
MapReduce程式設計-新浪微博內容相關(內容 廣告有效推薦)
阿新 • • 發佈:2018-12-22
通過之前的幾個MR程式的場景樣例,我們簡單瞭解了一些MR程式設計和離線計算的相關知識。這篇博文 我們對MapReduce進行進一步的運用和解讀。
案例場景:
現在我們有一批新浪微博的資料資訊(當然,這裡的資料集是經過處理的,但並不影響我們的專案樣例編寫)。資料資訊是使用者id和其對應的微博內容。現在 我們希望根據原始資料集中的資料,給相對應的微博使用者推薦他所感興趣的內容或者廣告。
案例的作用是根據根據每個使用者發的多條微博 得到詞條在當前使用者中的權重,以方便我們推薦相對應的內容或廣告
資料集
左邊是使用者id ,右邊是微博內容
3823890201582094 今天我約了豆漿,油條。約了電飯煲幾小時後飯就自動煮好,還想約豆漿機,讓我早晨多睡一小時,豆漿就自然好。起床就可以喝上香噴噴的豆漿了。 3823890210294392 今天我約了豆漿,油條 3823890235477306 一會兒帶兒子去動物園約起~ 3823890239358658 繼續支援 3823890256464940 約起來!次飯去! 3823890264861035 我約了吃飯哦 3823890281649563 和家人一起相約吃個飯! 3823890285529671 今天約了廣場一起滑旱冰 3823890294242412 九陽雙預約豆漿機即將全球首發啦,我要約你一起吃早餐 3823890314914825 今天天氣晴好,姐妹們約起,一起去逛街。 3823890323625419 全國包郵!九陽(Joyoung)JYL- 3823890335901756 今天是今年最暖和的一天,果斷出來逛街! ......
程式碼實現
這裡我們利用mapreduce進行離線計算,利用3個mapreduce方法進行計算,第一個MR計算當前詞條在某個使用者所發微博裡面出現的詞頻和資料集的微博總數(這裡partition分割槽分為4個,對應4個reduce任務,前三個為詞條出現的詞頻,第四個為統計微博總數)。第二個MR統計每個詞條在多少個微博裡面出現過,第二個MR的輸入是第一個MR輸出的前三個檔案(不包含微博總數)。第三個MR是根據前面兩個得到的資料結果 計算得到每條微博裡面每個詞條所站的權重,以此方便相關廣告推送。
第一個MR程式:當前詞條在某個使用者所發微博裡面出現的詞頻和資料集的微博總數
MR程式執行的主方法:
public class FirstJob { public static void main(String[] args) { Configuration config =new Configuration(); config.set("fs.defaultFS", "hdfs://xjh:9000"); config.set("yarn.resourcemanager.hostname", "xjh"); try { FileSystem fs =FileSystem.get(config); // JobConf job =new JobConf(config); Job job =Job.getInstance(config); job.setJarByClass(FirstJob.class); job.setJobName("weibo1"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // job.setMapperClass(); job.setNumReduceTasks(4); //設定4個reduce 最後一個reduce記錄微博總數 job.setPartitionerClass(FirstPartition.class); job.setMapperClass(FirstMapper.class); job.setCombinerClass(FirstReduce.class); job.setReducerClass(FirstReduce.class); FileInputFormat.addInputPath(job, new Path("/MapReduce/input/weibo")); Path path =new Path("/MapReduce/weibo/output"); if(fs.exists(path)){ fs.delete(path, true); } FileOutputFormat.setOutputPath(job,path); boolean f= job.waitForCompletion(true); if(f){ } } catch (Exception e) { e.printStackTrace(); } } }
呼叫的map方法:計算TF(總詞頻)和計算N(微博總數)
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
String[] v =value.toString().trim().split("\t"); //通過\t進行String型別的分解
if(v.length>=2){
String id=v[0].trim(); //前面為id
String content =v[1].trim(); //後面為微博的具體內容 磁條
StringReader sr =new StringReader(content);
IKSegmenter ikSegmenter =new IKSegmenter(sr, true); //IKSegmenter為分詞器
Lexeme word=null;
while( (word=ikSegmenter.next()) !=null ){
String w= word.getLexemeText();
context.write(new Text(w+"_"+id), new IntWritable(1));
}
context.write(new Text("count"), new IntWritable(1));
}else{
System.out.println(value.toString()+"-------------");
}
}
呼叫的reduce方法:
protected void reduce(Text arg0, Iterable<IntWritable> arg1,
Context arg2)
throws IOException, InterruptedException {
int sum =0;
for( IntWritable i :arg1 ){
sum= sum+i.get();
}
if(arg0.equals(new Text("count"))){
