
COURSERA機器學習筆記2
第五週:
Neural Networks: Learning
關於神經網路的記法:
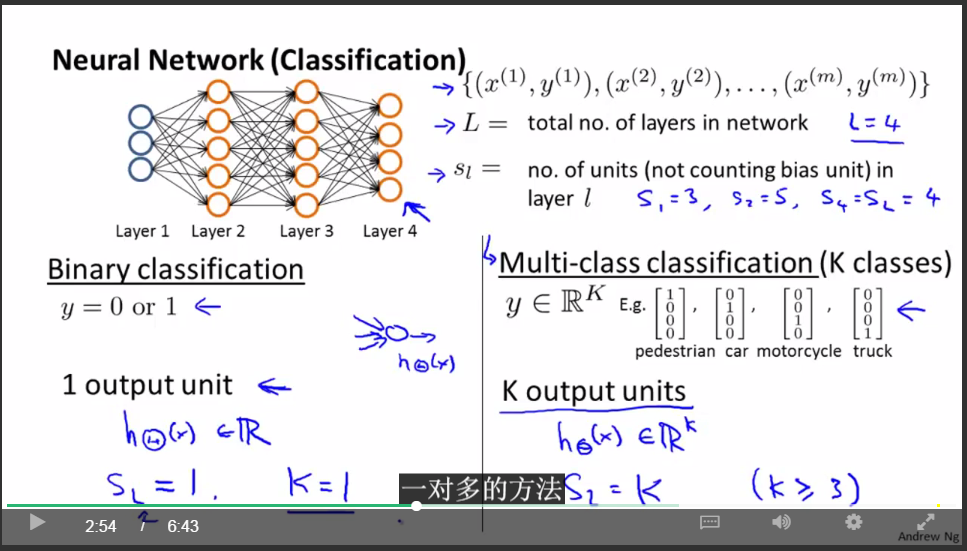
神經網路的代價函式:

直接計算神經網路的各項導數很複雜,為了計算導數,採用反向傳播(backpropagation)的演算法:


前項傳播原理:
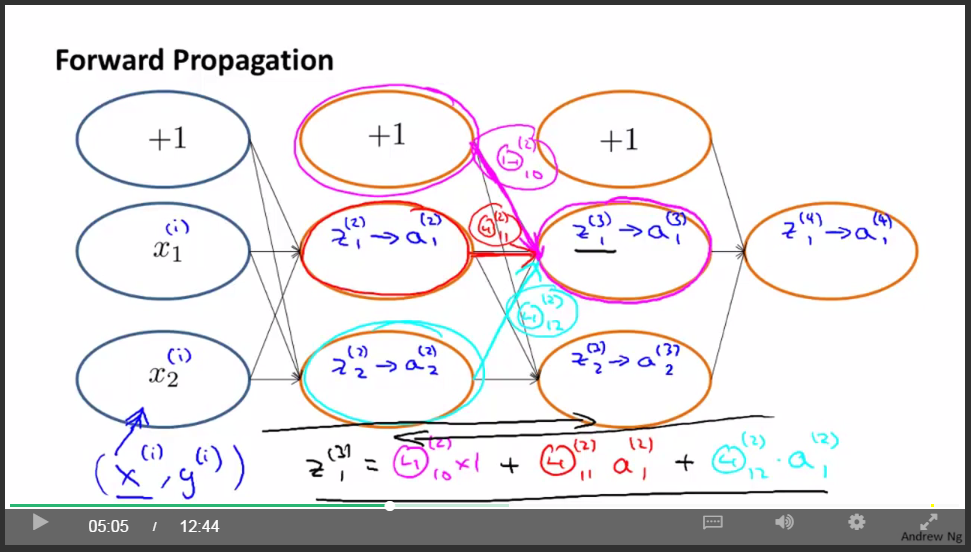
後向傳播:

矩陣與向量之間的轉換:
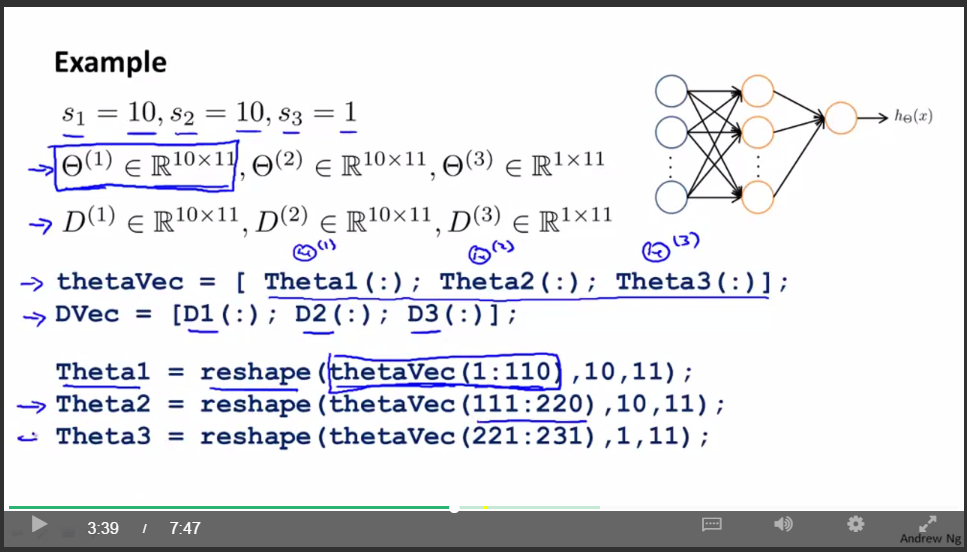

使用矩陣表示式的好處是:當你的引數以矩陣的形式儲存時,你在進行正向傳播和反向傳播時,你會覺得更加方便。
使用向量表示式的好處是:如果你有像thetaVec或者DVec這樣的矩陣,當你使用一些高階的優化演算法時,這些演算法通常要求你所有的引數都要展開成一個長向量的形式。
梯度檢查(目的:檢查後向傳播演算法結果跟梯度的數值計算方法結果是不是差不多):

隨機初始化:
採用零初始化的問題:

隨機初始化(目的:打破對稱性):

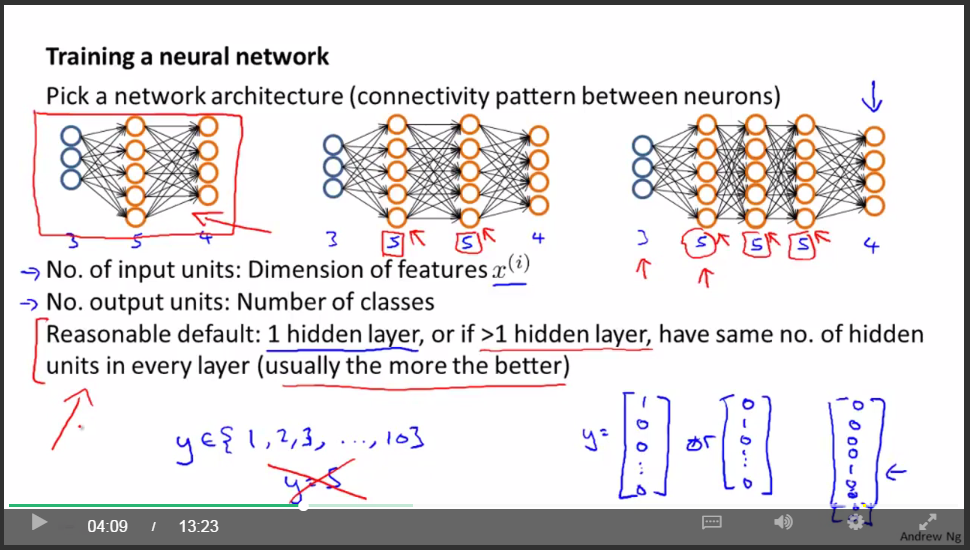
關於神經網路的總結
- 首先選取神經網路模型的結構
- 神經網路訓練過程(共6步)
隨機初始化權值時,通常設為很小的值,接近於零


第六週:
Advice for Applying Machine Learning
Machine Learning System Design
問題引入:

上面的這幾種方法都可以試一試。但是,我們憑感覺試一試之後,有可能是一條不歸路。有沒有方法能夠幫助我們選擇呢?
解決方法(”診斷法”):

