
關於Buddy(夥伴)演算法的討論
對夥伴系統種的點陣圖的作用沒有搞的清楚
就是說:系統在確定一個塊的夥伴塊是否是空閒時,是在空閒連結串列種查詢有無
夥伴塊呢還是利用點陣圖種的狀態來判斷,
總覺得是和點陣圖有關,可是點陣圖中的一位表示一對夥伴塊的狀態
又覺得好象資訊不太夠用。
當點陣圖中的一位為0,表示兩塊都空或都閒
當點陣圖中的一位為1,表示有一塊為忙
哪位大俠能詳細談談點陣圖的動作哪?
到底是怎麼異或的?
點陣圖的某位對應於兩個夥伴塊,為1就表示其中一塊忙,為0表示兩塊都閒。
所謂異或,是指剛開始兩塊都閒為0,後來其中一塊用了異或一下得1,後來另一塊也用
了異或一下得0,後來前面一塊回收了異或一下得1,後來另一塊也回收了異或一下得0,
這樣(如果為1就不合並)就又可以和前面一塊合併成一大塊了。
點陣圖的主要用途是在回收演算法中指示是否可以和夥伴塊合併,分配時只要搜尋空閒連結串列
就足夠了。當然,分配的同時還要對相應位異或一下了,這是為回收演算法服務。
講的太好了,一下清楚了許多,謝謝了。
我對分配時相應的位異或這個地方還有點暈,就是說對點陣圖的位異或時
是隻對該大小佇列的點陣圖進行呢?還是所有10條中可能用到該塊的都進行處理呢?
比如說:4頁這個位置,如果是1頁大小的塊,其夥伴塊是第5頁,如果是2頁大小的塊時
其夥伴塊是6,7頁組成的,如果是4頁大小的塊時,其夥伴塊是以0頁大頭的塊
那麼當第4頁(一頁大小)回收時(或釋放時),其一頁大小佇列的點陣圖肯定是處理了
那麼其它大小的點陣圖是否變化呢?比方說第二條佇列點陣圖的第2位是不是也要異或呀?
總感覺不太連冠似的
就拿你的例子來說明吧。
對於回收演算法:
1. 當回收序號為4的1頁塊時,先找到order為0的area,把該頁面塊加入到該area的空閒
連結串列中,然後判斷其夥伴塊(序號為5的1頁塊)的狀態,讀該area(不是其它area! )
的map的第2位( 4>>(1+order) ),假設夥伴塊被佔,則該位為0(回收4塊前,4、5塊
都忙),現異或一下得1,並不再向上合併。
2. 當回收序號為5的1頁塊時,同理,先找到order為0的area,把該頁面塊加入到該are
a的空閒連結串列中,然後判斷其夥伴塊(序號為4的1頁塊)的狀態,讀該area的map的第2位
( 5>>(1+order) ), 這時該位為1(4塊已回收),現異或一下得0,並向上合併,把序
號為4的1頁塊和序號為5的1頁塊從該area的空閒連結串列中摘除,合併成序號為4的2頁塊,
並放到order為1的area的空閒連結串列中。同理,此時又要判斷合併後的塊的夥伴塊(序號
為6的2頁塊)的狀態,讀該area( order為1的area,不是其它! ) 的map的第1位(
4>>(1+order) ),假設夥伴塊在此之前已被回收,則該位為1,現異或一下得0,並向上
合併,把序號為4的2頁塊和序號為6的2頁塊從order為1的area的空閒連結串列中摘除,合併
成序號為4的4頁塊,並放到order為2的area的空閒連結串列中。然後再判斷其夥伴塊狀態,
如此反覆。
本來還想再說一下分配演算法的,發現已經這麼多了,我想也應該能明白了。
多謝了,現在清楚了許多
看來:
1。通過異或後是否為0判斷是否繼續向上合併
2。初始狀態點陣圖為全0
3。每次無論分配還是回收,都只對相應大小的點陣圖處理(在沒有分裂或合併的情況)
而並不是同時處理全部10條佇列的。
現在再來舉例談一談分配演算法。
假設在初始階段,全是大小為2^9大小的塊( MAX_ORDER為10),序號依次為0, 512, 1
