
機器學習時代的三大神器:GBDT,XGBOOST和LightGBM
本文主要簡要的比較了常用的boosting演算法的一些區別,從AdaBoost到LightGBM,包括AdaBoost,GBDT,XGBoost,LightGBM四個模型的簡單介紹,一步一步從原理到優化對比。
AdaBoost原理
原始的AdaBoost演算法是在演算法開始的時候,為每一個樣本賦上一個權重值,初始的時候,大家都是一樣重要的。在每一步訓練中得到的模型,會使得資料點的估計有對有錯,我們就在每一步結束後,增加分錯的點的權重,減少分對的點的權重,這樣使得某些點如果老是被分錯,那麼就會被“重點關注”,也就被賦上一個很高的權重。然後等進行了N次迭代(由使用者指定),將會得到N個簡單的分類器(basic learner),然後我們將它們組合起來(比如說可以對它們進行加權、或者讓它們進行投票等),得到一個最終的模型。
關鍵字:樣本的權重分佈
GBDT概述
GBDT(Gradient Boosting Decison Tree)中的樹都是迴歸樹,GBDT用來做迴歸預測,調整後也可以用於分類(設定閾值,大於閾值為正例,反之為負例),可以發現多種有區分性的特徵以及特徵組合。GBDT是把所有樹的結論累加起來做最終結論的,GBDT的核心就在於,每一棵樹學的是之前所有樹結論和的殘差(負梯度),這個殘差就是一個加預測值後能得真實值的累加量。比如A的真實年齡是18歲,但第一棵樹的預測年齡是12歲,差了6歲,即殘差為6歲。那麼在第二棵樹裡我們把A的年齡設為6歲去學習,如果第二棵樹真的能把A分到6歲的葉子節點,那累加兩棵樹的結論就是A的真實年齡;如果第二棵樹的結論是5歲,則A仍然存在1歲的殘差,第三棵樹裡A的年齡就變成1歲,繼續學。 Boosting的最大好處在於,每一步的殘差計算其實變相地增大了分錯instance的權重,而已經分對的instance則都趨向於0。這樣後面的樹就能越來越專注那些前面被分錯的instance。
Gradient Boost與AdaBoost的區別
· Gradient Boost每一次的計算是為了減少上一次的殘差(residual),而為了消除殘差,我們可以在殘差減少的梯度(Gradient)方向上建立一個新的模型。所以說,在Gradient Boost中,每個新的模型的建立是為了使得之前模型的殘差往梯度方向減少。Shrinkage(縮減)的思想認為,每次走一小步逐漸逼近結果的效果,要比每次邁一大步很快逼近結果的方式更容易避免過擬合。即它不完全信任每一個棵殘差樹,它認為每棵樹只學到了真理的一小部分,累加的時候只累加一小部分,通過多學幾棵樹彌補不足。本質上,Shrinkage
· Adaboost是另一種boost方法,它按分類對錯,分配不同的weight,計算cost function時使用這些weight,從而讓“錯分的樣本權重越來越大,使它們更被重視”
Gradient Boost優缺點
· 優點:它的非線性變換比較多,表達能力強,而且不需要做複雜的特徵工程和特徵變換。
· 缺點:Boost是一個序列過程,不好並行化,而且計算複雜度高,同時不太適合高維稀疏特徵。
XGBoost
XGBoost能自動利用cpu的多執行緒,而且適當改進了gradient boosting,加了剪枝,控制了模型的複雜程度
· 傳統GBDT以CART作為基分類器,特指梯度提升決策樹演算法,而XGBoost還支援線性分類器(gblinear),這個時候XGBoost相當於帶L1和L2正則化項的邏輯斯蒂迴歸(分類問題)或者線性迴歸(迴歸問題)。
· 傳統GBDT在優化時只用到一階導數資訊,xgboost則對代價函式進行了二階泰勒展開,同時用到了一階和二階導數。順便提一下,xgboost工具支援自定義代價函式,只要函式可一階和二階求導。
