
sparkmllib關聯規則演算法(FPGrowth,Apriori)
阿新 • • 發佈:2018-12-30
關聯規則演算法的思想就是找頻繁項集,通過頻繁項集找強關聯。
介紹下基本概念:
對於A->B
1、置信度:P(B|A),在A發生的事件中同時發生B的概率 p(AB)/P(A) 例如購物籃分析:牛奶 ⇒ 麵包
2、支援度:P(A ∩ B),既有A又有B的概率
假如支援度:3%,置信度:40%
支援度3%:意味著3%顧客同時購買牛奶和麵包
置信度40%:意味著購買牛奶的顧客40%也購買麵包
3、如果事件A中包含k個元素,那麼稱這個事件A為k項集事件A滿足最小支援度閾值的事件稱為頻繁k項集。
4、同時滿足最小支援度閾值和最小置信度閾值的規則稱為強規則
apriori演算法的思想
(得出的的強規則要滿足給定的最小支援度和最小置信度)
apriori演算法的思想是通過k-1項集來推k項集。首先,找出頻繁“1項集”的集合,該集合記作L1。L1用於找頻繁“2項集”的集合L2,而L2用於找L3。如此下去,直到不能找到“K項集”。找每個Lk都需要一次資料庫掃描(這也是它最大的缺點)。
核心思想是:連線步和剪枝步。連線步是自連線,原則是保證前k-2項相同,並按照字典順序連線。剪枝步,是使任一頻繁項集的所有非空子集也必須是頻繁的。反之,如果某個候選的非空子集不是頻繁的,那麼該候選肯定不是頻繁的,從而可以將其從CK(頻繁項集)中刪除。
下面一個比較經典的例子來說明apriori演算法的執行步驟:
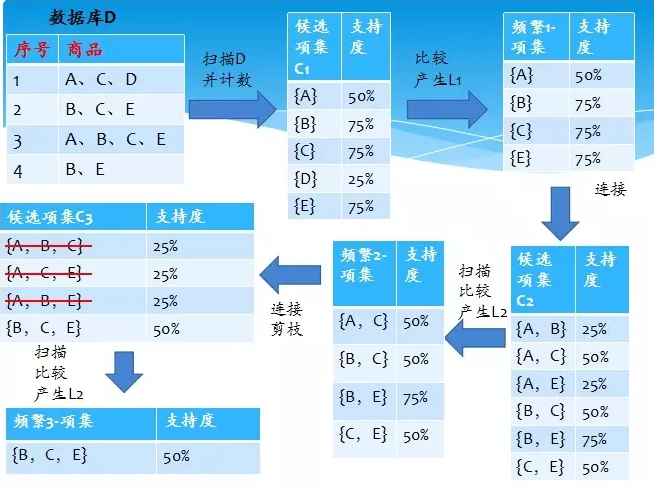
上面只計算了頻繁項集的支援度,沒有計算它的置信度。
