
Python下的自然語言處理利器-LTP語言技術平臺 pyltp 學習手札
1 什麼是pyltp
語言技術平臺(LTP) 是由 哈工大社會計算與資訊檢索研究中心 11
年的持續研發而形成的一個自然語言處理工具庫,其提供包括中文分詞、詞性標註、命名實體識別、依存句法分析、語義角色標註等豐富、
高效、精準的自然語言處理技術。LTP制定了基於XML的語言處理結果表示,並在此基礎上提供了一整套自底向上的豐富而且高效的中文語言處理模組(包括詞法、句法、語義等6項中文處理核心技術),以及基於動態連結庫(Dynamic
Link Library, DLL)的應用程式介面,視覺化工具,並且能夠以網路服務(Web Service)的形式進行使用。
預設上來說,ltp平臺是基於C++的,但是大家也都知道我是不用C++的,所以我看到了其python的版本,pyltp,於是拿來寫了個手札。
我目前主要用到的部分可能還是以中文分詞為主,其他後續加上(PS:因為我覺得之前那個不太喜歡)。
NLPIR 漢語分詞系統 (PyNLPIR) 學習手札
好了廢話不多說,一步一步來,讓我們先從安裝開始。
這次我首次安裝pyltp的平臺是windows 10(我的環境osx or windows10 or Ubuntu,一般nlp相關的都是osx或win上,平臺相關的都是Ubuntu) + python2.7
1 pyltp 安裝
1、使用Pip進行安裝
關於Pip,已經不用重複太多了,快速簡單,我也一直用,這裡也一樣。
$ pip install pyltp這裡說一下我遇到的問題,缺少Visual C++ 9.0:
Microsoft Visual C++ 9.0 is required (Unable to find vcvarsall.bat). Get it from
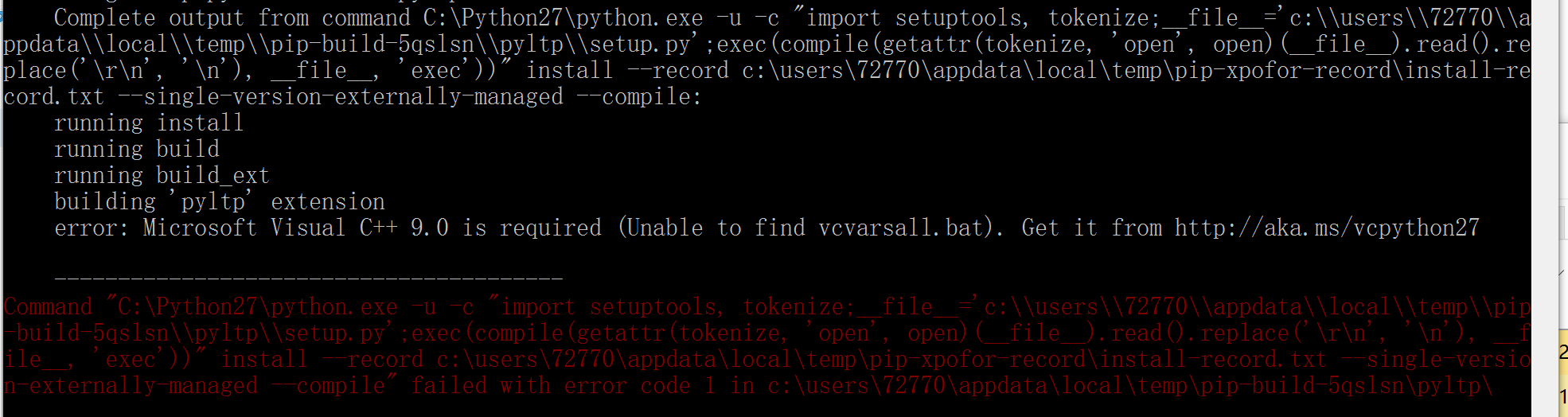
解決方式(2選1):
1、安裝一個Visual Studio 2008 只能是這個版本,網上說12,我的15都不行
2、安裝一個Micorsoft Visual C++ Compiler for Python 2.7,或者這個連結直接下載,但是可能會失效 安裝完成後,重新執行那個安裝指令就可以了
2、模型下載
安裝完成後,我們需要安裝pyltp的模型,從百度雲這裡下載 ,注意模型版本必須要和pynlp的版本對應
我寫文的時候,使用的是3.3.1,注意網盤裡面有個zip和tar兩種,選擇一個你能下載的就可以了
pyltp 版本:0.1.9 LTP 版本:3.3.2 模型版本:3.3.1
3 配置
