
使用虛擬節點改進的一致性雜湊演算法
分散式儲存中的應用
在分散式儲存系統中,將資料分佈至多個節點的方式之一是使用雜湊演算法。假設初始節點數為 N,則傳統的對 N 取模的對映方式存在一個問題在於:當節點增刪,即 N 值變化時,整個雜湊表(Hash Table)需要重新對映,這便意味著大部分資料需要在節點之間移動。
因此現在普遍使用的是被稱為一致性雜湊(Consistent Hashing)的一類演算法。“一致性” 這個定語的意義在於:當增刪節點時,隻影響到與變動節點相鄰的一個或兩個節點,散列表的其他部分與原來保持一致。某種程度上可以將其理解為:一致性雜湊演算法的雜湊函式與節點數 N 無關。
其他地方對一致性雜湊配圖的時候,都會選擇一個圓環來解釋,但我個人感覺雜湊表更加直觀:

上圖左右分別表示增加一個 “節點 5” 前後的雜湊表,雜湊函式使用的是 md5 。md5 會根據 key 的值摘要出一個 128 bit 的雜湊值(校驗和),一般表示為一個 32 位的 16 進位制數。這裡我們取雜湊值第一位的範圍來將 key 對映到不同的節點,可以看到在拆分了 “節點 4” 的 md5 首位範圍後,只需要將 “節點 4” 原本資料的約一半移動到 “節點 5” 上去就可以了,其他三個節點並未受到影響。 <br />
負載均衡改進
但這裡其實仍有改進的空間。
問題在於,上面需要將 “節點 4” 的一半資料搬運到 “節點 5” 上,這個壓力會比較大。以一個節點存有 3TB 的資料、節點間網路為千兆網(但只允許搬運程序使用 25% 負載)來算,搬運完 1.5TB 的資料最少需要 (1.5TB 1024GB/TB
這兩個問題有一個公共的解決方法:新增的 “節點 5” 不只從 “節點 4” 搬運資料,而從所有其他節點(或子集)處搬運資料,同時還要繼續保持雜湊一致性。
這種想法的一個實現方式就是,使用虛擬節點(virtual nodes)。上面 md5 雜湊表實際可以分為兩段:
- 通過 md5 將 key 雜湊出一個 32 位的 16 進位制雜湊值
- 將這個雜湊值對映到某個物理節點
當使用虛擬節點時,我們保持第一段不變,但會在第二段將雜湊值對映到物理節點的過程中再插入一個虛擬節點中介軟體,從而將過程變為:
- 通過 md5 將 key 雜湊出一個 32 位的 16 進位制雜湊值
- 將這個雜湊值對映到一個虛擬節點
- 將這個虛擬節點對映到一個物理節點
新雜湊表的關鍵之處在於虛擬節點的數量比物理節點數多得多,甚至很多時候會將虛擬節點的數量設定為 “儘可能多”。這樣新雜湊表的前兩段就固定不變了,當增刪物理節點時,只是對虛擬節點進行必要的重新分配的過程。
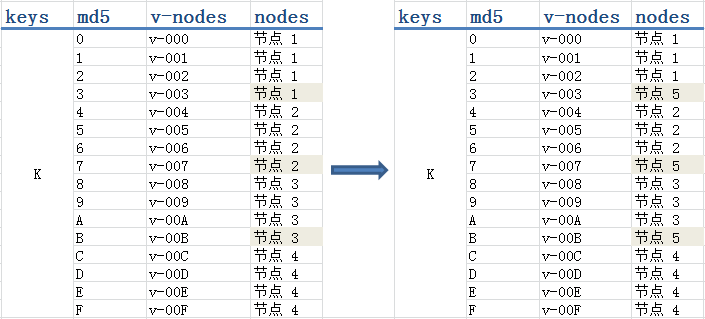
上圖中我們依 md5 值的首位劃分了 16 個虛擬節點,然後將它們對映到 4 個物理節點。(實際應用中,即使你當下只有 10 個物理節點,也大可以按 md5 的前三位劃分出 4096 個虛擬節點)當我們增加物理 “節點 5” 的時候,就從節點 1、2、3 處各拿一個虛擬節點放到 “節點 5” 中。這個過程,“節點 5” 既可以使用 100% 的網路頻寬來接收資料;新的雜湊表也實現了負載均衡。當然一致性也得到了保證。
這種使用虛擬節點的一致性雜湊演算法我看到國內有人管它叫分散式一致性雜湊(Distributed Consistent Hashing),但這個 “分散式” 叫法顯得有些不合適,因為這種改進只涉及到演算法的實現而與雜湊過程發生的位置無關,並且 google 上也找不到這種叫法。所以一般就稱改進的一致性雜湊(Improved Consistent Hashing)好了。或者,使用虛擬節點的一致性雜湊。
轉載自https://my.oschina.net/lionets/blog/288066