
selenium+python 自動化框架總結【一】
阿新 • • 發佈:2019-02-19
學自動化框架一段時間了,斷斷續續,今天在這裡回顧總結一下
整個測試過程是這樣的:首先通過從外部檔案中讀取測試資料,測試物件元素,使用selenium在瀏覽器中模擬手工操作對系統進行必要的業務測試,測試完成後生成測試報告並郵件傳送給測試人員
1.環境準備
eclipse :需安裝pydev、testng外掛
python :安裝python完成後,需 pip下安裝selenium:命令: pip install selenium
我現在的環境:eclipse【 Neon.3 Release (4.6.3)】+JDK1.8+python3.6.3+pydev 6.4.4+selenium3.8.1
2.eclipse建立python專案
2.1首先,建立一個python專案,隨便取個名字:XXXXXXX
2.2建立專案會用到的資料夾,命名如下
專案目錄截圖:
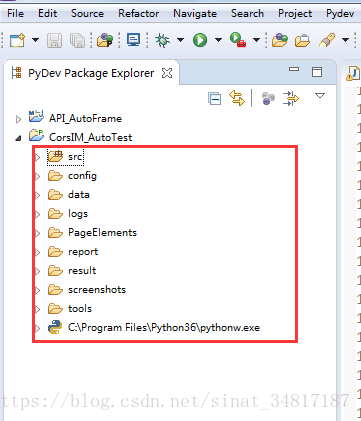
對各個資料夾解釋下:
3.測試資料準備
3.1 測試元素表
瀏覽器中開啟要測試的頁面,使用firebug或firepath獲取元素定位的方法,寫入表格中。
在工作路徑PageElement下新建excle表:login.xlsx,sheet名為:登陸
示例如下:

3.2測試資料表
這裡,在data資料夾下新建一個表,表中內容為你需要輸入的資料
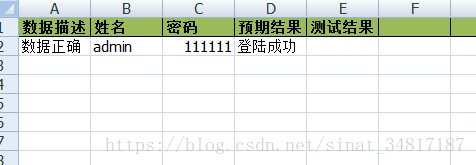
4.測試主框架的搭建
到這裡,才是重點
4.1框架目錄
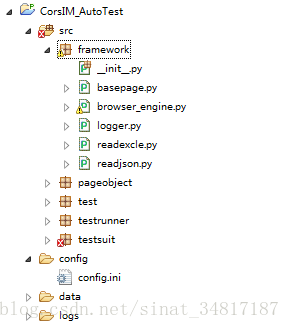
每個包的解釋:
4.2框架之—–瀏覽器引擎配置
4.2.1.config下新建:config.ini
檔案內容如下:
# this is config file, only store browser type and server URL
[browserType]
browserName = Firefox
#browserName = Chrome
#browserName = IE
[testServer]
URL = http://XXXXXXXXXXXXXXX #輸入你要測得url地址
#URL = http://www.google.com 4.2.2 framework下新建browser_engine.py
封裝對瀏覽器的操作
from selenium import webdriver
import configparser
import sys,os
class Browser(object):
# 開啟瀏覽器
def open_browser(self):
config = configparser.ConfigParser()
dir = os.path.abspath('.').split('src')[0]
config.read( dir+"/config/config.ini")
browser = config.get("browserType", "browserName")
logger.info("You had select %s browser." % browser)
url = config.get("testServer", "URL")
if browser == "Firefox":
self.driver = webdriver.Firefox()
elif browser == "Chrome":
self.driver = webdriver.Chrome()
elif browser == "IE":
self.driver = webdriver.Ie()
self.driver.set_window_size(1920,1080) #解析度
#self.driver.maximize_window()#最大化
self.driver.get(url)
return self.driver
# 開啟url站點
def open_url(self, url):
self.driver.get(url)
# 關閉瀏覽器
def quit_browser(self):
self.driver.quit()
# 瀏覽器前進操作
def forward(self):
self.driver.forward()
# 瀏覽器後退操作
def back(self):
self.driver.back()
# 隱式等待
def wait(self, seconds):
self.driver.implicitly_wait(seconds)
4.3 框架之—–日誌配置
4.3.1 framework下新建logger.py
import logging
import time
import os
class Logger(object):
def __init__(self, logger):
'指定儲存日誌的檔案路徑,日誌級別,以及呼叫檔案,將日誌存入到指定的檔案中'
# 建立一個logger
self.logger = logging.getLogger(logger)
#self.logger.setLevel(logging.DEBUG)
# 建立一個handler,用於寫入日誌檔案
rq = time.strftime('%Y%m%d%H%M', time.localtime(time.time()))
log_dir = os.path.abspath('.').split('src')[0] + '/logs/'
log_name = log_dir + rq + '.log'
fh = logging.FileHandler(log_name)
fh.setLevel(logging.INFO)
# 再建立一個handler,用於輸出到控制檯
ch = logging.StreamHandler()
#ch.setLevel(logging.INFO)