· xgboost在代價函式里加入了正則項,用於控制模型的複雜度。正則項裡包含了樹的葉子節點個數、每個葉子節點上輸出的score的L2模的平方和。從Bias-variancetradeoff角度來講,正則項降低了模型的variance,使學習出來的模型更加簡單,防止過擬合,這也是xgboost優於傳統GBDT的一個特性。

· xgboost中樹節點分裂時所採用的公式:
· Shrinkage(縮減),相當於學習速率(xgboost中的eta)。xgboost在進行完一次迭代後,會將葉子節點的權重乘上該係數,主要是為了削弱每棵樹的影響,讓後面有更大的學習空間。實際應用中,一般把eta設定得小一點,然後迭代次數設定得大一點。(傳統GBDT的實現也有學習速率)
· 列抽樣(columnsubsampling)。xgboost借鑑了隨機森林的做法,支援列抽樣,不僅能降低過擬合,還能減少計算,這也是xgboost異於傳統gbdt的一個特性。
· 對缺失值的處理。對於特徵的值有缺失的樣本,xgboost可以自動學習出它的分裂方向。
· xgboost工具支援並行。注意xgboost的並行不是tree粒度的並行,xgboost也是一次迭代完才能進行下一次迭代的(第t次迭代的代價函式裡包含了前面t-1次迭代的預測值)。xgboost的並行是在特徵粒度上的。我們知道,決策樹的學習最耗時的一個步驟就是對特徵的值進行排序(因為要確定最佳分割點),xgboost在訓練之前,預先對資料進行了排序,然後儲存為block結構,後面的迭代中重複地使用這個結構,大大減小計算量。這個block結構也使得並行成為了可能,在進行節點的分裂時,需要計算每個特徵的增益,最終選增益最大的那個特徵去做分裂,那麼各個特徵的增益計算就可以開多執行緒進行。(特徵粒度上的並行,block結構,預排序)

· 這個公式形式上跟ID3演算法、CART演算法是一致的,都是用分裂後的某種值減去分裂前的某種值,從而得到增益。為了限制樹的生長,我們可以加入閾值,當增益大於閾值時才讓節點分裂,上式中的gamma即閾值,它是正則項裡葉子節點數T的係數,所以xgboost在優化目標函式的同時相當於做了預剪枝。另外,上式中還有一個係數lambda,是正則項裡leaf score的L2模平方的係數,對leaf score做了平滑,也起到了防止過擬合的作用,這個是傳統GBDT裡不具備的特性。
· XGBoost實現層面
· 內建交叉驗證方法
· 能夠輸出特徵重要性檔案輔助特徵篩選
XGBoost優勢小結:
· 顯式地將樹模型的複雜度作為正則項加在優化目標
· 公式推導裡用到了二階導數資訊,而普通的GBDT只用到一階
· 允許使用列抽樣(column(feature)sampling)來防止過擬合,借鑑了Random Forest的思想,sklearn裡的gbm好像也有類似實現。
· 實現了一種分裂節點尋找的近似演算法,用於加速和減小記憶體消耗。
· 節點分裂演算法能自動利用特徵的稀疏性。
· 樣本資料事先排好序並以block的形式儲存,利於平行計算
· penalty function Omega主要是對樹的葉子數和葉子分數做懲罰,這點確保了樹的簡單性。
· 支援分散式計算可以執行在MPI,YARN上,得益於底層支援容錯的分散式通訊框架rabit。
LightGBM
lightGBM:基於決策樹演算法的分散式梯度提升框架。
lightGBM與XGBoost的區別:
· 切分演算法(切分點的選取)
· 佔用的記憶體更低,只儲存特徵離散化後的值,而這個值一般用8位整型儲存就足夠了,記憶體消耗可以降低為原來的1/8。
· 降低了計算的代價:預排序演算法每遍歷一個特徵值就需要計算一次分裂的增益,而直方圖演算法只需要計算k次(k可以認為是常數),時間複雜度從O(#data#feature)優化到O(k#features)。(相當於LightGBM犧牲了一部分切分的精確性來提高切分的效率,實際應用中效果還不錯)
