
HotSpot關聯規則演算法(1)-- 挖掘離散型資料
提到關聯規則演算法,一般會想到Apriori或者FP,一般很少有想到HotSpot的,這個演算法不知道是應用少還是我查資料的手段太low了,在網上只找到很少的內容,這篇http://wiki.pentaho.com/display/DATAMINING/HotSpot+Segmentation-Profiling ,大概分析了一點,其他好像就沒怎麼看到了。比較好用的演算法類軟體,如weka,其裡面已經包含了這個演算法,在Associate--> HotSpot裡面即可看到,執行演算法介面一般如下:
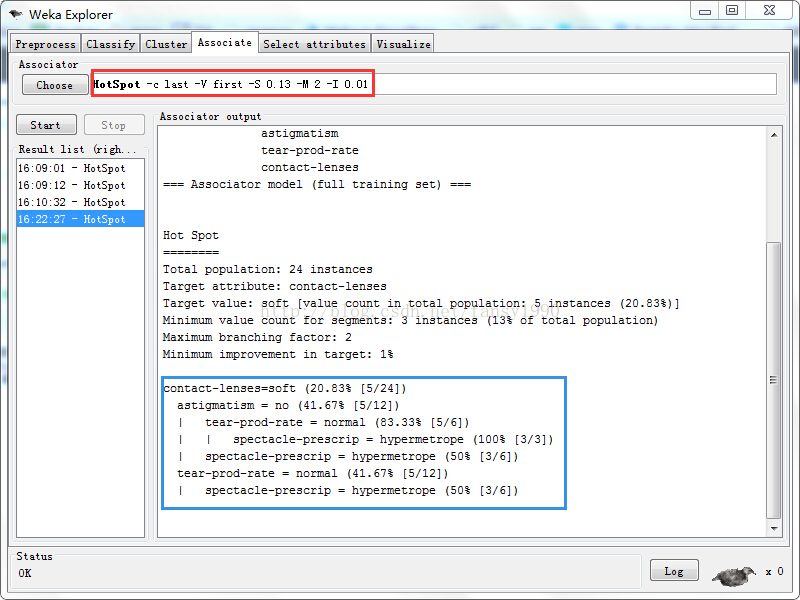
其中,紅色方框裡面為設定的引數,如下:
-c last ,表示目標所在的目標所在的列,last表示最後一列,也是是數值,表示第幾列;
-V first, 表示目標列的某個狀態值下標值(這裡可以看出目標列應該是離散型),first表示第0個,可以是數值型;
-S 0.13,最小支援度,裡面會乘以樣本總數得到一個數值型的支援度;
-M 2 , 最大分指數;
-I 0.01 , 在weka裡面解釋為Minimum improvement in target value,不知道是否傳統的置信度一樣;
相關說明:本篇相關程式碼參考weka裡面的HotSpot演算法的具體實現,本篇只分析離散型資料,程式碼可以在(http://download.csdn.net/detail/fansy1990/8488971)下載。
1. 資料:
這個資料格式是參考weka裡面的,加入最前面的5行是因為需要把各個屬性進行編碼,所以提前拿到屬性的各個狀態,方便後續操作;@attribute age {young, pre-presbyopic, presbyopic} @attribute spectacle-prescrip {myope, hypermetrope} @attribute astigmatism {no, yes} @attribute tear-prod-rate {reduced, normal} @attribute contact-lenses {soft, hard, none} young,myope,no,reduced,none young,myope,no,normal,soft young,myope,yes,reduced,none 。。。 presbyopic,hypermetrope,yes,normal,none
2. 單個節點定義:
public class HSNode { private int splitAttrIndex; // 屬性的下標 private int attrStateIndex; // 屬性state的下標 private int allCount ; // 當前資料集的個數 private int stateCount ; // 屬性的state的個數 private double support; // 屬性的支援度 private List<HSNode> chidren; public HSNode(){}}
splitAttrIndex 即對應屬性astigmatism的下標(應該是第2個,從0開始);attrStateIndex 則對應這個屬性的下標,即no的下標(這裡應該是0);allCount即12,stateCount即5,support 對應41.57%(即5/12的值);children即其孩子節點;(這裡的下標即是從檔案的前面幾行編碼得到的,比如屬性age為第一個屬性,編碼為0,young為其第一個狀態,編碼為0);
3. 演算法虛擬碼,(文字描述,太不專業了,如果要看,就將就看?)