評估機器學習演算法的效能:
用70%作為訓練,用30%作為測試,計算測試樣本的誤差。(注意要shuffle)
另一種更好的評估方法:
用60%作為訓練集,用20%作為交叉驗證集,用20%作為測試集。
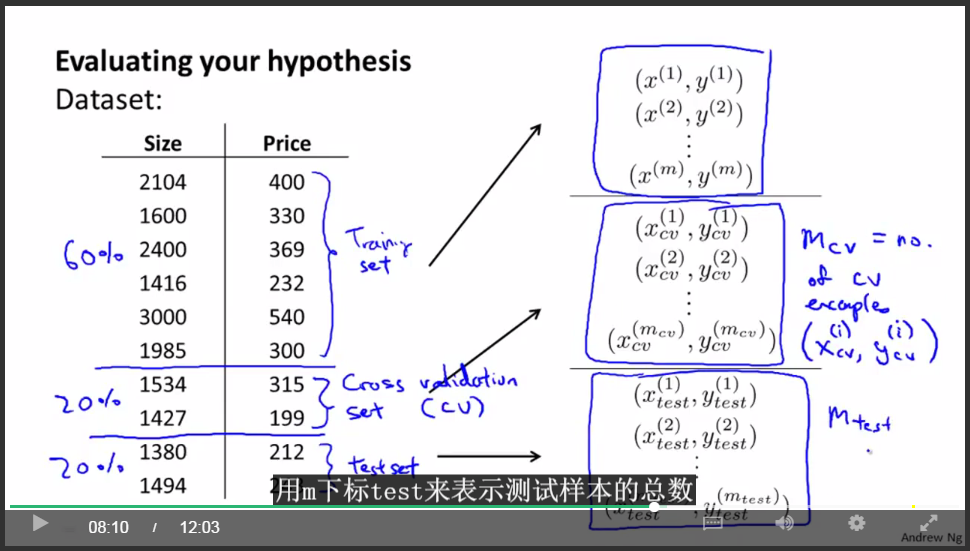
定義誤差:

交叉驗證集與測試集:

error:
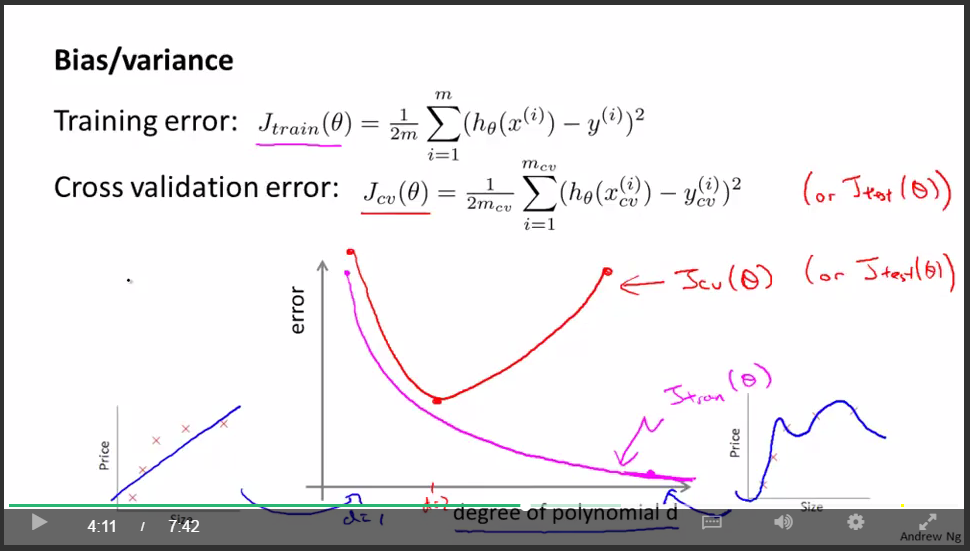
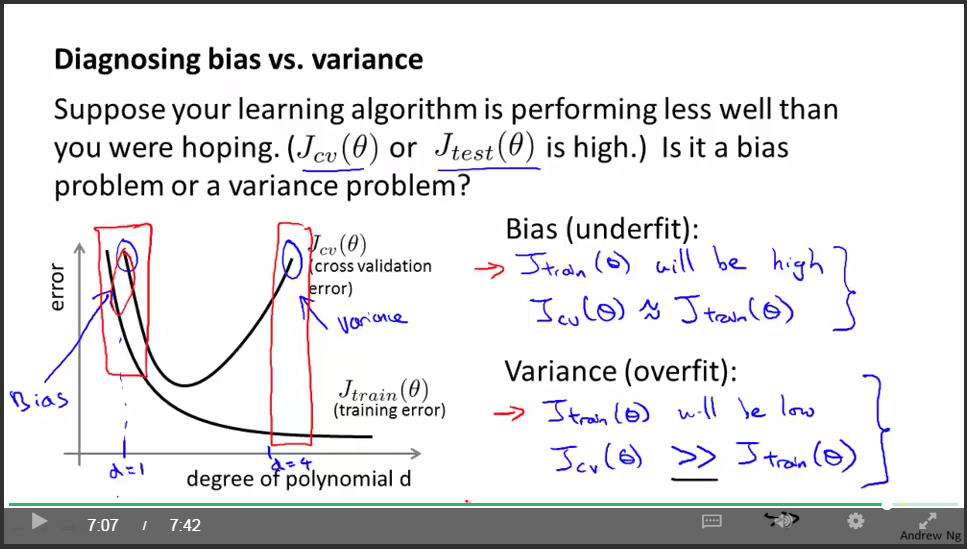
判斷underfit or overfit:
選擇theta:


