
使用網頁爬蟲(高階搜尋功能)蒐集含關鍵詞新浪微博資料
作為國內社交媒體的領航者,很遺憾,新浪微博沒有提供以“關鍵字+時間+區域”方式獲取的官方API。當我們看到國外科研成果都是基於某關鍵字獲得的社交媒體資料,心中不免涼了一大截,或者轉戰推特。再次建議微博能更開放些!
1、切入點
慶幸的是,新浪提供了高階搜尋功能。找不到?這個功能需要使用者登入才能使用……沒關係,下面將詳細講述如何在無須登入的情況下,獲取“關鍵字+時間+區域”的新浪微博。
首先我們還是要登入一下,看看到底是個什麼樣的功能。

然後我們看看位址列:
- http://s.weibo.com/wb/%25E4%25B8%25AD%25E5%259B%25BD%25E5%25A5%25BD%25E5%25A3%25B0%25E9%259F%25B3&xsort=time®ion=custom:11:1000×cope=custom:2014-07-09-2:2014-07-19-4&Refer=g
這麼長?其實蠻清晰、簡單的。解析如下:
固定地址部分:http://s.weibo.com/wb/
關鍵字(2次URLEncode編碼):%25E4%25B8%25AD%25E5%259B%25BD%25E5%25A5%25BD%25E5%25A3%25B0%25E9%259F%25B3
返回微博的排序方式(此處為“實時”):xsort=time
搜尋地區:region=custom:11:1000
搜尋時間範圍:timescope=custom:2013-07-02-2:2013-07-09-2
可忽略項:Refer=g
是否顯示類似微博(未出現):nodup=1 注:加上這個選項可多收集微博,建議加上。預設為省略引數,即省略部分相似微博。
某次請求的頁數(未出現):page=1
既然是這麼回事,我們接下來就可以使用網頁爬蟲的方式獲取“關鍵字+時間+區域”的微博了……
2、採集思路
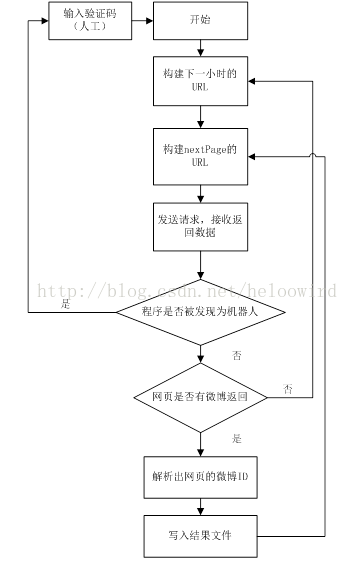
大體思路如下:構造URL,爬取網頁,然後解析網頁中的微博資訊,如下圖所示。微博官方提供了根據微博ID進行查詢的微博資訊的API,故本文只負責講述收集微博ID。
另外,高階搜尋最多返回50頁微博,那麼時間間隔設定最小為宜。所以時間範圍(timescope)可設定為1小時,如2013-07-01-2:2013-07-01-2。
目前沒有模擬登陸,所以需要設定兩個鄰近URL請求之間的隨機休眠時間,過於頻繁會被認為是機器人,你懂的。
3、具體實現
作為爬蟲小工具,用python非常適合。作為python初學者,不要怪我寫得像java。首先實現一個爬取每個小時的類。
- class CollectData():
- """每小時資料收集類
- 利用微博高階搜尋功能,按關鍵字蒐集一定時間範圍內的微博。
- 大體思路:構造URL,爬取網頁,然後解析網頁中的微博ID。後續利用微博API進行資料入庫。本程式只負責收集微博的ID。
- 登陸新浪微博,進入高階搜尋,輸入關鍵字”空氣汙染“,選擇”實時“,時間為”2013-07-02-2:2013-07-09-2“,地區為”北京“,之後傳送請求會發現位址列變為如下:
- http://s.weibo.com/wb/%25E7%25A9%25BA%25E6%25B0%2594%25E6%25B1%25A1%25E6%259F%2593&xsort=time®ion=custom:11:1000×cope=custom:2013-07-02-2:2013-07-09-2&Refer=g
- 固定地址部分:http://s.weibo.com/wb/
- 關鍵字二次UTF-8編碼:%25E7%25A9%25BA%25E6%25B0%2594%25E6%25B1%25A1%25E6%259F%2593
- 排序為“實時”:xsort=time
- 搜尋地區:region=custom:11:1000
- 搜尋時間範圍:timescope=custom:2013-07-02-2:2013-07-09-2
- 可忽略項:Refer=g
- 顯示類似微博:nodup=1 注:這個選項可多收集微博,建議加上。預設不加此引數,省略了部分相似微博。
- 某次請求的頁數:page=1
- 另外,高階搜尋最多返回50頁微博,那麼時間間隔設定最小為宜。所以該類設定為蒐集一定時間段內最多50頁微博。
- """
- def __init__(self, keyword, startTime, region, savedir, interval='50', flag=True, begin_url_per = "http://s.weibo.com/weibo/"):
- self.begin_url_per = begin_url_per #設定固定地址部分,預設為"http://s.weibo.com/weibo/",或者"http://s.weibo.com/wb/"