1. 建立根節點;
2. 建立孩子節點;
2.1 針對所有資料,計算每列的每個屬性的’支援度‘support,
if support>= MINSUPPORT
把該列的當前屬性加入潛在的孩子節點列表;
end
2.2 針對潛在孩子節點列表遍歷
if (!當前節點產生的規則序in全域性規則序列)
把當前節點加入孩子節點列表;
把當前節點產生的規則加入全域性規則中;
end
2.3 遍歷孩子節點列表
針對當前節點,返回到2,進行遞迴;
4. 程式碼關鍵步驟具體實現:
4.1 資料讀取及初始化:
1) 讀取檔案的前面幾行,初始化兩個變數,attributes和attributeStates ,分別對應所有的屬性和屬性的各個狀態;
while ((tempString = reader.readLine()) != null) {
// 第一行資料是標題
if(tempString.indexOf(HSUtils.FILEFORMAT)==0){
String attr = tempString.substring(HSUtils.FILEFORMAT.length()
, tempString.indexOf("{")).trim();
String[] attrStates =tempString.substring(tempString.indexOf("{")+1,
tempString.indexOf("}")).split(",");
for(int i=0;i<attrStates.length;i++){
attrStates[i]=attrStates[i].trim();
}
attrList.add( attr);
line++;
this.attributeStates.put(attr, attrStates);
continue;
}
if(flag){
this.attributes= new String[line];
attrList.toArray(this.attributes);// 複製值到陣列中
flag=false;
}
String[] tempStrings = tempString.split(splitter);
lists.add(strArr2IntArr(tempStrings));
} /**
* String 陣列轉為int陣列
* @param sArr
* @return
* @throws Exception
*/
private int[] strArr2IntArr(String[] sArr) throws Exception{
int[] iArr = new int[sArr.length];
for(int i=0;i<sArr.length;i++){
iArr[i]= getAttrCode(sArr[i],i);
}
return iArr;
}
/**
* 獲得第attrIndex屬性的attrState的編碼
* @param attrState
* @param attrIndex
* @return
* @throws Exception
*/
private int getAttrCode(String attrState,int attrIndex) throws Exception{
String[] attrStates = attributeStates.get(attributes[attrIndex]);
for(int i=0;i<attrStates.length;i++){
if(attrState.equals(attrStates[i])){
return i;
}
}
throw new Exception("編碼錯誤!");
// return -1; // 如果執行到這裡應該會報錯
}這裡資料讀取主要是把離散型的字串型別資料轉換為數值型資料,編碼規則如下:
屬性age的狀態: [young-->0,pre-presbyopic-->1,presbyopic-->2,]
屬性spectacle-prescrip的狀態: [myope-->0,hypermetrope-->1,]
屬性astigmatism的狀態: [no-->0,yes-->1,]
屬性tear-prod-rate的狀態: [reduced-->0,normal-->1,]
屬性contact-lenses的狀態: [soft-->0,hard-->1,none-->2,]// 讀取檔案並賦值
List<int[]> intData = readFileAndInitial(HSUtils.FILEPATH,HSUtils.SPLITTER);;
int splitAttributeIndex = attributes.length-1;// 下標需減1
int stateIndex = HSUtils.LABELSTATE;
int numInstances = intData.size();// 資料總個數
int[] labelStateCount = attrStateCount(intData,attributes.length-1);
HSUtils.setMinSupportCount(numInstances);
double targetValue=1.0*labelStateCount[HSUtils.LABELSTATE]/numInstances;
// 建立根節點
HSNode root = new HSNode(splitAttributeIndex,stateIndex,labelStateCount[stateIndex],numInstances);
double[] splitVals=new double[attributes.length];
byte[] tests = new byte[attributes.length];