當我們完成了安裝和模型下載後,就需要做一些相關的配置,保證pyltk可以使用到對應的模型
這裡所謂的配置,就是在程式碼中,需要預先load一下
1、將上述的模型壓縮包解壓到指定的資料夾
2、在使用時,使用類似的方式的載入模型,注意替換自己的模型地址
segmentor.load('/path/to/your/model') # 載入模型3 pyltk 使用
分句
分句,也就是將一片文字分割為獨立的句子,不需要載入模型的哦,我看了一下應該就是按照符號來分割的。
# -*- coding: utf-8 -*-
from pyltp import SentenceSplitter
#分句,也就是將一片文字分割為獨立的句子
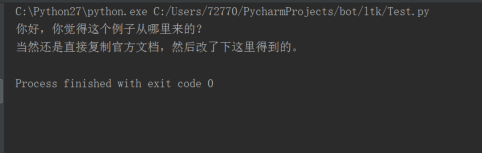
def sentence_splitter(sentence='你好,你覺得這個例子從哪裡來的?當然還是直接複製官方文件,然後改了下這裡得到的。'):
sents = SentenceSplitter.split(sentence) # 分句
print '\n'.join(sents)
#測試分句子
sentence_splitter()執行結果
分詞
關於分詞是什麼,就不用多說了,直接看。
注意分詞的模型預設是:cws.model
# -*- coding: utf-8 -*-
from pyltp import Segmentor
#分詞
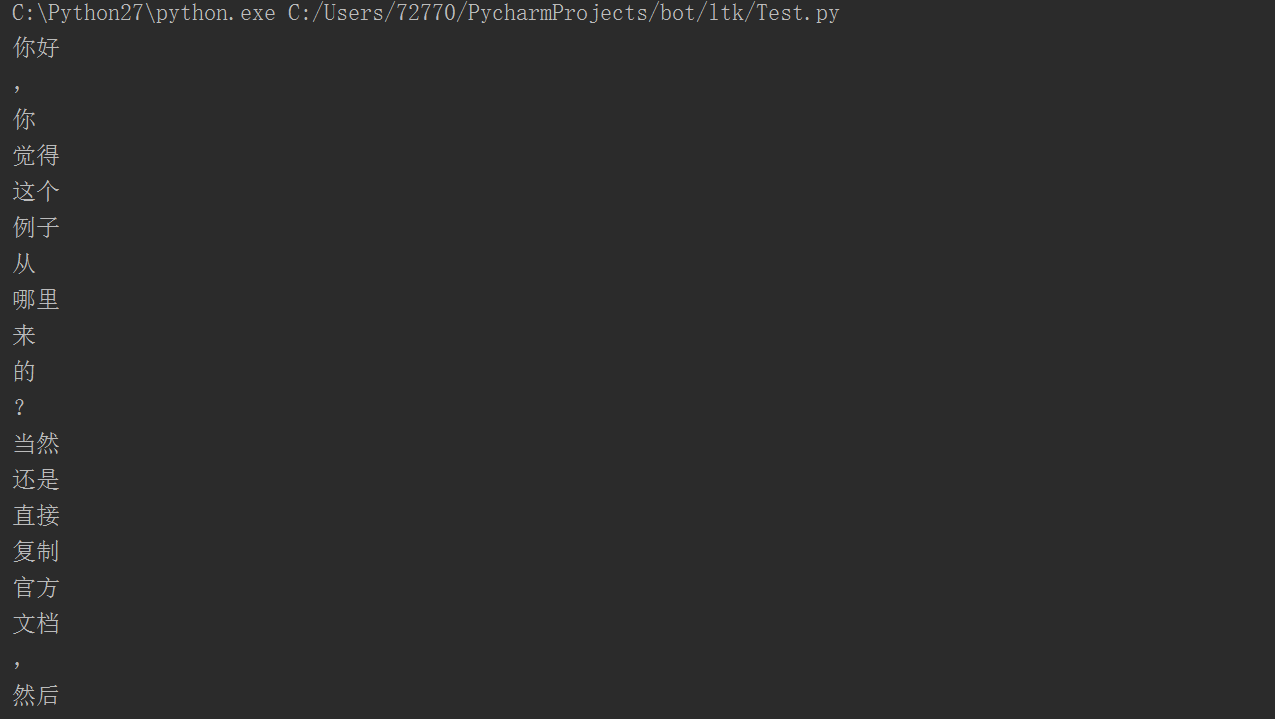
def segmentor(sentence='你好,你覺得這個例子從哪裡來的?當然還是直接複製官方文件,然後改了下這裡得到的。我的微博是MebiuW,轉載請註明來自MebiuW!'):
segmentor = Segmentor() # 初始化例項
segmentor.load('C:\\Users\\72770\\Documents\\Chatbot\\ltp-data-v3.3.1\\ltp_data\\cws.model') # 載入模型
words = segmentor.segment(sentence) # 分詞
#預設可以這樣輸出
# print '\t'.join(words)
# 可以轉換成List 輸出
words_list = list(words)
for word in words_list:
print word
segmentor.release() # 釋放模型
return words_list
#測試分詞
segmentor()執行結果
分詞-高階
注意此部分,我是直接複製了官方文件
以下程式碼中的XX模型,請自定替換為模型的地址!!!
