
5.1 深度學習序列模型筆記
阿新 • • 發佈:2019-02-19
第五課 序列模型(Sequence Models)
第一週 迴圈序列模型(Recurrent Neural Networks)
1.1 為什麼選擇序列模型?(Why Sequence Models)
迴圈神經網路(RNN)
在進行語音識別時,給定一個 輸入音訊片段, 要求輸出 對應的文字記錄
這個例子裡輸入和輸出資料都是序列模型,因為 是一個按時播放的音訊片段,輸出 是一系列單詞
1.2 數學符號(Notation)
如果你想建立一個序列模型,它的輸入語句是這樣的:
Harry Potter and Herminoe Granger invented a new spell
-
這個輸入資料是 9 個單片語成的序列,所以最終我們會有 9 個特徵集和 來 表示這9個單詞
按照序列中的位置進行索引:,我們將用來索引這個序列的中間位置
-
輸出資料也一樣
用表示輸出資料
-
用表示輸入序列的長度,表示輸出序列的長度
-
表示第個樣本,所以訓練樣本i的序列中第t個元素用 表示
-
如果是序列長度,那麼你的訓練集裡不同的訓練樣本就會有不同的長度,所以就代表第個訓練樣本的輸入序列長度; 表示第個訓練樣本的輸出序列的長度
所以這個例子中,,但如果另一個樣本是由 15 個單片語成的句子,那麼多餘這個訓練樣本來說,
怎樣表示一個序列裡單獨的單詞,實際代表什麼?
- 如果想要表示一個句子裡的單詞,第一件事情是做一張詞表,也稱詞典
- 用one-hot表示詞典裡的每個單詞

舉個例子,表示 Harry 這個單詞,它就是一個第1075行是1,其餘值都是0的向量。因為 Harry 在這個詞典裡的位置
- 所以這種表示方法中,指代句子裡的任意詞,它就是 one-hot 向量
目的是用這樣的表示方式表示,用序列模型在 和 目標輸出 之間建立一個對映
- 如果遇到一個不在詞表中的單詞,答案就是建立一個新標記, 也就是一個叫做 Unknow Word的偽單詞,用作為標記
1.3 迴圈神經網路模型(Recurrent Neural Network Model)
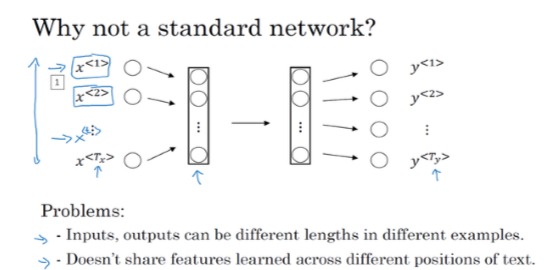
怎樣建立一個神經網路學習到的對映?
使用標準神經網路,將它們輸入到標準神經網路中,經過一些隱藏層,最終會輸出9個為0/1的值,它表明每個輸入單詞是否是人名的一部分。
但這樣做有兩個問題:
- 輸入和輸出資料在不同例子中有不同的長度,不是所有的例子都有著同樣的 輸入長度 或者 同樣的輸出長度;
- 這樣單純的神經網路結構,它並不共享從文字的不同位置學到的特徵。具體說,如果神經網路學習到了再位置 1 出現的 Harry 可能是人名的一部分,那麼如果 Harry 出現在其他位置,比如時,它就不奏效。
- 之前我們提到過那些:都是 10,000 維的 one-hot 向量,因此這回事十分龐大的輸入層。如果總的輸入大小是 最大單詞書x10000,那麼第一層的權重矩陣就會有著巨量的引數

- 從左到右的順序讀這個句子,第一個單詞,也就是,要做的就是將第一個詞輸入一個神經層, 可以讓神經網路嘗試預測輸出,判斷是否是人名的一部分
- 迴圈神經網路讀到句子中的第二個單詞時,假設是,它不是僅用就預測出,它會輸入一些來自時間步 1 的資訊;具體說:時間步1的啟用值會傳遞到時間步 2
- 在下一個時間步,迴圈神經網路輸入單詞,然後它預測出了預測結果…等等抑制到最後一個時間步,輸入了,然後輸出了
- 至少在這個例子中,如果不相等,這個結構需要作出一些改變
- 所以在每一個時間步中,迴圈神經網路傳遞一個啟用值到下一個時間步中用於計算
- 迴圈神經網路是從做到右掃描資料的,同時每個時間步的引數都是 共享的,我們用**表示管理著到隱藏層的連線的一系列引數,每個時間步使用著相同的引數**。
- 而啟用值,也就是水平聯絡是由引數決定的,同時每個時間步使用的都是相同的引數。
- 輸出結果由決定

詳細講述這些引數如何起作用
在這個迴圈神經網路中,意思是在預測時候,不僅要使用的資訊,還要使用來自和的資訊
前向傳播過程

-
首先輸入,它是一個零向量
-
接著計算前向傳播過程,先計算啟用值,然後再計算