基本概念
1. 項與項集 這是一個集合的概念,在一籃子商品中的一件消費品即一項(item),則若干項的集合為項集,如{啤酒,尿布}構成一個二元項集。 2、關聯規則 關聯規則用亍表示資料內隱含的關聯性,例如表示購買了尿布的消費者往往也會購買啤酒。關聯性強度如何,由3 個概念,即支援度、置信度、提升度來控制和評價。 3、支援度(support) 支援度是指在所有項集中{X, Y}出現的可能性,即項集中同時含有X 和Y 的概率: 設定最小閾值為5%,由亍{尿布,啤酒}的支援度為800/10000=8%,滿足最小閾值要求,成為頻繁項集,保留規則;而{尿布,麵包}的支援度為100/10000=1%,則被剔除。 4、置信度(confidence) 置信度表示在先決條件X 發生的條件下,關聯結果Y 發生的概率:這是生成強關聯規則的第二個門檻,衡量了所考察的關聯規則在“質”上的可靠性。相似地,我們需要對置信度設定最小閾值(mincon)來實現進一步篩選。 當設定置信度的最小閾值為70%時,例如{尿布,啤酒}中,購買尿布時會購買啤酒的置信度為800/1000=80%,保留規則;而購買啤酒時會購買尿布的置信度為800/2000=40%,則被剔除。 5. 提升度(lift) 提升度表示在含有X 的條件下同時含有Y 的可能性與沒有X 這個條件下項集中含有Y 的可能性之比:公式為置信度(artichok=>cracker)/支援度(cracker)。該指標與置信度同樣衡量規則的可靠性,可以看作是置信度的一種互補指標。
FPGrowth 演算法
1)掃描事務資料庫D 一次。收集頻繁項的集合F 和它們的支援度。對F 按支援度降序排序,結果為頻繁項
表L。