pyltp 分詞支援使用者使用自定義詞典。分詞外部詞典本身是一個文字檔案(plain text),每行指定一個詞,編碼同樣須為 UTF-8,樣例如下所示
苯並芘
亞硝酸鹽示例如下
# -*- coding: utf-8 -*-
from pyltp import Segmentor
segmentor = Segmentor() # 初始化例項
segmentor.load_with_lexicon('模型地址, '使用者字典') # 載入模型
words = segmentor.segment('亞硝酸鹽是一種化學物質')
print '\t'.join(words)
segmentor.release()使用個性化分詞模型
個性化分詞是 LTP 的特色功能。個性化分詞為了解決測試資料切換到如小說、財經等不同於新聞領域的領域。 在切換到新領域時,使用者只需要標註少量資料。 個性化分詞會在原有新聞資料基礎之上進行增量訓練。 從而達到即利用新聞領域的豐富資料,又兼顧目標領域特殊性的目的。
pyltp 支援使用使用者訓練好的個性化模型。關於個性化模型的訓練需使用 LTP,詳細介紹和訓練方法請參考 個性化分詞 。
在 pyltp 中使用個性化分詞模型的示例如下
# -*- coding: utf-8 -*-
from pyltp import CustomizedSegmentor
customized_segmentor = CustomizedSegmentor() # 初始化例項
customized_segmentor.load('基本模型', '個性模型') # 載入模型
words = customized_segmentor.segment('亞硝酸鹽是一種化學物質')
print '\t'.join(words)
customized_segmentor.release()同時使用外部字典的話
# -*- coding: utf-8 -*-
from pyltp import CustomizedSegmentor
customized_segmentor = CustomizedSegmentor() # 初始化例項
customized_segmentor.load_with_lexicon('基本模型', '個性模型', '使用者字典') # 載入模型
words = customized_segmentor.segment('亞硝酸鹽是一種化學物質')
print '\t'.join(words)
customized_segmentor.release()#詞性標註
詞性標註也是我們經常遇到的任務,也不多解釋了
詞性標註需要輸入分詞後的結果,所以請先參考下之前的按個分詞部分,其返回的結果可以作為輸入直接標註
# -*- coding: utf-8 -*-
from pyltp import Segmentor
from pyltp import Postagger
#分詞