System.out.println(arg0.toString() +"___________"+sum);
}
arg2.write(arg0, new IntWritable(sum));
}
主方法中呼叫的分割槽方法:
public int getPartition(Text key, IntWritable value, int reduceCount) {
if(key.equals(new Text("count")))
return 3; //這裡的3 是根據reduce設計來決定的 這裡reduce至少是2個 一個是微博總數 一個是pi(實質上這裡是有4個 0 1 2 3)
else
return super.getPartition(key, value, reduceCount-1);
}
執行結果:
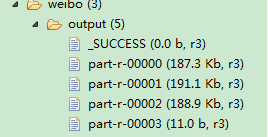
前三個part輸出部分截圖:
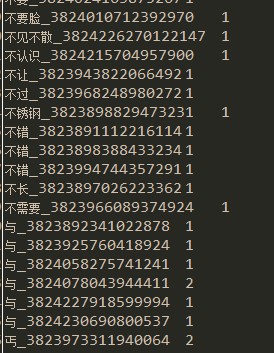
part-r-00003輸出:
count 1065
第二個MR程式:統計df(詞在多少個微博中出現過)
MR程式執行的主方法:
public static void main(String[] args) {
Configuration config =new Configuration();
config.set("fs.defaultFS", "hdfs://xjh:9000");
config.set("yarn.resourcemanager.hostname", "xjh");
try {
// JobConf job =new JobConf(config);
Job job =Job.getInstance(config);
job.setJarByClass(TwoJob.class);
job.setJobName("weibo2");
//設定map任務的輸出key型別、value型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// job.setMapperClass();
job.setMapperClass(TwoMapper.class);
job.setCombinerClass(TwoReduce.class);
job.setReducerClass(TwoReduce.class);
//mr執行時的輸入資料從hdfs的哪個目錄中獲取
FileInputFormat.addInputPath(job, new Path("/MapReduce/weibo/output"));
FileOutputFormat.setOutputPath(job, new Path("/MapReduce/weibo/output2"));
boolean f= job.waitForCompletion(true);
if(f){
System.out.println("執行job成功");
}
} catch (Exception e) {
e.printStackTrace();
}
}
map方法:
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//獲取當前 mapper task的資料片段(split)
FileSplit fs = (FileSplit) context.getInputSplit();
if (!fs.getPath().getName().contains("part-r-00003")) {
//第二個mapreduce的輸入是 第一個mapreduce的輸出 這裡只取前三個有效輸出(第四個為微博總數,這裡不用)
String[] v = value.toString().trim().split("\t");
if (v.length >= 2) {
String[] ss = v[0].split("_");
if (ss.length >= 2) {
String w = ss[0];
context.write(new Text(w), new IntWritable(1));
}
} else {
System.out.println(value.toString() + "-------------");
}
}
}
reduce方法:
protected void reduce(Text key, Iterable<IntWritable> arg1,
Context context)
throws IOException, InterruptedException {
int sum =0;
for( IntWritable i :arg1 ){
sum= sum+i.get(); //累加次數
}
context.write(key, new IntWritable(sum));
}
執行結果(部分截圖所示):
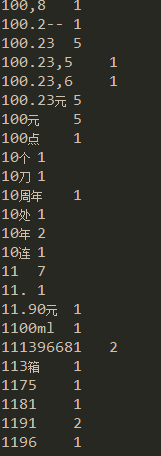
第三個MR程式:到這裡 一共經過三次mapreduce方法 最終得到的結果是根據每個使用者所發的微博 得到每個詞條所造微博的權重
案例的作用是根據相應詞條得到最相關微博
MR執行的主方法:
public static void main(String[] args) {
Configuration config =new Configuration();
config.set("fs.defaultFS", "hdfs://xjh:9000");
config.set("yarn.resourcemanager.hostname", "xjh");
// config.set("mapred.jar", "C:\\Users\\Administrator\\Desktop\\weibo3.jar");
try {
FileSystem fs =FileSystem.get(config);
// JobConf job =new JobConf(config);
Job job =Job.getInstance(config);
job.setJarByClass(LastJob.class);
job.setJobName("weibo3");
// DistributedCache.addCacheFile(uri, conf);
//2.5
//把微博總數載入到記憶體
job.addCacheFile(new Path("/MapReduce/weibo/output/part-r-00003").toUri());