024等等,並且所有area的map位都為0(實際上作業系統程式碼要佔一部分空間,但這裡只
是舉例),現在要分配一個2^3大小的頁面塊,有以下動作:
1. 從order為3的area的空閒連結串列開始搜尋,沒找到就向高一級area搜尋,依次類推,按
照假設條件,會一直搜尋到order為9的area,找到了序號為0的2^9頁塊。
2. 把序號為0的2^9頁塊從order為9的area的空閒連結串列中摘除並對該area的第0位( 0>>
(1+9) )異或一下得1。
3. 把序號為0的2^9頁塊拆分成兩個序號分別為0和256的2^8頁塊,前者放入order為8的
area的空閒連結串列中,並對該area的第0位( 0>>(1+8) )異或一下得1。
4. 把序號為256的2^8頁塊拆分成兩個序號分別為256和384的2^7頁塊,前者放入order為
7的area的空閒連結串列中,並對該area的第1位( 256>>(1+7) )異或一下得1。
5. 把序號為384的2^7頁塊拆分成兩個序號分別為384和448的2^6頁塊,前者放入order為
6的area的空閒連結串列中,並對該area的第3位( 384>>(1+6) )異或一下得1。
6. 把序號為448的2^6頁塊拆分成兩個序號分別為448和480的2^5頁塊,前者放入order為
5的area的空閒連結串列中,並對該area的第7位( 448>>(1+5) )異或一下得1。
7. 把序號為480的2^5頁塊拆分成兩個序號分別為480和496的2^4頁塊,前者放入order為
4的area的空閒連結串列中,並對該area的第15位( 480>>(1+4) )異或一下得1。
8. 把序號為496的2^4頁塊拆分成兩個序號分別為496和504的2^3頁塊,前者放入order為
3的area的空閒連結串列中,並對該area的第31位( 496>>(1+3) )異或一下得1。
9. 序號為504的2^3頁塊就是所求的塊。
如果有興趣可以分配和回收一起演算舉例,我就不再贅述。
|
|
2.4版核心的頁分配器引入了"頁區"(zone)結構, 一個頁區就是一大塊連續的物理頁面. Linux 2.4將整個
實體記憶體劃分為3個頁區, DMA頁區(ZONE_DMA), 普通頁區(ZONE_NORMAL)和高階頁區(ZONE_HIGHMEM).
頁區可以使頁面分配更有目的性, 有利於減少記憶體碎片. 每個頁區的頁分配仍使用夥伴(buddy)演算法.
夥伴演算法將整個頁區劃分為以2為冪次的各級頁塊的集合, 相鄰的同次頁塊稱為夥伴, 一對夥伴可以合併
到更高次頁面集合中去.
下面分析一下夥伴演算法的頁面釋放過程.
; mm/page_alloc.c:
#define BAD_RANGE(zone,x) (((zone) != (x)->zone) || (((x)-mem_map) < (zone)->offset) || (((x)-mem_map) >= (zone)->offset+(zone)->size))
#define virt_to_page(kaddr) (mem_map + (__pa(kaddr) >> PAGE_SHIFT))
#define put_page_testzero(p) atomic_dec_and_test(&(p)->count)
void free_pages(unsigned long addr, unsigned long order)
{ order是頁塊尺寸指數, 即頁塊的尺寸有(2^order)頁.
