2.Spark Streaming:基本工作原理
Spark Streaming簡介
Spark Streaming是Spark Core API的一種擴充套件,它可以用於進行大規模、高吞吐量、容錯的實時資料流的處理。它支援從很多種資料來源中讀取資料,比如Kafka、Flume、Twitter、ZeroMQ、Kinesis或者是TCP Socket。並且能夠使用類似高階函式的複雜演算法來進行資料處理,比如map、reduce、join和window。處理後的資料可以被儲存到檔案系統、資料庫、Dashboard等儲存中。

Spark Streaming基本工作原理
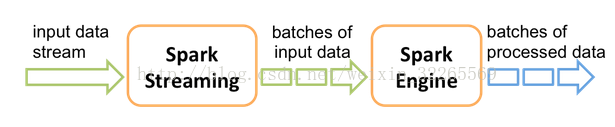
Spark Streaming內部的基本工作原理如下:接收實時輸入資料流,然後將資料拆分成多個batch,比如每收集1秒的資料封裝為一個batch,然後將每個batch交給Spark的計算引擎進行處理,最後會生產出一個結果資料流,其中的資料,也是由一個一個的batch所組成的。
DStream(一)
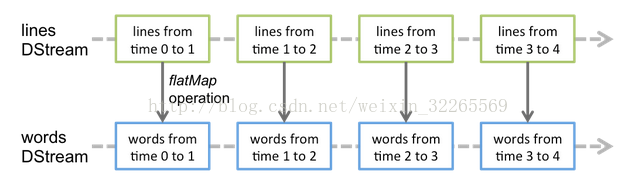
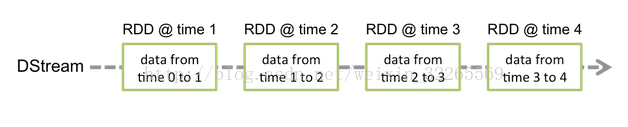
Spark Streaming提供了一種高階的抽象,叫做DStream,英文全稱為Discretized Stream,中文翻譯為“離散流”,它代表了一個持續不斷的資料流。DStream可以通過輸入資料來源來建立,比如Kafka、Flume和Kinesis;也可以通過對其他DStream應用高階函式來建立,比如map、reduce、join、window。
DStream的內部,其實一系列持續不斷產生的RDD。RDD是Spark Core的核心抽象,即,不可變的,分散式的資料集。DStream中的每個RDD都包含了一個時間段內的資料。
DStream(二)
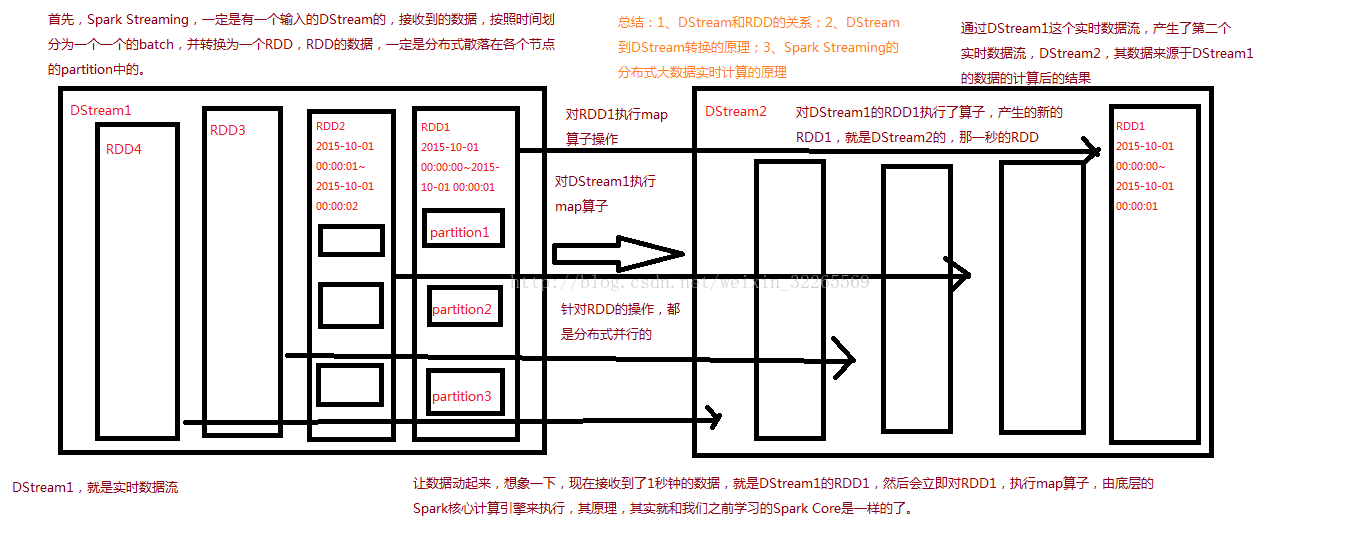
對DStream應用的運算元,比如map,其實在底層會被翻譯為對DStream中每個RDD的操作。比如對一個DStream執行一個map操作,會產生一個新的DStream。但是,在底層,其實其原理為,對輸入DStream中每個時間段的RDD,都應用一遍map操作,然後生成的新的RDD,即作為新的DStream中的那個時間段的一個RDD。底層的RDD的transformation操作,其實,還是由Spark Core的計算引擎來實現的。Spark Streaming對Spark
Core進行了一層封裝,隱藏了細節,然後對開發人員提供了方便易用的高層次的API。