ch.setLevel(logging.ERROR)
# 定義handler的輸出格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
# 給logger新增handler
self.logger.addHandler(fh)
self.logger.addHandler(ch)
def getlog(self):
return self.logger
4.3.2 其他類中引用日誌類
在其他類前面先匯入日誌類:
from framework.logger import Logger
logger = Logger("XXXXX頁面").getlog()
在你想列印日誌的地方加上:
logger.info(XXXXXX)
logger.error(XXXXX)
#可參考下面的類4.4框架之—–selenium二次封裝
framework下新建basepage.py封裝對頁面的基本操作,其中包含:查詢元素、點選元素、輸入、下拉選擇、切換iframe,執行js等
import time
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.action_chains import ActionChains
import os.path
from framework.logger import Logger
from selenium.webdriver.support.select import Select
from selenium.webdriver.common.keys import Keys
from random import choice
logger = Logger("BasePage").getlog()
class BasePage(object):
"定義一個頁面基類,讓所有頁面都繼承這個類,封裝一些常用的頁面操作方法到這個類"
def __init__(self, driver):
self.driver = driver
# 查詢元素
def find_element(self, selector):
element = ''
if '=>' not in selector:
return self.driver.find_element_by_id(selector)
selector_by = selector.split('=>')[0]
selector_value = selector.split('=>')[1]
if selector_by == 'id':
try:
element = self.driver.find_element_by_id(selector_value)
logger.info("Had find the element \' %s \' successful "
"by %s via value: %s " % (element.text, selector_by, selector_value))
except NoSuchElementException as e:
logger.error("NoSuchElementException: %s" % e)
elif selector_by == "n" or selector_by == 'name':
element = self.driver.find_element_by_name(selector_value)
elif selector_by == 'css_selector':
element = self.driver.find_element_by_css_selector(selector_value)
elif selector_by == 'classname':
element = self.driver.find_element_by_class_name(selector_value)
elif selector_by == "l" or selector_by == 'link_text':
element = self.driver.find_element_by_link_text(selector_value)
elif selector_by == "p" or selector_by == 'partial_link_text':
element = self.driver.find_element_by_partial_link_text(selector_value)
elif selector_by == "t" or selector_by == 'tag_name':
element = self.driver.find_element_by_tag_name(selector_value)
elif selector_by == "x" or selector_by == 'xpath':
try:
element = self.driver.find_element_by_xpath(selector_value)
logger.info("Had find the element \' %s \' successful "
"by %s via value: %s " % (element.text, selector_by, selector_value))
except NoSuchElementException as e:
logger.error("NoSuchElementException: %s" % e)
elif selector_by == "s" or selector_by == 'selector_selector':
element = self.driver.find_element_by_css_selector(selector_value)
else:
raise NameError("Please enter a valid type of targeting elements.")