if (addr != 0)
__free_pages(virt_to_page(addr), order);
}
void __free_pages(struct page *page, unsigned long order)
{
if (!PageReserved(page) && put_page_testzero(page))
__free_pages_ok(page, order);
}
static void FASTCALL(__free_pages_ok (struct page *page, unsigned long order));
static void __free_pages_ok (struct page *page, unsigned long order)
{
unsigned long index, page_idx, mask, flags;
free_area_t *area;
struct page *base;
zone_t *zone;
if (page->buffers)
BUG();
if (page->mapping)
BUG();
if (!VALID_PAGE(page))
BUG();
if (PageSwapCache(page))
BUG();
if (PageLocked(page))
BUG();
if (PageDecrAfter(page))
BUG();
if (PageActive(page))
BUG();
if (PageInactiveDirty(page))
BUG();
if (PageInactiveClean(page))
BUG();
page->flags &= ~((1<<
page->age = PAGE_AGE_START;
zone = page->zone; 取page所在的頁區
mask = (~0UL) << order; 求頁面指數的掩碼
base = mem_map + zone->offset; 求頁區的起始頁
page_idx = page - base; 求page在頁區內的起始頁號
if (page_idx & ~mask) 頁號必須在頁塊尺寸邊界上對齊
BUG();
index = page_idx >> (1 + order);
; 求頁塊在塊點陣圖中的索引, 每一索引位置代表相鄰兩個"夥伴"
area = zone->free_area + order; 取該指數頁塊的點陣圖平面
spin_lock_irqsave(&zone->lock, flags);
zone->free_pages -= mask; 頁區的自由頁數加上將釋放的頁數(掩碼值為負)
while (mask + (1 << (MAX_ORDER-1))) { 當mask所遮掩的位長為(MAX_ORDER-1)時,和恰好為零,即達到了最大塊指數
struct page *buddy1, *buddy2;
if (area >= zone->free_area + MAX_ORDER) 如果超過了最高次平面
BUG();
if (!test_and_change_bit(index, area->map)) 測試並取反頁塊的索引位
/*
* the buddy page is still allocated.
*/
break; 如果原始位為0, 則說明該頁塊原來沒有夥伴, 操作完成
/*
* Move the buddy up one level. 如果原始位為1, 則說明該頁塊存在一個夥伴
*/
buddy1 = base + (page_idx ^ -mask); 對頁塊號邊界位取反,得到夥伴的起點
buddy2 = base + page_idx;
if (BAD_RANGE(zone,buddy1)) 夥伴有沒有越過頁區範圍
BUG();
if (BAD_RANGE(zone,buddy2))
BUG();
memlist_del(&buddy1->list); 刪除夥伴的自由鏈
mask <<= 1; 求更高次掩碼
area++; 求更高次點陣圖平面
index >>= 1; 求更高次索引號
page_idx &= mask; 求更高次頁塊的起始頁號
}
memlist_add_head(&(base + page_idx)->list, &area->free_list); 將求得的高次頁塊加入該指數的自由鏈
spin_unlock_irqrestore(&zone->lock, flags);
/*
* We don't want to protect this variable from race conditions
* since it's nothing important, but we do want to make sure
* it never gets negative.
*/
if (memory_pressure > NR_CPUS)
memory_pressure--;
}
|
|
|
2.4版核心的頁分配器引入了"頁區"(zone)結構, 一個頁區就是一大塊連續的物理頁面. Linux 2.4將整個
實體記憶體劃分為3個頁區, DMA頁區(ZONE_DMA), 普通頁區(ZONE_NORMAL)和高階頁區(ZONE_HIGHMEM).
頁區可以使頁面分配更有目的性, 有利於減少記憶體碎片. 每個頁區的頁分配仍使用夥伴(buddy)演算法.
夥伴演算法將整個頁區劃分為以2為冪次的各級頁塊的集合, 相鄰的同次頁塊稱為夥伴, 一對夥伴可以合併
到更高次頁面集合中去.
下面分析一下夥伴演算法的頁面釋放過程.