def segmentor(sentence='你好,你覺得這個例子從哪裡來的?當然還是直接複製官方文件,然後改了下這裡得到的。我的微博是MebiuW,轉載請註明來自MebiuW!'):
segmentor = Segmentor() # 初始化例項
segmentor.load('C:\\Users\\72770\\Documents\\Chatbot\\ltp-data-v3.3.1\\ltp_data\\cws.model') # 載入模型
words = segmentor.segment(sentence) # 分詞
#預設可以這樣輸出
# print '\t'.join(words)
# 可以轉換成List 輸出
words_list = list(words)
segmentor.release() # 釋放模型
return words_list
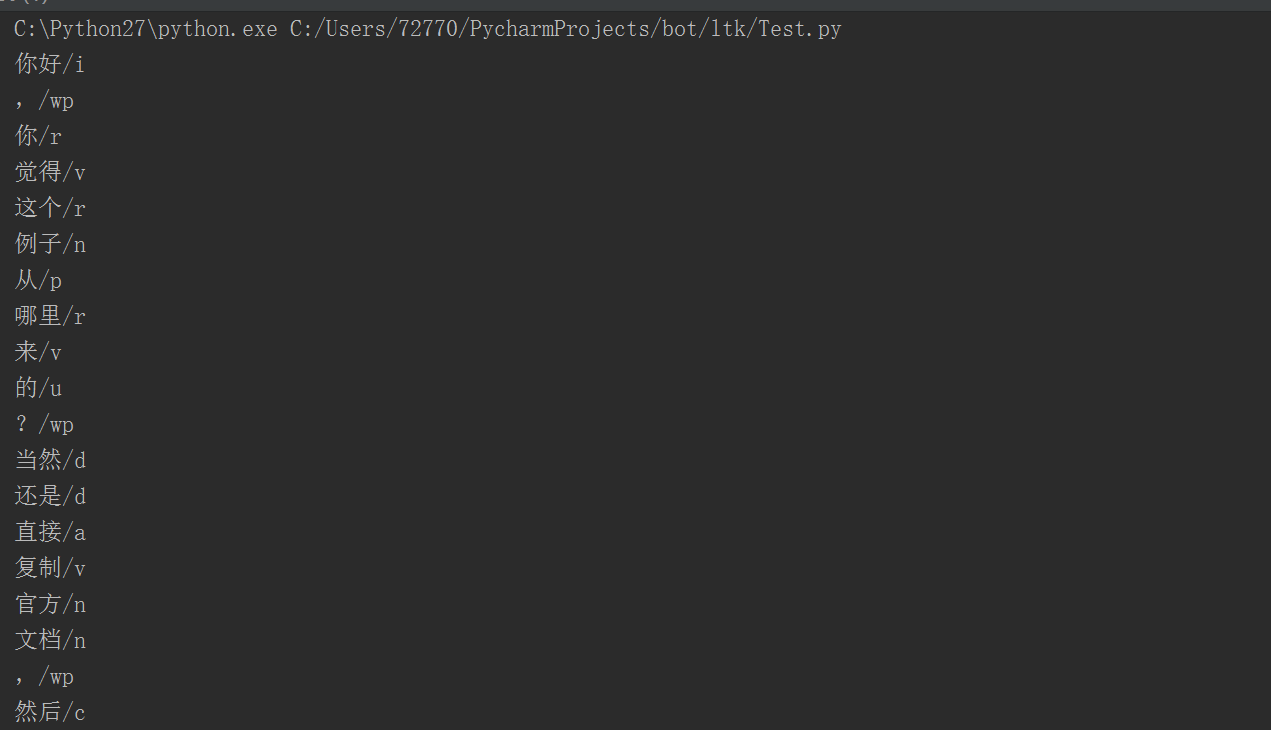
def posttagger(words=segmentor()):
postagger = Postagger() # 初始化例項
postagger.load('C:\\Users\\72770\\Documents\\Chatbot\\ltp-data-v3.3.1\\ltp_data\\pos.model') # 載入模型
postags = postagger.postag(words) # 詞性標註
for word,tag in zip(words,postags):
print word+'/'+tag
postagger.release() # 釋放模型
#測試標註
posttagger()執行結果: 前面是詞語,後面是詞性,詞性的表述請參照這裡
命名實體識別
命名實體識別,主要是hi識別一些人名,地名,機構名等。
需要前面分詞和詞性標註作為輸入
#注意,從這裡開始,因為牽扯到的程式碼比較多,所以不是完成的程式碼,只是片段,要保證正常執行,請參照最後的完整程式碼附錄
# -*- coding: utf-8 -*-
from pyltp import NamedEntityRecognizer
def ner(words, postags):
recognizer = NamedEntityRecognizer() # 初始化例項
recognizer.load('C:\\Users\\72770\\Documents\\Chatbot\\ltp-data-v3.3.1\\ltp_data\\ner.model') # 載入模型
netags = recognizer.recognize(words, postags) # 命名實體識別
for word, ntag in zip(words, netags):
print word + '/' + ntag
recognizer.release() # 釋放模型
return netags
#測試分句子
#sentence_splitter()
#測試分詞
words = segmentor('我家在昆明,我現在在北京上學。中秋節你是否會想到李白?')