2)建立FP 樹的根節點,以“null”標記它。對亍D 中的每個事務Trans,執行:選擇 Trans
中的頻繁項,並按L 中的次序排序。設排序後的頻繁項表為[p | P],其中,p 是第一個元素,而P 是剩餘元素的表。呼叫insert_tree([p | P], T)。該過程執行情況如下。如果T 有子節點N 使得N.item-name = p.item-name,則N 的計數增加1;否則建立一個新節點N 將其計數設定為1,連結到它的父節點T,並且通過節點的鏈結構將其連結到具有相同item-name 的節點中。如果P非空,則遞迴地呼叫insert_tree(P, N)。分析例項
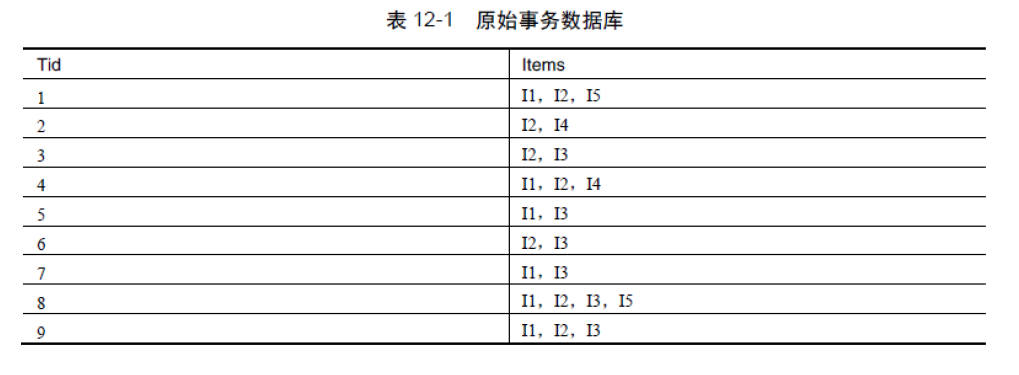
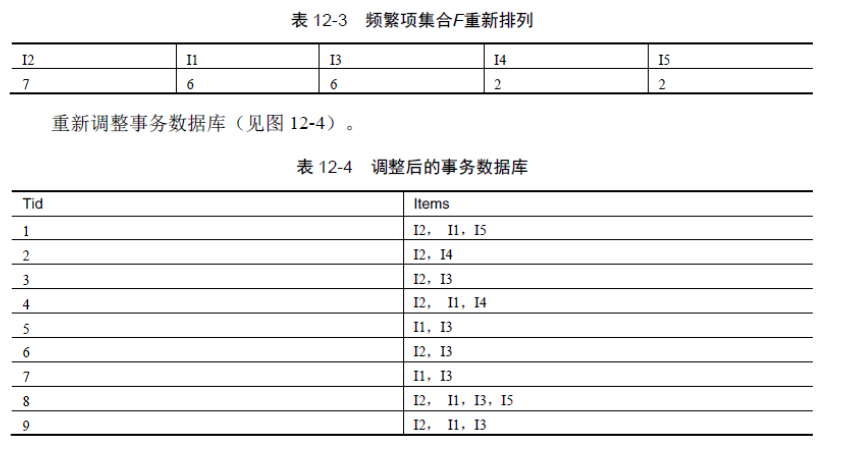
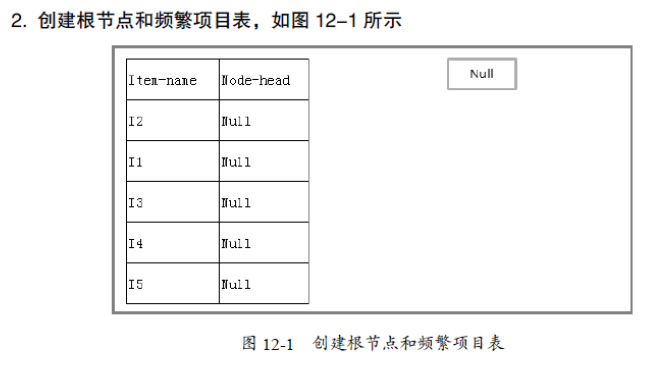
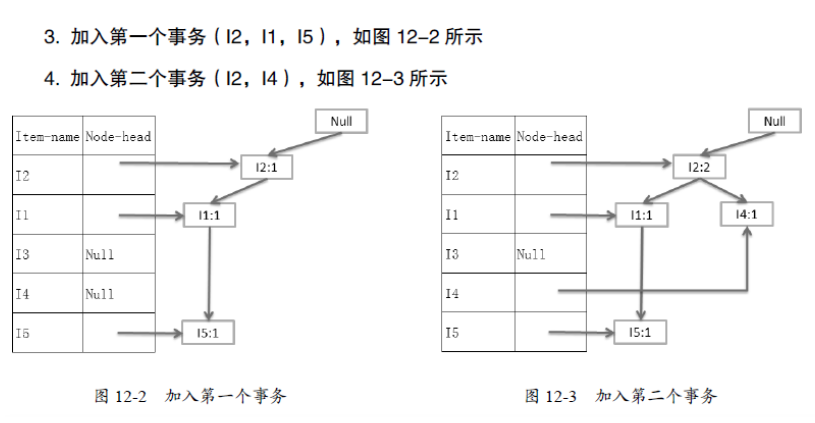
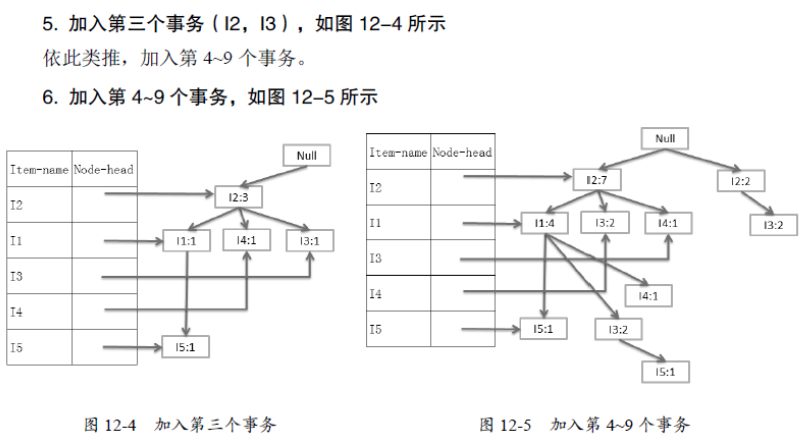
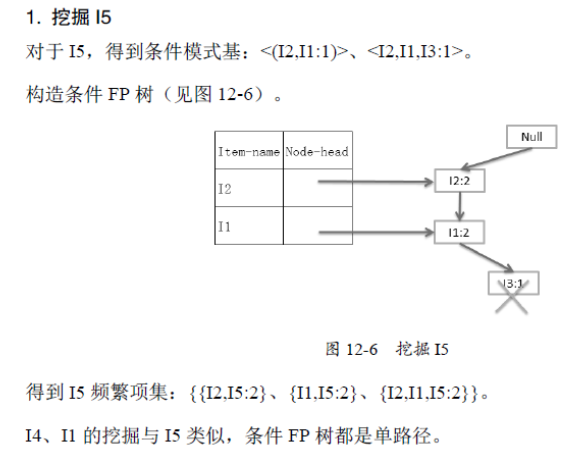
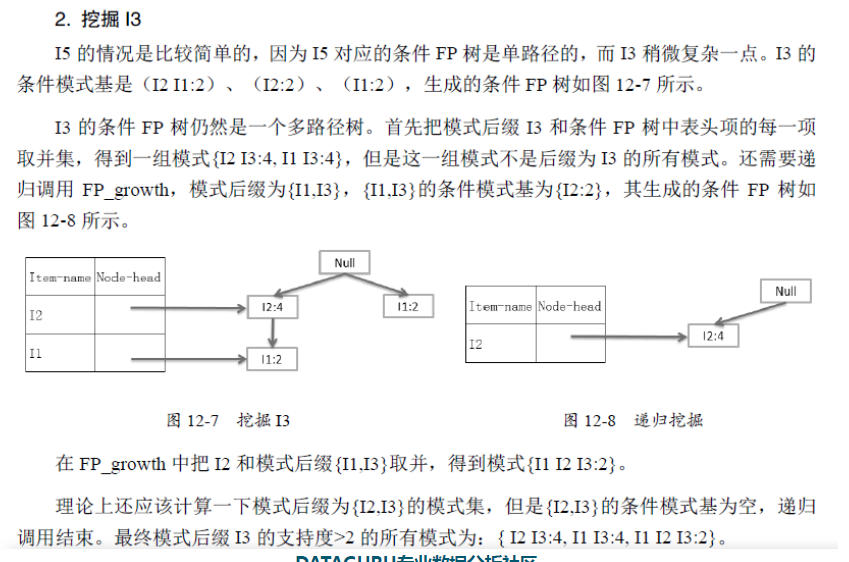
原始碼分析

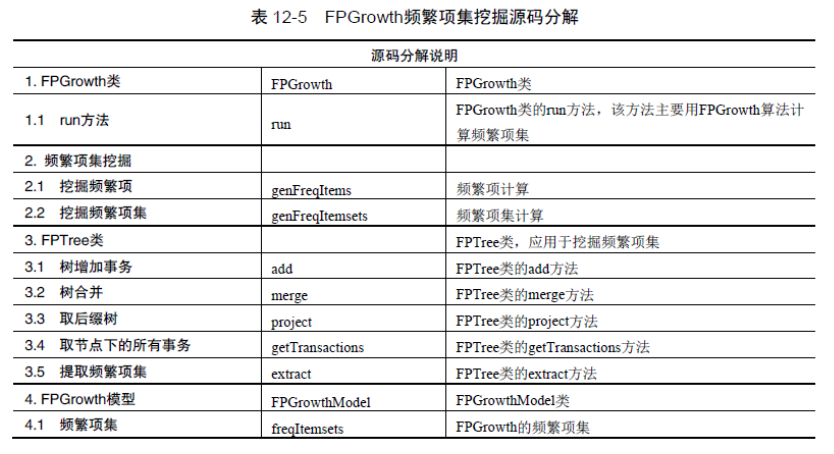
def run[Item: ClassTag](data: RDD[Array[Item]]): FPGrowthModel[Item] = {
if (data.getStorageLevel == StorageLevel.NONE) {
logWarning("Input data is not cached.")
}
val count = data.count()
val minCount = math.ceil(minSupport * count).toLong
val numParts = if (numPartitions > 0) numPartitions else data.partitions.length
val partitioner = new HashPartitioner(numParts)
val freqItems = genFreqItems(data, minCount, partitioner)
val freqItemsets = genFreqItemsets(data, minCount, freqItems, partitioner)
new FPGrowthModel(freqItemsets)
} private def genFreqItems[Item: ClassTag](
data: RDD[Array[Item]],
minCount: Long,
partitioner: Partitioner): Array[Item] = {
data.flatMap { t =>
val uniq = t.toSet
if (t.length != uniq.size) {
throw new SparkException(s"Items in a transaction must be unique but got ${t.toSeq}.")