root.setChidren(constructChildrenNodes(intData,targetValue,splitVals,tests));constructChildrenNodes函式為建立所有子節點,接收的引數有:intData:所有的資料(經過編碼的);targetValue:當前節點支援度;splitVals和tests陣列主要用於針對節點產生規則;
4.3 建立孩子節點:
1) 計算潛在孩子節點:
private List<HSNode> constructChildrenNodes(List<int[]> intData,double targetValue,
double[] splitVals,
byte[] tests) {
// 設定孩子節點
// // 獲取子資料集
//
// 針對每個屬性的每個state值計算其支援度(需要符合置信度)
PriorityQueue<AttrStateSup> pq = new PriorityQueue<AttrStateSup>();
for(int i=0;i<attributes.length-1;i++){// 最後一個屬性不用計算(為Label)
evaluateAttr(pq,intData,i,targetValue);
}/**
* 是否把第attrIndex屬性的state作為備選節點加入pq
* @param pq
* @param intData
* @param attrIndex
* @param targetValue
* @param stateIndex
* @param labelStateCount
*/
private void evaluateAttr(PriorityQueue<AttrStateSup> pq,
List<int[]> intData, int attrIndex, double targetValue) {
int[] counts = attrStateCount(intData,attrIndex);
boolean ok = false;
// only consider attribute values that result in subsets that meet/exceed min support
for (int i = 0; i < counts.length; i++) {
if (counts[i] >= HSUtils.getMinSupportCount()) {
ok = true;
break;
}
}
if(ok){
double subsetMatrix =0.0;
for(int stateIndex=0;stateIndex<counts.length;
stateIndex++){
subsetMatrix =attrStateCount(intData,attrIndex,stateIndex,attributes.length-1,HSUtils.LABELSTATE);
if(counts[stateIndex]>=HSUtils.getMinSupportCount()&&subsetMatrix>=HSUtils.getMinSupportCount()){
double merit = 1.0*subsetMatrix / counts[stateIndex]; //
double delta = merit - targetValue;
if(delta/targetValue>=HSUtils.MINCONFIDENCE){
pq.add(new AttrStateSup(attrIndex,stateIndex,counts[stateIndex],(int)subsetMatrix));
}
}
}
}// ok
}這裡首先針對當前資料集計算屬性下標為attrIndex的各個狀態的計數到counts[]陣列中;如果各個狀態的所有計數都小於最小支援度,則該屬性都不作為備選加入pq中;否則繼續判斷:計算目標屬性的設定狀態(比如soft)和當前屬性的狀態(young)共同出現的次數(第一次應該是2),賦值給subsetMatrix(那麼該值就是2);判斷subsetMatrix是否>=最小支援度,如果是在按照上面的程式碼進行計算,最後還有個判斷是用到置信度的(暫譯為置信度),如果滿足則把其加入到pq中,即備選子節點列表;
2)生成全域性規則,並新增孩子節點
List<HSNode> children = new ArrayList<HSNode>();
List<HotSpotHashKey> keyList = new ArrayList<HotSpotHashKey>();
while(pq.size()>0&&children.size()<HSUtils.MAXBRANCH){
AttrStateSup attrStateSup = pq.poll();
// 再次進行過濾
double[] newSplitVals = splitVals.clone();
byte[] newTests = tests.clone();
newSplitVals[attrStateSup.getAttrIndex()]=attrStateSup.getStateIndex()+1;
newTests[attrStateSup.getAttrIndex()] =(byte)2;
HotSpotHashKey key = new HotSpotHashKey(newSplitVals, newTests);
if (!HSUtils.m_ruleLookup.containsKey(key)) {
// insert it into the hash table
HSUtils.m_ruleLookup.put(key, ""); // 需要先增加規則,然後才處理子節點
HSNode child_i= new HSNode(attrStateSup.getAttrIndex(),attrStateSup.getStateIndex(),