- self.setKeyword(keyword) #設定關鍵字
- self.setStartTimescope(startTime) #設定搜尋的開始時間
- self.setRegion(region) #設定搜尋區域
- self.setSave_dir(savedir) #設定結果的儲存目錄
- self.setInterval(interval) #設定鄰近網頁請求之間的基礎時間間隔(注意:過於頻繁會被認為是機器人)
- self.setFlag(flag) #設定
- self.logger = logging.getLogger('main.CollectData') #初始化日誌
- ##設定關鍵字
- ##關鍵字需解碼
- def setKeyword(self, keyword):
- self.keyword = keyword.decode('GBK').encode("utf-8")
- print'twice encode:',self.getKeyWord()
- ##設定起始範圍,間隔為1小時
- ##格式為:yyyy-mm-dd-HH
- def setStartTimescope(self, startTime):
- ifnot (startTime == '-'):
- self.timescope = startTime + ":" + startTime
- else:
- self.timescope = '-'
- ##設定搜尋地區
- def setRegion(self, region):
- self.region = region
- ##設定結果的儲存目錄
- def setSave_dir(self, save_dir):
- self.save_dir = save_dir
- ifnot os.path.exists(self.save_dir):
- os.mkdir(self.save_dir)
- ##設定鄰近網頁請求之間的基礎時間間隔
- def setInterval(self, interval):
- self.interval = int(interval)
- ##設定是否被認為機器人的標誌。若為False,需要進入頁面,手動輸入驗證碼
- def setFlag(self, flag):
- self.flag = flag
- ##構建URL
- def getURL(self):
- returnself.begin_url_per+self.getKeyWord()+"®ion=custom:"+self.region+"&xsort=time×cope=custom:"+self.timescope+"&nodup=1&page="
- ##關鍵字需要進行兩次urlencode
- def getKeyWord(self):
- once = urllib.urlencode({"kw":self.keyword})[3:]
- return urllib.urlencode({"kw":once})[3:]
- ##爬取一次請求中的所有網頁,最多返回50頁
- def download(self, url, maxTryNum=4):
- content = open(self.save_dir + os.sep + "weibo_ids.txt", "ab") #向結果檔案中寫微博ID
- hasMore = True#某次請求可能少於50頁,設定標記,判斷是否還有下一頁
- isCaught = False#某次請求被認為是機器人,設定標記,判斷是否被抓住。抓住後,需要複製log中的檔案,進入頁面,輸入驗證碼
- mid_filter = set([]) #過濾重複的微博ID
- i = 1#記錄本次請求所返回的頁數
- while hasMore and i < 51and (not isCaught): #最多返回50頁,對每頁進行解析,並寫入結果檔案
- source_url = url + str(i) #構建某頁的URL
- data = ''#儲存該頁的網頁資料
- goon = True#網路中斷標記
- ##網路不好的情況,試著嘗試請求三次
- for tryNum in range(maxTryNum):
- try:
- html = urllib2.urlopen(source_url, timeout=12)
- data = html.read()
- break
- except:
- if tryNum < (maxTryNum-1):
- time.sleep(10)
- else:
- print'Internet Connect Error!'
- self.logger.error('Internet Connect Error!')
- self.logger.info('filePath: ' + savedir)
- self.logger.info('url: ' + source_url) <