許多生成對抗模型被提出學習魯棒且穩定的表示,但是,這些模型中沒有一個用來處理圖資料。本文提出的ANE,除了優化保留結構的目標,還有給不穩定資料建模的對抗學習過程。ANE的結構保留部分,我們提出一個適合於框架的inductive DeepWalk,它保留了隨機遊走搜尋節點的鄰接資訊,並且優化相似目標函式,但是用一個引數函式生成表示向量。對抗學習部分由生成器和 辨別器組成。
相關工作
網路表示方法
無監督表示學習方法可以分為三類:概率方法、基於矩陣分解的方法和基於自動編碼器方法。概率方法包括DeepWalk、Line、node2vec等。DeepWalk首先通過隨機遊走出原圖中獲得節點序列,然後把詞序列看成節點序列並利用Skip-gram模型學習潛在表示。Line保留一階、二階近似性。node2vec中提出具有偏置的隨機遊走來決定鄰接結構。
局域矩陣分解的方法首先通過預處理鄰接矩陣獲取高階近似性,然後分解處理好的矩陣獲得圖表示。例如,GraRep基於DeepWalk中的k步隨機遊走和k步相似轉換矩陣的原則並且採用PPMI作為預處理。HOPE預處理具有高階相似性的有向圖。
自動編碼器為了重構結構資訊,在隱含空間裡保留儘可能多的資訊。DNGR首先計算PPMI矩陣,然後通過堆疊降噪自動編碼器學習表示。SDNE是在堆疊自動編碼器的損失函式中新增約束,要求連線的節點具有相似的表示向量。
生成對抗網路
GAN是深度生成模型,但是這個框架由於沒有明確的推理結構從而不能直接用於無監督表示學習。對於這個問題有三種解決辦法,第一,將一些結構整合到框架中做推理,例如,將資料取樣對映到特徵空間。第二種是從辨別器的隱藏層中生成表示,如,DCGA。第三種的思想是利用對抗學習過程正則化表示。例如,對抗自動編碼器。
對抗網路表示
ANE主要由結構保留部分和對抗學習部分組成。本文提出一個inductive DeepWalk用於結構保留,保留了搜尋節點鄰近資訊的隨機遊走並且優化相似目標函式,但是採用引數函式G(·)生成表示向量。需要強調的是,函式G(·)由結構保留部分和對抗學習部分共享。這兩個組成部分在訓練過程中將有選擇的更新函式G(·)。
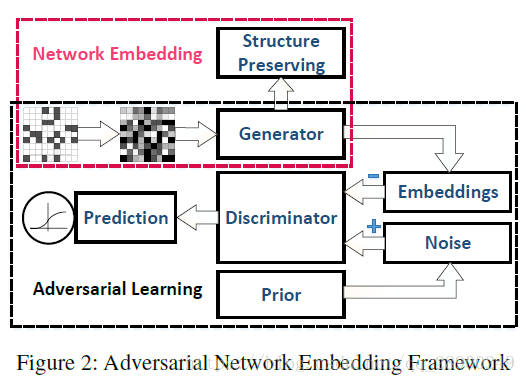
圖預處理
在應用中,資訊網路往往過於稀疏從而可能會導致過擬合,為了解決這個問題,一個通用的方法是用高階相似性預處理鄰接矩陣,將鄰接矩陣轉換為shifted PPMI矩陣。
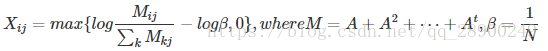
結構保留模型
許多現有地 無監督網路表示學習方法是通過表示查詢作為表示生成的轉換方法,例如DeepWalk和LINE,不適合於對抗學習部分的生成器,因為我們用引數生成器作為標準的GAN。有引數生成器,我們提出的網路可以很好的處理就有節點屬性的網路,並且通過深度學習模型獲得網路的非線性屬性。本片文章提出一個inductive DeepWalk適合於有權圖和無權圖。
IDW IDW和DeepWalk一樣通過隨機遊走取樣節點序列。為了提高效率,在每一次取樣步驟中使用alias表方法從候選節點集中取樣節點,每個採用步驟只花費O(1)時間,然後正節點對從節點序列中構建。對於每一個節點序列W,我們定義正target-context節點對是集。
和Skip-gram類似,一個節點Vi有兩個不同的表示,一個是目標表示ui,一個上下文表示ui',分別由目標生成器G(·;θ1)和上下文生成器F(·;θ1')這些生成器是由神經網路實現的引數函式。為了獲得網路結構屬性,我們用負取樣的方法為每個目標-上下文節點對定義如下的目標函式:
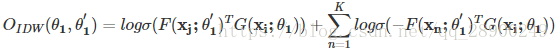
其中是一個sigmoid函式,K是負取樣數量。
對抗學習
對抗學習部分用來正則化表示,不同於GAN,在我們這個框架中,先驗分佈p(z)是生成真實資料的資料分佈,而表示向量i假取樣。在訓練構成中,辨別器將先驗取樣和表示向量區分開。辨別器函式是:
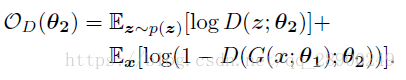
生成器用來改進下面的結果:
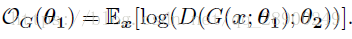
在對抗學習過程中最重要的是選擇一個正確的先驗分佈,在許多GAN實踐中,先驗分佈通常被定義為均勻分佈或高斯分佈。
結論
提出了一個網路表示框架,用來學習魯棒的圖表示。框架由兩部分組成,一個結構保留和一個對抗學習。結構保留部分,我們提出一個inductive DeepWalk來獲取網路結構屬性。對抗學習階段,我們建立一個最大最小優化問題,將先驗分佈加到表示上從而加強魯棒性。網路視覺化和節點分類的應用證明了我們提出方法的有效性。