學習曲線:
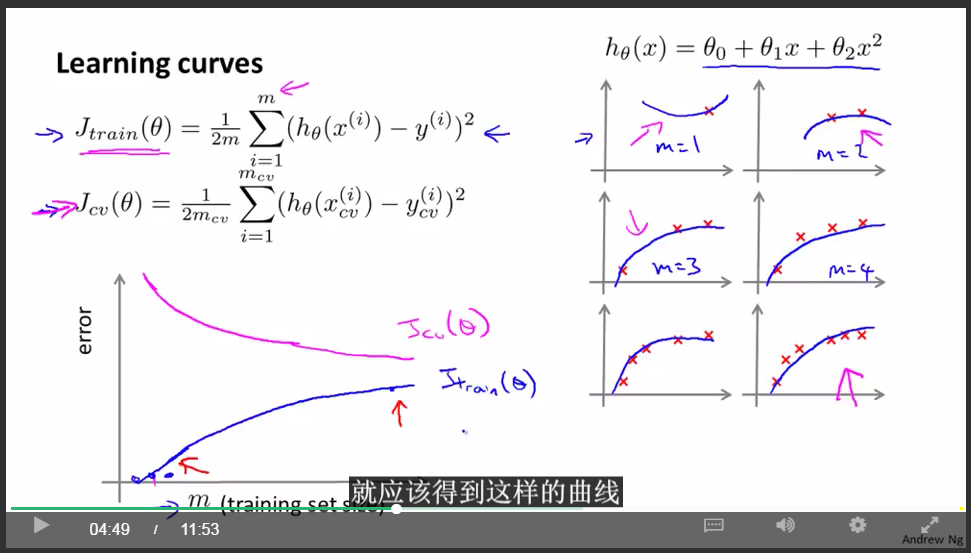
交叉驗證集誤差是對完全陌生的交叉驗證集資料進行預測得到的誤差。那麼我們知道 當訓練集很小的時候,泛化程度不會很好,意思是不能很好地適應新樣本,因此這個假設,就不是一個理想的假設。只有當我使用一個更大的訓練集時,我才有可能得到一個能夠更好擬合數據的可能的假設。因此,你的驗證集誤差和測試集誤差都會隨著訓練集樣本容量m的增加而減小。因為你使用的資料越多,你越能獲得更好地泛化表現或者說對新樣本的適應能力更強。
underfit(high bias):
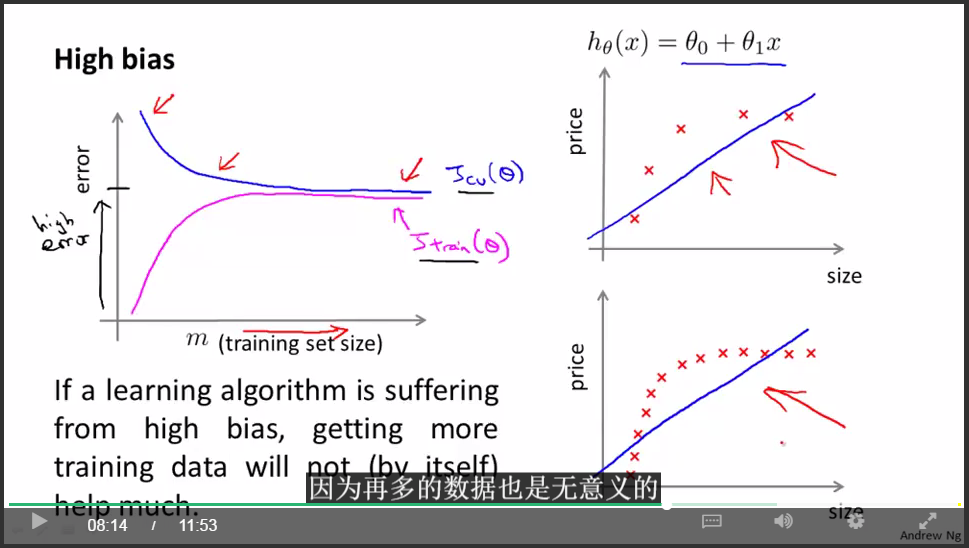
重要結論:
如果學習演算法處於underfit狀態,那麼增加更多的訓練資料是沒用的。
overfit(high variance):
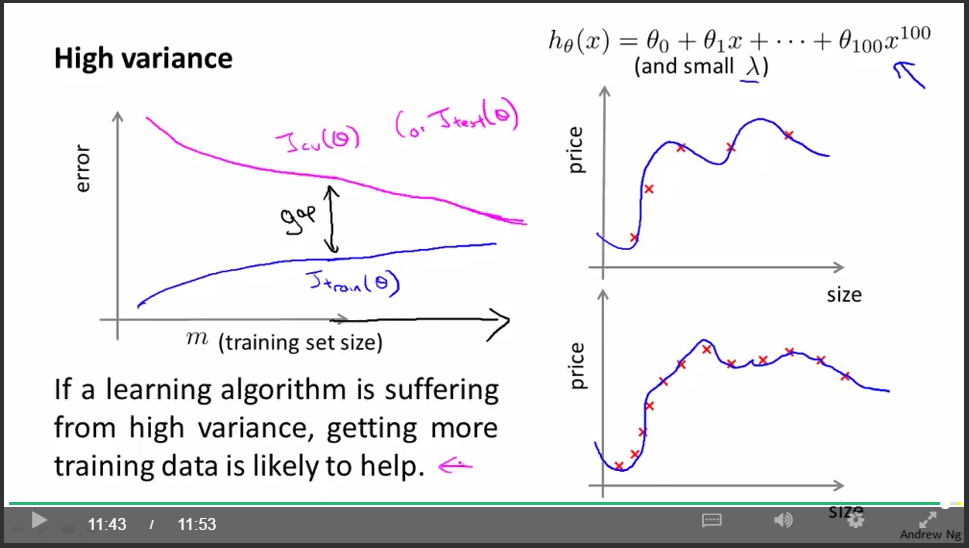
重要結論:
如果學習演算法處於overfit狀態,那麼增加更多的訓練資料是有用的。
到現在,我們能夠對引入的問題進行回答了。
總結:

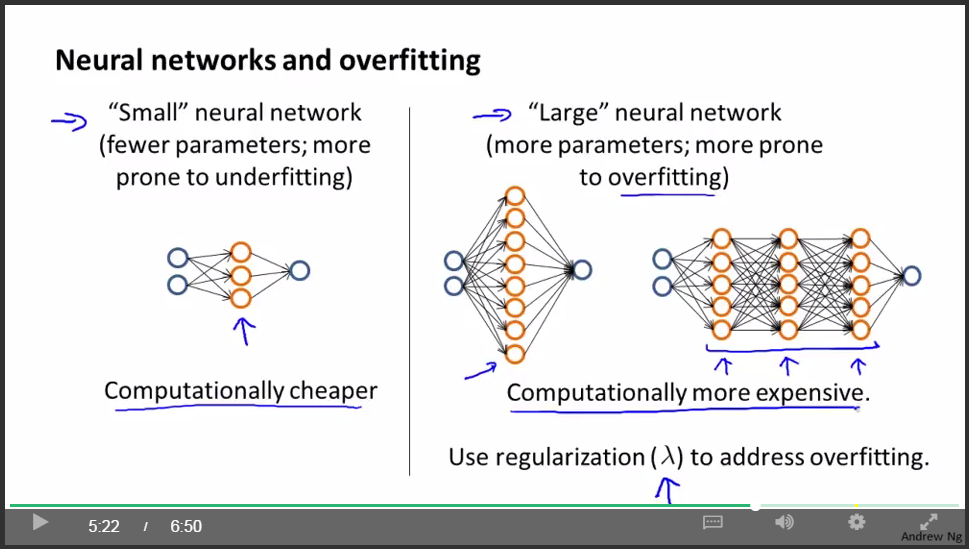
通常來說,正如我在前面的視訊中講過的,預設的情況是,使用一個隱藏層。但是如果你確實想要選擇多個隱藏層,你也可以試試把資料分割為訓練集,驗證集和測試集,然後使用交叉驗證的方法比較一個隱藏層的神經網路。然後試試兩個,三個隱藏層,以此類推。然後看看哪個神經網路在交叉驗證集上表現得最理想。也就是說,你得到了三個神經網路模型,分別有一個,兩個,三個隱藏層 然後你對每一個模型都用交叉驗證集資料進行測試,算出三種情況下的交叉驗證集誤差Jcv。然後選出你認為最好的神經網路結構。
機器學習系統設計:
舉例:垃圾郵件分類