; mm/page_alloc.c:
#define BAD_RANGE(zone,x) (((zone) != (x)->zone) || (((x)-mem_map) < (zone)->offset) || (((x)-mem_map) >= (zone)->offset+(zone)->size))
#define virt_to_page(kaddr) (mem_map + (__pa(kaddr) >> PAGE_SHIFT))
#define put_page_testzero(p) atomic_dec_and_test(&(p)->count)
void free_pages(unsigned long addr, unsigned long order)
{ order是頁塊尺寸指數, 即頁塊的尺寸有(2^order)頁.
if (addr != 0)
__free_pages(virt_to_page(addr), order);
}
void __free_pages(struct page *page, unsigned long order)
{
if (!PageReserved(page) && put_page_testzero(page))
__free_pages_ok(page, order);
}
static void FASTCALL(__free_pages_ok (struct page *page, unsigned long order));
static void __free_pages_ok (struct page *page, unsigned long order)
{
unsigned long index, page_idx, mask, flags;
free_area_t *area;
struct page *base;
zone_t *zone;
if (page->buffers)
BUG();
if (page->mapping)
BUG();
if (!VALID_PAGE(page))
BUG();
if (PageSwapCache(page))
BUG();
if (PageLocked(page))
BUG();
if (PageDecrAfter(page))
BUG();
if (PageActive(page))
BUG();
if (PageInactiveDirty(page))
BUG();
if (PageInactiveClean(page))
BUG();
page->flags &= ~((1<<
page->age = PAGE_AGE_START;
zone = page->zone; 取page所在的頁區
mask = (~0UL) << order; 求頁面指數的掩碼
base = mem_map + zone->offset; 求頁區的起始頁
page_idx = page - base; 求page在頁區內的起始頁號
if (page_idx & ~mask) 頁號必須在頁塊尺寸邊界上對齊
BUG();
index = page_idx >> (1 + order);
; 求頁塊在塊點陣圖中的索引, 每一索引位置代表相鄰兩個"夥伴"
area = zone->free_area + order; 取該指數頁塊的點陣圖平面
spin_lock_irqsave(&zone->lock, flags);
zone->free_pages -= mask; 頁區的自由頁數加上將釋放的頁數(掩碼值為負)
while (mask + (1 << (MAX_ORDER-1))) { 當mask所遮掩的位長為(MAX_ORDER-1)時,和恰好為零,即達到了最大塊指數
struct page *buddy1, *buddy2;
if (area >= zone->free_area + MAX_ORDER) 如果超過了最高次平面
BUG();
if (!test_and_change_bit(index, area->map)) 測試並取反頁塊的索引位
/*
* the buddy page is still allocated.
*/
break; 如果原始位為0, 則說明該頁塊原來沒有夥伴, 操作完成
/*
* Move the buddy up one level. 如果原始位為1, 則說明該頁塊存在一個夥伴
*/
buddy1 = base + (page_idx ^ -mask); 對頁塊號邊界位取反,得到夥伴的起點
buddy2 = base + page_idx;
if (BAD_RANGE(zone,buddy1)) 夥伴有沒有越過頁區範圍
BUG();
if (BAD_RANGE(zone,buddy2))
BUG();
memlist_del(&buddy1->list); 刪除夥伴的自由鏈
mask <<= 1; 求更高次掩碼
area++; 求更高次點陣圖平面
index >>= 1; 求更高次索引號
page_idx &= mask; 求更高次頁塊的起始頁號
}
memlist_add_head(&(base + page_idx)->list, &area->free_list); 將求得的高次頁塊加入該指數的自由鏈
spin_unlock_irqrestore(&zone->lock, flags);
/*
* We don't want to protect this variable from race conditions
* since it's nothing important, but we do want to make sure
* it never gets negative.
*/
if (memory_pressure > NR_CPUS)
memory_pressure--;
}
|
在Webus空間管理元件(WSM)中, 我也提供了Buddy System的實現, 關於這種演算法的詳細描述, 建議大家看經典教材 " 資料結構" 一書第8章第4節.
 呵呵, 藍色經典!