return element
# 輸入
def input(self, selector, text):
el = self.find_element(selector)
try:
el.clear()
el.send_keys(text)
logger.info("Had type \' %s \' in inputBox" % text)
except NameError as e:
logger.error("Failed to type in input box with %s" % e)
@staticmethod
def sleep(seconds):
time.sleep(seconds)
logger.info("Sleep for %d seconds" % seconds)
# 點選
def click(self, selector):
el = self.find_element(selector)
try:
el.click()
#logger.info("The element \' %s \' was clicked." % el.text)
except NameError as e:
logger.error("Failed to click the element with %s" % e)
# 切到iframe
def switch_frame(self):
iframe = self.find_element('classname=>embed-responsive-item')
try:
self.driver.switch_to_frame(iframe)
# logger.info("The element \' %s \' was clicked." % iframe.text)
except NameError as e:
logger.error("Failed to click the element with %s" % e)
# 處理標準下拉選擇框,隨機選擇
def select(self, id):
select1 = self.find_element(id)
try:
options_list=select1.find_elements_by_tag_name('option')
del options_list[0]
s1=choice(options_list)
Select(select1).select_by_visible_text(s1.text)
logger.info("隨機選的是:%s" % s1.text)
except NameError as e:
logger.error("Failed to click the element with %s" % e)
# 執行js
def execute_js(self, js):
self.driver.execute_script(js)
# 模擬回車鍵
def enter(self, selector):
e1 = self.find_element(selector)
e1.send_keys(Keys.ENTER)
# 模擬滑鼠左擊
def leftclick(self, element):
#e1 = self.find_element(selector)
ActionChains(self.driver).click(element).perform()
# 截圖,儲存在根目錄下的screenshots
def take_screenshot(self):
screen_dir = os.path.dirname(os.path.abspath('../..')) + '/screenshots/'
rq = time.strftime('%Y%m%d%H%M%S', time.localtime(time.time()))
screen_name = screen_dir + rq + '.png'
try :
self.driver.get_screenshot_as_file(screen_name)
logger.info("Had take screenshot and saved!")
except Exception as e:
logger.error("Failed to take screenshot!", format(e))
def isElementExist(self,xpath):
flag=True
driver=self.driver
try:
driver.find_element_by_xpath(xpath)
return flag
except:
flag=False
return flag
4.5框架之—–讀表操作封裝
framework下新建readexcle.py,主要獲取表中的資料
需先pip安裝:xlrd
import xlrd
class ReadExcle(object):
'''
classdoc
'''
def __init__(self,file,tag='True'):
self.file=file
self.tag=tag
'''
輸入引數,返回某個sheet列表中的所有值
sheetname:excel檔案的具體sheet名稱
n:開始行數,從第n行開始讀
num:讀取num行
'''
def read(self,sheetname,n=1,num=1000):#i,sheet索引
ExcelFile = xlrd.open_workbook(self.file)
table = ExcelFile.sheet_by_name(sheetname)
nrows = table.nrows #行數
ncols = table.ncols #列數
j = 0 #迴圈次數
for row in range(1,nrows):
j+=1
line = []
if self.tag == 'True':
for col in range(0,ncols):
line.append(table.cell(row,col).value)
yield line
elif self.tag == 'False':
if j >= n and j< n+num:
for col in range(0,ncols):
line.append(table.cell(row,col).value)
yield line
'''
讀取頁面元素表
list1 頁面元素路徑列表
list2 頁面元素js列表
'''
def get(self,sheetname):
ExcelFile=xlrd.open_workbook(self.file)
sheet=ExcelFile.sheet_by_name(sheetname)#'Sheet1'
nrows = sheet.nrows #總行數
list0=[]#元素名稱列表
list1=[]#元素路徑列表
list2=[]#js列表
for i in range(1,nrows):#i為行數
if sheet.row(i)[2].value != 'null':
r1=sheet.row(i)[2].value
r2=sheet.row(i)[3].value
list0.append(sheet.row(i)[0].value)
list1.append(r1+'=>'+r2)
dict1=dict(zip(list0,list1))
else:
list2.append(sheet.row(i)[3].value)
return dict1,list2
'''
返回excel檔案具體sheet的具體某個單元格的值
i,j為單元格所在位置
'''
def read_1(self,sheetname,i,j):
ExcelFile = xlrd.open_workbook(self.file)
table = ExcelFile.sheet_by_name(sheetname)
#print(table.cell(1,0).value)
return table.cell(i,j).value
'''
讀取給定列數,如讀取該表中第3列~5列
'''
def read_ncols(self,sheetname,ncols,n=1,num=1000):#i,sheet索引
ExcelFile = xlrd.open_workbook(self.file)
table = ExcelFile.sheet_by_name(sheetname)
nrows = table.nrows #行數
ncols = table.ncols #列數
j = 0 #迴圈次數
for row in range(1,nrows):
j+=1
line = []
if self.tag == 'True':
for col in range(0,ncols):
line.append(table.cell(row,col).value)
yield line
elif self.tag == 'False':
if j >= n and j< n+num:
for col in range(0,ncols):
line.append(table.cell(row,col).value)
yield line