#測試標註
tags = posttagger(words)
#命名實體識別
ner(words,tags)執行結果
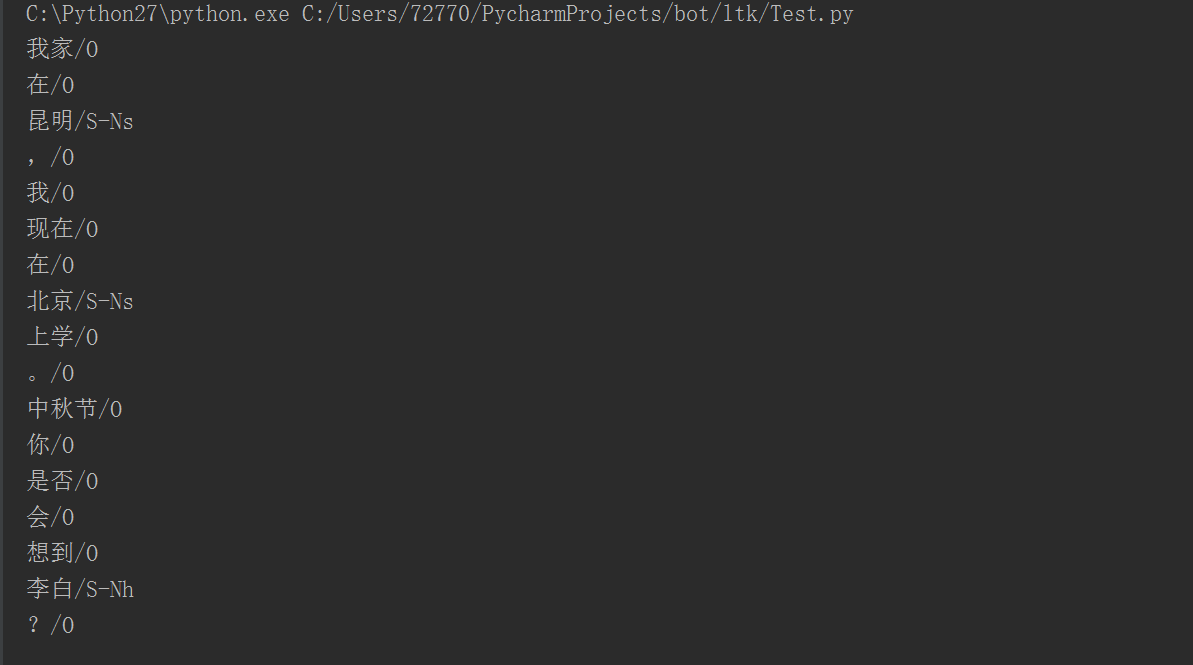
命名實體的參照標記,也是請看這裡
依存句法分析
依存句法依舊需要之前的兩個輸入,words 和 postags 分別為分詞和詞性標註的結果。
arc.head 表示依存弧的父節點詞的索引,arc.relation 表示依存弧的關係。其具體的表述看這裡
# -*- coding: utf-8 -*-
from pyltp import Parser
def parse(words, postags):
parser = Parser() # 初始化例項
parser.load('C:\\Users\\72770\\Documents\\Chatbot\\ltp-data-v3.3.1\\ltp_data\\parser.model') # 載入模型
arcs = parser.parse(words, postags) # 句法分析
print "\t".join("%d:%s" % (arc.head, arc.relation) for arc in arcs)
parser.release() # 釋放模型
#測試分句子
#sentence_splitter()
#測試分詞
words = segmentor('我家在昆明,我現在在北京上學。中秋節你是否會想到李白?還有,微博是MebiuW')
#測試標註
tags = posttagger(words)
#依存句法識別
parse(words,tags)執行結果

語義角色標註
arg.name 表示語義角色關係,arg.range.start 表示起始詞位置,arg.range.end 表示結束位置。
# -*- coding: utf-8 -*-
from pyltp import SementicRoleLabeller
def role_label(words, postags, netags, arcs):
labeller = SementicRoleLabeller() # 初始化例項
labeller.load('C:\\Users\\72770\\Documents\\Chatbot\\ltp-data-v3.3.1\\ltp_data\\srl') # 載入模型
roles = labeller.label(words, postags, netags, arcs) # 語義角色標註
for role in roles:
print role.index, "".join(
["%s:(%d,%d)" % (arg.name, arg.range.start, arg.range.end) for arg in role.arguments])
labeller.release() # 釋放模型
#測試分句子
#sentence_splitter()
#測試分詞
words = segmentor('我家在昆明,我現在在北京上學。中秋節你是否會想到李白?還有,微博是MebiuW')
#測試標註
tags = posttagger(words)
#命名實體識別
netags = ner(words,tags)
#依存句法識別
arcs = parse(words,tags)
#j角色標註
roles = role_label(words,tags,netags,arcs)
執行結果:
結語
有點累,突然寫不動了,就先寫這些吧,有問題我們評論或者新浪微博@MebiuW 交流
參考
參考本篇完整程式碼
可能有些列印有點雜亂,見諒
# -*- coding: utf-8 -*-
#作者:MebiuW
#微博:@MebiuW
#python 版本:2.7
#時間 2016/9/10
from pyltp import SentenceSplitter
from pyltp import Segmentor
from pyltp import Postagger
from pyltp import SementicRoleLabeller
from pyltp import NamedEntityRecognizer
from pyltp import Parser
#分詞
def segmentor(sentence='你好,你覺得這個例子從哪裡來的?當然還是直接複製官方文件,然後改了下這裡得到的。我的微博是MebiuW,轉載請註明來自MebiuW!'):
segmentor = Segmentor() # 初始化例項
segmentor.load('C:\\Users\\72770\\Documents\\Chatbot\\ltp-data-v3.3.1\\ltp_data\\cws.model') # 載入模型
words = segmentor.segment(sentence) # 分詞
#預設可以這樣輸出
print '\t'.join(words)
# 可以轉換成List 輸出
words_list = list(words)