呵呵, 藍色經典!我在此僅談談如下三個問題:
1. Buddy System的基本原理?
2. 如何分配空間?
3. 如何回收空間?
對以上三個問題的說明:
Buddy System把系統中的可用儲存空間劃分為儲存塊(Block)來進行管理, 每個儲存塊的大小必須是2的n次冪(Pow(2, n)), 即1, 2, 4, 8, 16, 32, 64, 128...
假設系統全部可用空間為Pow(2, k), 那麼在Buddy System初始化時將生成一個長度為k + 1的可用空間表List, 並將全部可用空間作為一個大小為Pow(2, k)的塊掛接在List的最後一個節點上, 如下圖:

當用戶申請size個字的儲存空間時, Buddy System分配的Block大小為Pow(2, m)個字大小(Pow(2, m-1) < size < Pow(2, m)).
此時Buddy System將在List中的m位置尋找可用的Block. 顯然List中這個位置為空, 於是Buddy System就開始尋找向上查詢m+1, m+2, 直到達到k為止. 找到k後, 便得到可用Block(k), 此時Block(k)將分裂成兩個大小為Pow(k-1)的塊, 並將其中一個插入到List中k-1的位置, 同時對另外一個繼續進行分裂. 如此以往直到得到兩個大小為Pow(2, m)的塊為止, 如下圖所示:
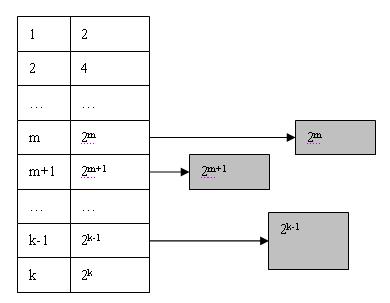
如果系統在執行一段時間之後, List中某個位置n可能會出現多個塊, 則將其他塊依次連結可用塊連結串列的末尾:

當Buddy System要在n位置取可用塊時, 直接從連結串列頭取一個就行了.
當一個儲存塊不再使用時, 使用者應該將該塊歸還給Buddy System. 此時系統將根據Block的大小計算出其在List中的位置, 然後插入到可用塊連結串列的末尾. 在這一步完成後, 系統立即開始合併操作. 該操作是將"夥伴"合併到一起, 並放到List的下一個位置中, 並繼續對更大的塊進行合併, 直到無法合併為止.
何謂"夥伴"? 如前所述, 在分配儲存塊時經常會將一個大的儲存塊分裂成兩個大小相等的小塊, 那麼這兩個小塊就稱為"夥伴".在Buddy System進行合併時, 只會將互為夥伴的兩個儲存塊合併成大塊, 也就是說如果有兩個儲存塊大小相同, 地址也相鄰, 但是不是由同一個大塊分裂出來的, 也不會被合併起來. 正常情況下, 起始地址為p, 大小為Pow(2, k)的儲存塊, 其夥伴塊的起始地址為: p + Pow(2, k) 和 p - Pow(2, k).