}
t
}.map(v => (v, 1L))
.reduceByKey(partitioner, _ + _)
.filter(_._2 >= minCount)
.collect()
.sortBy(-_._2)
.map(_._1)
}private def genFreqItemsets[Item: ClassTag](
data: RDD[Array[Item]],
minCount: Long,
freqItems: Array[Item],
partitioner: Partitioner): RDD[FreqItemset[Item]] = {
val itemToRank = freqItems.zipWithIndex.toMap
data.flatMap { transaction =>
genCondTransactions(transaction, itemToRank, partitioner)
}.aggregateByKey(new FPTree[Int], partitioner.numPartitions)(
(tree, transaction) => tree.add(transaction, 1L),
(tree1, tree2) => tree1.merge(tree2))
.flatMap { case (part, tree) =>
tree.extract(minCount, x => partitioner.getPartition(x) == part)
}.map { case (ranks, count) =>
new FreqItemset(ranks.map(i => freqItems(i)).toArray, count)
}
}def generateAssociationRules(confidence: Double): RDD[AssociationRules.Rule[Item]] = {
val associationRules = new AssociationRules(confidence)
associationRules.run(freqItemsets)
} def run[Item: ClassTag](freqItemsets: RDD[FreqItemset[Item]]): RDD[Rule[Item]] = {
// For candidate rule X => Y, generate (X, (Y, freq(X union Y)))
val candidates = freqItemsets.flatMap { itemset =>
val items = itemset.items
items.flatMap { item =>
items.partition(_ == item) match {
case (consequent, antecedent) if !antecedent.isEmpty =>
Some((antecedent.toSeq, (consequent.toSeq, itemset.freq)))
case _ => None
}
}
}
// Join to get (X, ((Y, freq(X union Y)), freq(X))), generate rules, and filter by confidence
candidates.join(freqItemsets.map(x => (x.items.toSeq, x.freq)))
.map { case (antecendent, ((consequent, freqUnion), freqAntecedent)) =>
new Rule(antecendent.toArray, consequent.toArray, freqUnion, freqAntecedent)
}.filter(_.confidence >= minConfidence)
}例項
FP-growth:
import org.apache.spark.mllib.fpm.FPGrowth
import org.apache.spark.rdd.RDD
val data = sc.textFile("data/mllib/sample_fpgrowth.txt")
val transactions: RDD[Array[String]] = data.map(s => s.trim.split(' '))
val fpg = new FPGrowth()
.setMinSupport(0.2)
.setNumPartitions(10)
val model = fpg.run(transactions)
model.freqItemsets.collect().foreach { itemset =>
println(itemset.items.mkString("[", ",", "]") + ", " + itemset.freq)
}
val minConfidence = 0.8
model.generateAssociationRules(minConfidence).collect().foreach { rule =>
println(
rule.antecedent.mkString("[", ",", "]")
+ " => " + rule.consequent .mkString("[", ",", "]")
+ ", " + rule.confidence)
}Association Rules:
import org.apache.spark.mllib.fpm.AssociationRules
import org.apache.spark.mllib.fpm.FPGrowth.FreqItemset
val freqItemsets = sc.parallelize(Seq(
new FreqItemset(Array("a"), 15L),
new FreqItemset(Array("b"), 35L),
new FreqItemset(Array("a", "b"), 12L)
))
val ar = new AssociationRules()
.setMinConfidence(0.8)
val results = ar.run(freqItemsets)
results.collect().foreach { rule =>
println("[" + rule.antecedent.mkString(",")
+ "=>"
+ rule.consequent.mkString(",") + "]," + rule.confidence)
}