segmentor.release() # 釋放模型
return words_list
def posttagger(words):
postagger = Postagger() # 初始化例項
postagger.load('C:\\Users\\72770\\Documents\\Chatbot\\ltp-data-v3.3.1\\ltp_data\\pos.model') # 載入模型
postags = postagger.postag(words) # 詞性標註
for word,tag in zip(words,postags):
print word+'/'+tag
postagger.release() # 釋放模型
return postags
#分句,也就是將一片文字分割為獨立的句子
def sentence_splitter(sentence='你好,你覺得這個例子從哪裡來的?當然還是直接複製官方文件,然後改了下這裡得到的。我的微博是MebiuW,轉載請註明來自MebiuW!'):
sents = SentenceSplitter.split(sentence) # 分句
print '\n'.join(sents)
#命名實體識別
def ner(words, postags):
recognizer = NamedEntityRecognizer() # 初始化例項
recognizer.load('C:\\Users\\72770\\Documents\\Chatbot\\ltp-data-v3.3.1\\ltp_data\\ner.model') # 載入模型
netags = recognizer.recognize(words, postags) # 命名實體識別
for word, ntag in zip(words, netags):
print word + '/' + ntag
recognizer.release() # 釋放模型
return netags
#依存語義分析
def parse(words, postags):
parser = Parser() # 初始化例項
parser.load('C:\\Users\\72770\\Documents\\Chatbot\\ltp-data-v3.3.1\\ltp_data\\parser.model') # 載入模型
arcs = parser.parse(words, postags) # 句法分析
print "\t".join("%d:%s" % (arc.head, arc.relation) for arc in arcs)
parser.release() # 釋放模型
return arcs
#角色標註
def role_label(words, postags, netags, arcs):
labeller = SementicRoleLabeller() # 初始化例項
labeller.load('C:\\Users\\72770\\Documents\\Chatbot\\ltp-data-v3.3.1\\ltp_data\\srl') # 載入模型
roles = labeller.label(words, postags, netags, arcs) # 語義角色標註
for role in roles:
print role.index, "".join(
["%s:(%d,%d)" % (arg.name, arg.range.start, arg.range.end) for arg in role.arguments])
labeller.release() # 釋放模型
#測試分句子
print('******************測試將會順序執行:**********************')
sentence_splitter()
print('###############以上為分句子測試###############')
#測試分詞
words = segmentor('我家在昆明,我現在在北京上學。中秋節你是否會想到李白?還有,微博是MebiuW')
print('###############以上為分詞測試###############')
#測試標註
tags = posttagger(words)
print('###############以上為詞性標註測試###############')
#命名實體識別
netags = ner(words,tags)
print('###############以上為命名實體識別測試###############')
#依存句法識別
arcs = parse(words,tags)
print('###############以上為依存句法測試###############')
#角色標註
roles = role_label(words,tags,netags,arcs)
print('###############以上為角色標註測試###############')