下面把資料結構一書中Buddy演算法分配儲存塊的C++偽碼帖出來以供大家參考:
 Space AllocBuddy(FreeList &avail, int n)
Space AllocBuddy(FreeList &avail, int n)

 {
{ //avail[0..m]為可利用空間表, n為申請分配量, 若有不小於n的空閒塊, //則分配相應的儲存塊, 並返回其首地址, 否則返回NULLfor(k=0; k<=m && (avail[k].nodesize < n+1||!avail[k].first); ++k);//查詢滿足分配要求的子表if(k>m) return NULL;//分配失敗, 返回NULL;
//avail[0..m]為可利用空間表, n為申請分配量, 若有不小於n的空閒塊, //則分配相應的儲存塊, 並返回其首地址, 否則返回NULLfor(k=0; k<=m && (avail[k].nodesize < n+1||!avail[k].first); ++k);//查詢滿足分配要求的子表if(k>m) return NULL;//分配失敗, 返回NULL;
 else{//可進行分配 pa = avail[k].first;//指向可分配子表的第一個節點 pre = pa->llink; suc = pa->rlink;//分配指向前驅和後繼if(pa == suc) avail[k].first = NULL;//分配後該子表變為空表else{//從子表刪除*pa節點 pre->rlink = suc; suc->llink = pre; avail[k].first = suc;
else{//可進行分配 pa = avail[k].first;//指向可分配子表的第一個節點 pre = pa->llink; suc = pa->rlink;//分配指向前驅和後繼if(pa == suc) avail[k].first = NULL;//分配後該子表變為空表else{//從子表刪除*pa節點 pre->rlink = suc; suc->llink = pre; avail[k].first = suc; } } for(i =1; avail[k-i].nodesize >= n+1; ++i) { pi = pa + pow(2, k-i); pi-> rlink = pi; pi ->llink = pi; pi -> tag =0; pi -> kval = k-i; avail[k-i].first = pi; }//將剩餘塊插入相應子表 pa -> tag =1; pa -> kval = k-(--i); return pa;
} } for(i =1; avail[k-i].nodesize >= n+1; ++i) { pi = pa + pow(2, k-i); pi-> rlink = pi; pi ->llink = pi; pi -> tag =0; pi -> kval = k-i; avail[k-i].first = pi; }//將剩餘塊插入相應子表 pa -> tag =1; pa -> kval = k-(--i); return pa; }
}
關於儲存塊回收演算法, 書上沒有現成的, 日後笑侃一定提供給大家, 呵呵, 今日工作繁忙, 精力不濟, 要掛起了. 感謝大家的關注!
3.4 頁面分配與回收
對系統中物理頁面的請求十分頻繁。例如當一個可執行映象被調入記憶體時,作業系統必須為其分配頁面。當映象執行完畢和解除安裝時這些頁面必須被釋放。物理頁面的另一個用途是儲存頁表這些核心資料結構。虛擬記憶體子系統中負責頁面分配與回收的資料結構和機制可能用處最大。
系統中所有的物理頁面用包含mem_map_t結構的連結串列mem_map來描敘,這些結構在系統啟動時初始化。每個 mem_map_t描敘了一個物理頁面。其中與記憶體管理相關的重要域如下:
count
- 記錄使用此頁面的使用者個數。當這個頁面在多個程序之間共享時,它的值大於1。
- age
- 此域描敘頁面的年齡,用於選擇將適當的頁面拋棄或者置換出記憶體時。