首先可以”頭腦風暴”一下

但是要從中選取比較好的一個方法就需要一個系統性的方法“誤差分析”了。
系統設計的通用步驟:

大致步驟:
1.快速實現,然後交叉檢驗
2.畫出學習曲線,看接下來哪些做法是有用的
3.誤差分析
誤差分析:


偏斜類:
癌症分類樣本中,真正得癌症的人的樣本非常非常少,大概只有0.5%,非癌症類遠大於癌症類。那麼這時癌症類就為偏斜類。
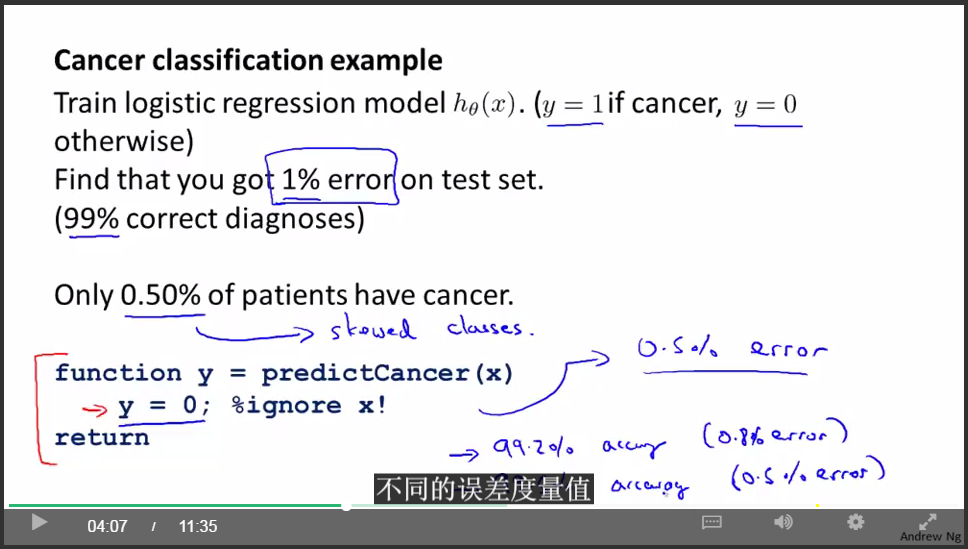
我們不能簡單地用分類精確度來衡量分類的好壞。
因為如果我們簡單粗暴地忽略輸入,直接輸出”肺癌症”類,那麼我們的分類精確度是99.5%,看起來很高,但是這個策略是完全錯誤的啊!
引入查準率和召回率:

對於大多數迴歸模型,得權衡查準率和召回率:
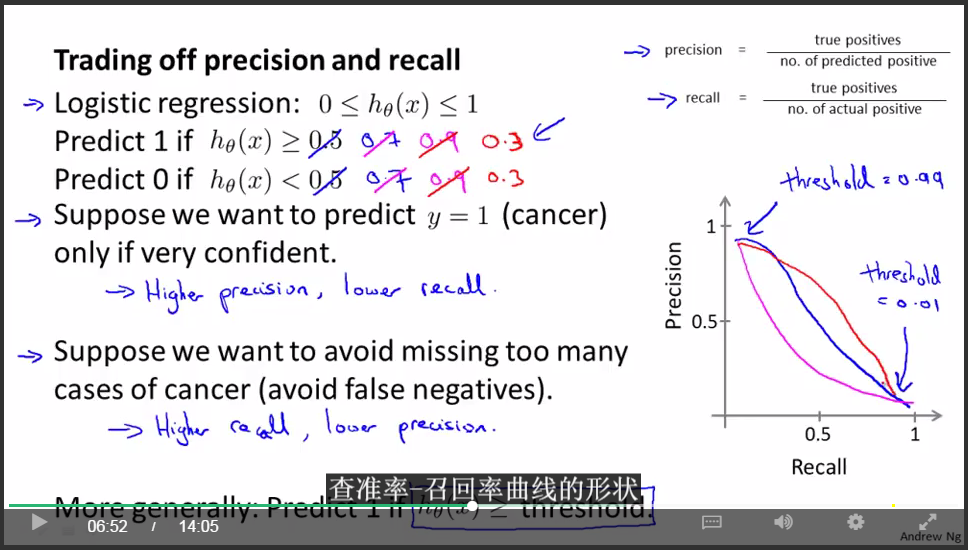
這產生了另一個有趣的問題,有沒有辦法自動選取臨界值?
F值:
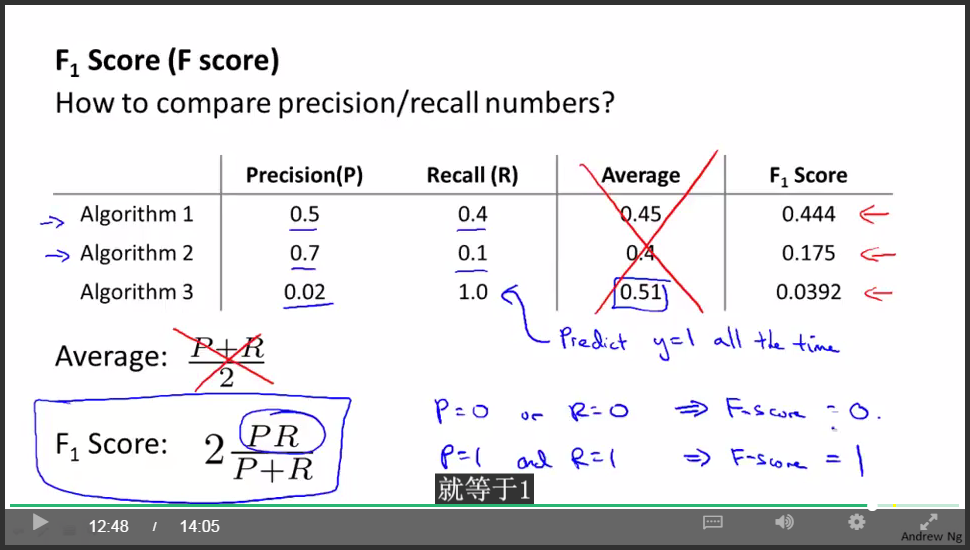
通過最大化F值來選擇臨界值!
關於機器學習的資料:

多少特徵才能夠預測呢?


什麼時候大資料量不起作用:

總結:
一個高效能的學習演算法,我覺得關鍵的測試,我常常問自己,首先 一個人類專家看到了特徵值x能很有信心的預測出 y值嗎?因為這可以證明y可以根據特徵值x被準確地預測出來(包含足夠資訊)。其次,我們實際上能得到一組龐大的訓練集並且在這個訓練集中訓練一個有很多引數的學習演算法嗎?如果你能做到這兩者,滿足這兩個條件,那麼你會得到一個性能很好的學習演算法。
第七週:
Support Vector Machines
支援向量機:
先來看看邏輯迴歸的思想:

從邏輯迴歸的代價函式來推匯出支援向量機:

對於邏輯迴歸,目標函式應該由兩部分組成,一部分為訓練樣本的代價,另一部分為正則化項。
將代價函式前面的常數去掉並不影響取得最小值時的theta值(去掉m),所以SVM的代價函式變為:


人們通常將SVM成為大間距分類器。
下圖從SVM目標函式的性質闡述了SVM比通常分類器要嚴格一些這一特點。

並且還可以通過設定引數C來改變些什麼。下面假設C很大:

SVM努力用最大間距將正負樣本分開(如下面黑色分界線所示):

因為SVM是基於最大間距分隔的,因此如果C設定很大,那麼下圖中加入一個異常點,將使原來的黑色分界線變為粉色分界線:

SVM背後的數學知識:
關於內積:


與分界線相交的是theta線:
下圖左邊將使theta的值變大,而右邊使theta值變小,因為右邊的投影比較大,就可以使theta的值很小。這就是我們想要的,所以SVM會產生最大間距分隔,通過設定theta0是否為0來表明分界線是否通過原點。

為了構造複雜的非線性分類器,我們引入kernel:
思路一:回顧以前,如果想構造非線性分類器,我們可以選取高階項的特徵向量作為輸入,如下:

但問題是,我們有沒有比高階項方法更好的方法呢?因為在高階項方法中,我們並不清楚哪些項是否是我們需要的,這就帶來了巨大的運算量。
有沒有更好的選擇f1,f2,f3,…的方法呢?通過選擇合適的kernel函式?l1,l2,l3是我們隨便選取的點。

kernel函式有很多種啦,上述用的是高斯核函式。
kernel和相似度:

從這裡,我們可以總結機器學習中關於數值轉換的慣用套路,加exp函式,它能夠使0對映為1,使負無窮對映為0!
圖解舉例kernel,以及引數&對其的影響:

再舉例,離l1,l2較近的點將被認為是positive,遠離的被認為是negative。

在SVM中使用它們,我們通過標記點和相似度函式來定義新的特徵向量,從而訓練複雜的非線性分類器。
我們還需要解決的問題是:1.怎樣正確高效的選擇這些點(landmarks),2.其他的相似度方程是怎樣的(上面例子中的核函式為高斯核函式嘛)
choose the landmarks:
最簡單的就是如下的選取:

下圖描述了SVM的細節,注意在具體實施時,第二部分會有一些改變,略微改變了優化目標,主要原因是為了提高運算效率。

為什麼我們不將核函式的思想運用到其他的演算法中呢?比如邏輯迴歸上。
答案是:確實可以將核函式這種想法用於定義特徵向量,將標記點之類的技術用於邏輯迴歸演算法上,但是用於SVM的計算技巧,不能較好地推廣到其他演算法上,諸如邏輯迴歸。還有一些高階的優化技巧,是專門為使用核函式的SVM開發的。總而言之,核函式思想可以用在其他演算法上,但效果可能不好。
關於SVM中不同引數帶來的結果:

練習:

using an SVM:
SVM演算法是一個特定的優化問題,不建議自己寫來求解引數theta。那麼我們需要自己做哪些事情呢?

上圖給出了兩種核函式並給出了適用的情況。
當你使用高斯核函式時:

如上圖所示,請注意做好歸一化!
為了能夠快速得到theta,很多優化技巧只對基於下列定理的核函式起作用,因此自定義核函式的時候需要滿足下列默賽爾定理:

不過現實中,還是高斯和線性核函式用的比較多。
練習:

更加重視交叉驗證!
用SVM怎樣處理多分類的問題,1.可以用軟體自帶,2.可以用one VS all的思想,前面在將邏輯迴歸的時候已經講過了。

邏輯迴歸與SVM的比較:

SVM的優化問題是一種凸優化問題,所以SVM演算法總是會找到全域性最優值或者接近它的值,而不會陷入區域性最優。
總結
當遇到機器學習問題時,有時確實不清楚該使用何種演算法,雖然演算法很重要,但更重要的是,你有多少資料,你有多熟練,是否擅長做誤差分析和除錯學習演算法,想出如何設計新的特徵變數,通常這方面的知識更加重要!
第八週:
Unsupervised Learning
無監督學習:
在無監督學習中,我們面對的是一組無標記的訓練資料,資料之間,不具有任何相關聯的標記。在該學習中,我們將這種未標記的資料送入特定的演算法,然後我們要求演算法替我們分析出資料的結構。比如聚類:

K-means演算法是比較常用的聚類演算法。
K-means演算法是一個迭代演算法,它主要做兩件事情:1.簇分配,2.移動聚類中心。
K-means演算法介紹:


如果存在一個沒有點分配給它的聚類中心,怎麼辦?通常做法是直接移除那個聚類中心。
舉例:如何設計S,M,L衣服型號

關於K-means的目標函式:

從目標函式優化的角度來看K-means演算法:

這個代價函式J也被稱作失真函式。
接下來,我們將討論如何隨機初始化,進而討論如果避免區域性最優。被推薦的初始化方法:

但可能陷入區域性最優,如下:

為了避免區域性最優,使用下列方法:

該演算法從100個不同的初始化中選出最好的一個,在K=2-10時效果很明顯,如果K很大,效果不是很明顯。
如何選擇合適的聚類類別個數K?可以看看肘部法則:

如果如左圖,那麼運用肘部法則取K=3,但大多數情況如右圖,所以該法則的應用場景有限。
選擇K的值還有一個方法:
通常聚類的應用場景是為了某些後面的用途,進而進行聚類,如果下游的用途能給你一個評價指標,那麼更好的方法是,看不同的聚類數量能為後面下游的目標提供多好的結果。
維數約減 (dimensionality reduction) :
主要用途:
1.資料壓縮
2.資料視覺化
目前這方面最流行的方法是PCA:

最小化投影誤差的思想!
PCA試圖尋找到一個低維平面,對資料進行投影,以便最小化投影誤差的平方,最小化每個點與投影后的對應點之間的距離的平方值。
PCA演算法實現:
首先需要在PCA之前進行資料預處理:

先計算出協方差矩陣Sigma,再求奇異值分解,取前K列。


之前講過PCA可以用做資料壓縮,那麼一個應用場景就是還原壓縮後的資料,即解壓縮。