attrStateSup.getStateCount(),attrStateSup.getAllCount());
keyList.add(key);
children.add(child_i);
} else {
System.out.println("The potential ,but not included :"+attrStateSup);
}
}新增一個節點後,就會新增相應的規則,這樣可以避免孩子節點的孩子有相同的規則被重複新增;
3) 針對每個孩子節點,處理其節點的孩子
// 處理子節點
for(int i=0;i<children.size();i++){
HSNode child = children.get(i);
child.setChidren(constructChildrenNodes(getSubData(intData,child.getSplitAttrIndex(),
child.getAttrStateIndex()),child.getSupport(),keyList.get(i).getM_splitValues(),
keyList.get(i).getM_testTypes()));
}這裡的getSubData即是找到當前資料集中和給定的屬性下標即屬性狀態一樣的資料返回,如下:
/**
* 獲取和splitAttributeIndex相同下標的屬性以及stateIndex的所有資料
* @param intData
* @param splitAttributeIndex
* @param stateIndex
* @return
*/
private List<int[]> getSubData(List<int[]> intData,
int splitAttributeIndex, int stateIndex) {
List<int[]> subData = new ArrayList<int[]>();
for(int[] d:intData){
if(d[splitAttributeIndex]==stateIndex){
subData.add(d);
}
}
return subData;
}4.4 列印規則樹
/**
* 列印規則樹
* @param node
* @param level
*/
public void printHSNode(HSNode node,int level){
printLevelTab(level);
System.out.print(node+"\n");
List<HSNode> children= node.getChidren();
for(HSNode child:children){
printHSNode(child,level+1);
}
}
private void printLevelTab(int level) {
for(int i=0;i<level;i++){
System.out.print("|\t");
}
}/**
* 格式化輸出
*/
public String toString(){
return HSUtils.getAttr(this.splitAttrIndex)+"="+HSUtils.getAttrState(splitAttrIndex, attrStateIndex)
+" ("+HSUtils.formatPercent(this.support)+" ["+this.stateCount+"/"+this.allCount+"])";
}4.5 演算法呼叫:
package fz.hotspot;
import fz.hotspot.dataobject.HSNode;
public class HotSpotTest {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
String file = "D:/jars/weka-src/data/contact-lenses.txt";
int labelStateIndex = 0; // 目標屬性所在下標
int maxBranches=2; // 最大分支數目
double minSupport =0.13; // 最小支援度
double minConfidence=0.01;// 最小置信度(在weka中使用的是minImprovement)
HotSpot hs = new HotSpot();
HSNode root = hs.run(file,labelStateIndex,maxBranches,minSupport,minConfidence);
System.out.println("\n規則樹如下:\n");
hs.printHSNode(root,0);
}
}
contact-lenses=soft (20.83% [5/24])
| astigmatism=no (41.67% [5/12])
| | tear-prod-rate=normal (83.33% [5/6])
| | | spectacle-prescrip=hypermetrope (100.00% [3/3])
| | spectacle-prescrip=hypermetrope (50.00% [3/6])
| tear-prod-rate=normal (41.67% [5/12])
| | spectacle-prescrip=hypermetrope (50.00% [3/6])最近在看《暗時間》,上面提到說有想法最好寫下來,這樣不僅可以加深自己的理解,同時在寫的過程中,比如一些表達之類的 也可以加強(身為程式設計師,這方面的能力確實欠缺),同時也可以讓別人檢驗到自己的思維盲點。
文中相關演算法理解,僅代表自己觀點。
分享,成長,快樂
腳踏實地,專注