- map_nr
- 記錄本mem_map_t描敘的物理頁面框號。
頁面分配程式碼使用free_area陣列來尋找和釋放頁面,此機制負責整個緩衝管理。另外此程式碼與處理器使用的頁面大小和物理分頁機制無關。
free_area中的每個元素都包含頁面塊的資訊。陣列中第一個元素描敘1個頁面,第二個表示2個頁面大小的塊而接下來表示4個頁面大小的塊,總之都是2的次冪倍大小。list域表示一個佇列頭,它包含指向mem_map陣列中page資料結構的指標。所有的空閒頁面都在此佇列中。map域是指向某個特定頁面尺寸的頁面組分配情況點陣圖的指標。當頁面的第N塊空閒時,點陣圖的第N位被置位。
圖free-area-figure畫出了free_area結構。第一個元素有個自由頁面(頁面框號0),第二個元素有4個頁面大小的2個自由塊,前一個從頁面框號4開始而後一個從頁面框號56開始。
3.4.1 頁面分配
Linux使用Buddy演算法來有效的分配與回收頁面塊。頁面分配程式碼每次分配包含一個或者多個物理頁面的記憶體塊。頁面以2的次冪的記憶體塊來分配。這意味著它可以分配1個、2個和4個頁面的塊。只要系統中有足夠的空閒頁面來滿足這個要求(nr_free_pages > min_free_page),記憶體分配程式碼將在free_area中尋找一個與請求大小相同的空閒塊。free_area中的每個元素儲存著一個反映這樣大小的已分配與空閒頁面 的點陣圖。例如,free_area陣列中第二個元素指向一個反映大小為四個頁面的記憶體塊分配情況的記憶體映象。
分配演算法首先搜尋滿足請求大小的頁面。它從free_area資料結構的list域著手沿鏈來搜尋空閒頁面。如果沒有這樣請求大小的空閒頁面,則它搜尋兩倍於請求大小的記憶體塊。這個過程一直將持續到free_area 被搜尋完或找到滿足要求的記憶體塊為止。如果找到的頁面塊大於請求的塊則對其進行分割以使其大小與請求塊匹配。由於塊大小都是2的次冪所以分割過程十分簡單。空閒塊被連進相應的佇列而這個頁面塊被分配給呼叫者。

在圖3.4中,當系統中有大小為兩個頁面塊的請求發出時,第一個4頁面大小的記憶體塊(從頁面框號4開始)將分成兩個2頁面大小的塊。前一個,從頁面框號4開始的,將分配出去返回給請求者,而後一個,從頁面框號6開始,將被新增到free_area陣列中表示兩個頁面大小的空閒塊的元素1中。
3.4.2 頁面回收
將大的頁面塊打碎進行分配將增加系統中零碎空閒頁面塊的數目。頁面回收程式碼在適當時機下要將這些頁面結合起來形成單一大頁面塊。事實上頁面塊大小決定了頁面重新組合的難易程度。
當頁面塊被釋放時,程式碼將檢查是否有相同大小的相鄰或者buddy記憶體塊存在。如果有,則將它們結合起來形成一個大小為原來兩倍的新空閒塊。每次結合完之後,程式碼還要檢查是否可以繼續合併成更大的頁面。最佳情況是系統的空閒頁面塊將和允許分配的最大記憶體一樣大。
在圖3.4中,如果釋放頁面框號1,它將和空閒頁面框號0結合作為大小為2個頁面的空閒塊排入free_area的第一個元素中。
3.5 記憶體對映
映象執行時,可執行映象的內容將被調入程序虛擬地址空間中。可執行映象使用的共享庫同樣如此。然而可執行檔案實際上並沒有調入實體記憶體,而是僅僅連線到程序的虛擬記憶體。當程式的其他部分執行時引用到這部分時才把它們從磁碟上調入記憶體。將映象連線到程序虛擬地址空間的過程稱為記憶體對映。

圖3.5 虛擬記憶體區域
每個程序的虛擬記憶體用一個mm_struct來表示。它包含當前執行的映象(如BASH)以及指向vm_area_struct 的大量指標。每個vm_area_struct資料結構描敘了虛擬記憶體的起始與結束位置,程序對此記憶體區域的存取許可權以及一組記憶體操作函式。這些函式都是Linux在操縱虛擬記憶體區域時必須用到的子程式。其中一個負責處理程序試圖訪問不在當前實體記憶體中的虛擬記憶體(通過頁面失效)的情況。此函式叫nopage。它用在Linux試圖將可執行映象的頁面調入記憶體時。