· 空間消耗大,需要儲存資料的特徵值以及特徵排序的結果(比如排序後的索引,為了後續快速計算分割點),需要消耗兩倍於訓練資料的記憶體
· 時間上也有較大開銷,遍歷每個分割點時都需要進行分裂增益的計算,消耗代價大
· 對cache優化不友好,在預排序後,特徵對梯度的訪問是一種隨機訪問,並且不同的特徵訪問的順序不一樣,無法對cache進行優化。同時,在每一層長樹的時候,需要隨機訪問一個行索引到葉子索引的陣列,並且不同特徵訪問的順序也不一樣,也會造成較大的cache miss。
· XGBoost使用的是pre-sorted演算法(對所有特徵都按照特徵的數值進行預排序,基本思想是對所有特徵都按照特徵的數值進行預排序;然後在遍歷分割點的時候用O(#data)的代價找到一個特徵上的最好分割點最後,找到一個特徵的分割點後,將資料分裂成左右子節點。優點是能夠更精確的找到資料分隔點;但這種做法有以下缺點
· LightGBM使用的是histogram演算法,基本思想是先把連續的浮點特徵值離散化成k個整數,同時構造一個寬度為k的直方圖。在遍歷資料的時候,根據離散化後的值作為索引在直方圖中累積統計量,當遍歷一次資料後,直方圖累積了需要的統計量,然後根據直方圖的離散值,遍歷尋找最優的分割點;優點在於
· 決策樹生長策略上:
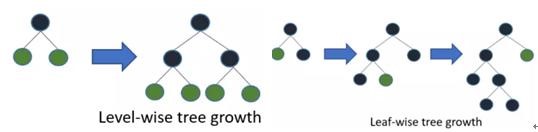
· XGBoost採用的是帶深度限制的level-wise生長策略,Level-wise過一次資料可以能夠同時分裂同一層的葉子,容易進行多執行緒優化,不容易過擬合;但不加區分的對待同一層的葉子,帶來了很多沒必要的開銷(因為實際上很多葉子的分裂增益較低,沒必要進行搜尋和分裂)
· LightGBM採用leaf-wise生長策略,每次從當前所有葉子中找到分裂增益最大(一般也是資料量最大)的一個葉子,然後分裂,如此迴圈;但會生長出比較深的決策樹,產生過擬合(因此 LightGBM 在leaf-wise之上增加了一個最大深度的限制,在保證高效率的同時防止過擬合)。
·
· histogram 做差加速。一個容易觀察到的現象:一個葉子的直方圖可以由它的父親節點的直方圖與它兄弟的直方圖做差得到。通常構造直方圖,需要遍歷該葉子上的所有資料,但直方圖做差僅需遍歷直方圖的k個桶。利用這個方法,LightGBM可以在構造一個葉子的直方圖後,可以用非常微小的代價得到它兄弟葉子的直方圖,在速度上可以提升一倍。
· 直接支援類別特徵:LightGBM優化了對類別特徵的支援,可以直接輸入類別特徵,不需要額外的0/1展開。並在決策樹演算法上增加了類別特徵的決策規則。
· 分散式訓練方法上(並行優化)
· 在特徵並行演算法中,通過在本地儲存全部資料避免對資料切分結果的通訊;
· 在資料並行中使用分散規約(Reducescatter)把直方圖合併的任務分攤到不同的機器,降低通訊和計算,並利用直方圖做差,進一步減少了一半的通訊量。基於投票的資料並行(ParallelVoting)則進一步優化資料並行中的通訊代價,使通訊代價變成常數級別。
· 特徵並行的主要思想是在不同機器在不同的特徵集合上分別尋找最優的分割點,然後在機器間同步最優的分割點。
· 資料並行則是讓不同的機器先在本地構造直方圖,然後進行全域性的合併,最後在合併的直方圖上面尋找最優分割點。
· 原始
· LightGBM針對這兩種並行方法都做了優化,
· Cache命中率優化
· 基於直方圖的稀疏特徵優化
· DART(Dropout + GBDT)
· GOSS(Gradient-based One-Side Sampling):一種新的Bagging(row subsample)方法,前若干輪(1.0f /gbdtconfig->learning_rate)不Bagging;之後Bagging時, 取樣一定比例g(梯度)大的樣本
LightGBM優點小結(相較於XGBoost)
· 速度更快
· 記憶體消耗更低