//把df(某個詞條在多少文章中出現過)載入到記憶體
job.addCacheFile(new Path("/MapReduce/weibo/output2/part-r-00000").toUri());
//設定map任務的輸出key型別、value型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// job.setMapperClass();
job.setMapperClass(LastMapper.class);
job.setReducerClass(LastReduce.class);
//mr執行時的輸入資料從hdfs的哪個目錄中獲取
FileInputFormat.addInputPath(job, new Path("/MapReduce/weibo/output"));
Path outpath =new Path("/MapReduce/weibo/output3");
if(fs.exists(outpath)){
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job,outpath );
boolean f= job.waitForCompletion(true);
if(f){
System.out.println("執行job成功");
}
} catch (Exception e) {
e.printStackTrace();
}
}
map方法:
//存放微博總數
public static Map<String, Integer> cmap = null;
//存放df
public static Map<String, Integer> df = null;
/**
* 在map方法執行之前
* 程式在map方法例項化之前呼叫setup方法 只會執行一次
* 這個時候map方法並沒有開始執行
*/
protected void setup(Context context) throws IOException,
InterruptedException {
System.out.println("******************");
if (cmap == null || cmap.size() == 0 || df == null || df.size() == 0) {
URI[] ss = context.getCacheFiles(); //從記憶體中獲取
if (ss != null) {
for (int i = 0; i < ss.length; i++) {
URI uri = ss[i];
if (uri.getPath().endsWith("part-r-00003")) {//微博總數
Path path =new Path(uri.getPath());
// FileSystem fs =FileSystem.get(context.getConfiguration());
// fs.open(path);
BufferedReader br = new BufferedReader(new FileReader(path.getName()));
String line = br.readLine();
if (line.startsWith("count")) {
String[] ls = line.split("\t");
cmap = new HashMap<String, Integer>();
cmap.put(ls[0], Integer.parseInt(ls[1].trim()));
}
br.close();
} else if (uri.getPath().endsWith("part-r-00000")) {//詞條的DF
df = new HashMap<String, Integer>();
Path path =new Path(uri.getPath());
BufferedReader br = new BufferedReader(new FileReader(path.getName()));
String line;
while ((line = br.readLine()) != null) {
String[] ls = line.split("\t");
df.put(ls[0], Integer.parseInt(ls[1].trim()));
}
br.close();
}
}
}
}
}
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
FileSplit fs = (FileSplit) context.getInputSplit();
// System.out.println("--------------------");
if (!fs.getPath().getName().contains("part-r-00003")) {
String[] v = value.toString().trim().split("\t");
if (v.length >= 2) {
int tf =Integer.parseInt(v[1].trim());//tf值
String[] ss = v[0].split("_");
if (ss.length >= 2) {
String w = ss[0];
String id=ss[1];
double s=tf * Math.log(cmap.get("count")/df.get(w));
NumberFormat nf =NumberFormat.getInstance();
nf.setMaximumFractionDigits(5);
context.write(new Text(id), new Text(w+":"+nf.format(s)));
}
} else {
System.out.println(value.toString() + "-------------");
}
}
}
reduce方法:
protected void reduce(Text key, Iterable<Text> arg1,
Context context)
throws IOException, InterruptedException {
StringBuffer sb =new StringBuffer();
for( Text i :arg1 ){
sb.append(i.toString()+"\t");
}
context.write(key, new Text(sb.toString()));
}
執行結果(部分截圖):