可執行映象對映到程序虛擬地址時將產生一組相應的vm_area_struct資料結構。每個vm_area_struct資料結構表示可執行映象的一部分:可執行程式碼、初始化資料(變數)、未初始化資料等等。Linux支援許多標準的虛擬記憶體操作函式,建立vm_area_struct資料結構時有一組相應的虛擬記憶體操作函式與之對應
空洞、buddy演算法及extendable hash
空洞UNIX 檔案中可以包含有空洞(holes)。如果一個使用者建立了一個檔案,然後將檔案指標 調整到一個很大的偏移(通過呼叫lseek 可在開啟檔案物件中設定偏移指標,再往裡寫入資料。這樣,該偏移前的空間中就沒有資料因此使形成了一個“空洞”。如果一個程序試圖從檔案“空洞”處讀取資料,它將得到全零位元組。檔案“空洞”有時候會很大,甚至整個磁碟塊都是“空洞”。為這樣的磁碟塊分配空間,無疑是很浪費的。解決方法是核心將di_addr 陣列的相應表項(既可能是直接塊,也可能是間接塊)置為零。當用戶試圖讀這樣一個塊時,核心將充滿0 的塊返回給使用者。只有當有人試圖往這個塊裡寫資料時核心才分配磁碟空間。拒絕為空洞分配空間有很重要的意義。一個程序在試圖往空洞裡寫資料時可能意外地超出了磁碟空間。如果複製一個包含空洞的檔案,新檔案在磁碟上可能會有充滿零的頁,而不是預期的空洞。這是因為複製檔案要先從原始檔中讀出內容,然後寫到目的檔案中。當核心讀取一個空洞時,它建立了一個充滿零的頁,然後該頁會被原樣複製到目的檔案中去。這樣,一些像tar 或cpio 之類的在檔案級而非原始磁碟級上操作的備份和歸檔工具便會出現問題。系統管理員可能要為一個檔案系統作備份,可是他會發現複製的資料在相同磁碟上卻沒有足夠的空間來恢復。
buddy演算法
buddy演算法是用來做記憶體管理的經典演算法,目的是為了解決記憶體的外碎片。
避免外碎片的方法有兩種:1,利用分頁單元把一組非連續的空閒頁框對映到非連續的線性地址區間。2,開發適當的技術來記錄現存的空閒連續頁框塊的情況,以儘量避免為滿足對小塊的請求而把大塊的空閒塊進行分割。
基於下面三種原因,核心選擇第二種避免方法:1,在某些情況下,連續的頁框確實必要。2,即使連續頁框的分配不是很必要,它在保持核心頁表不變方面所起的作用也是不容忽視的。假如修改頁表,則導致平均訪存次數增加,從而頻繁重新整理TLB。3,通過4M的頁可以訪問大塊連續的實體記憶體,相對於4K頁的使用,TLB未命中率降低,加快平均訪存速度。
buddy演算法將所有空閒頁框分組為10個塊連結串列,每個塊連結串列分別包含1,2,4,8,16,32,64,128,256,512個連續的頁框,每個塊的第一個頁框的實體地址是該塊大小的整數倍。如,大小為16個頁框的塊,其起始地址是16*2^12的倍數。
例,假設要請求一個128個頁框的塊,演算法先檢查128個頁框的連結串列是否有空閒塊,如果沒有則查256個頁框的連結串列,有則將256個頁框的塊分裂兩份,一份使用,一份插入128個頁框的連結串列。如果還沒有,就查512個頁框的連結串列,有的話就分裂為128,128,256,一個128使用,剩餘兩個插入對應連結串列。如果在512還沒查到,則返回出錯訊號。
回收過程相反,核心試圖把大小為b的空閒夥伴合併為一個大小為2b的單獨快,滿足以下條件的兩個塊稱為夥伴:1,兩個塊具有相同的大小,記做b;2,它們的實體地址是連續的,3,第一個塊的第一個頁框的實體地址是2*b*2^12的倍數,該演算法迭代,如果成功合併所釋放的塊,會試圖合併2b的塊來形成更大的塊。
extendable hash
使用hash的好處在於它能夠直接定位索引的資料,但當資料動態新增刪除時,就會有如何安置新加入的資料和回收多餘的空間的問題。
動態hash演算法可以解決利用hash對資料新增刪除時所遇到的問題。有關extendable hash的解釋可見
http://www.cs.sfu.ca/CC/354/zaiane/material/notes/Chapter11/node20.html
有空再寫個詳細些的解釋吧
|
|||
各種書籍中介紹的都很詳細,不再贅述,只提出一個值得注意的問題. 編輯者: xuweii (04-02-07 18:48)
|