Spark RDD操作之ReduceByKey
阿新 • • 發佈:2019-03-04

一、reduceByKey作用
reduceByKey將RDD中所有K,V對中,K值相同的V進行合併,而這個合併,僅僅根據使用者傳入的函式來進行,下面是wordcount的例子。
import java.util.Arrays; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; public class WordCount { public static void main(String[] args) { SparkConf conf = new SparkConf().setAppName("spark WordCount!").setMaster("local[*]"); JavaSparkContext javaSparkContext = new JavaSparkContext(conf); List<Tuple2<String, Integer>> list = Arrays.asList(new Tuple2<String, Integer>("hello", 1), new Tuple2<String, Integer>("word", 1), new Tuple2<String, Integer>("hello", 1), new Tuple2<String, Integer>("simple", 1)); JavaPairRDD<String, Integer> listRDD = javaSparkContext.parallelizePairs(list); /** * spark的shuffle是hash-based的,也就是reduceByKey運算元的兩個入參一個是來源於hashmap,一個來源於從map端拉取的資料,對於wordcount例子而言,進行如下執行 * hashMap.get(Key)+ Value,計算結果重新put回hashmap,迴圈往復,就迭代出了最後結果 */ JavaPairRDD<String, Integer> wordCountPair = listRDD.reduceByKey(new Function2<Integer, Integer, Integer>() { @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1 + v2; } }); wordCountPair.foreach(new VoidFunction<Tuple2<String, Integer>>() { @Override public void call(Tuple2<String, Integer> tuple) throws Exception { System.out.println(tuple._1 + ":" + tuple._2); } }); } }
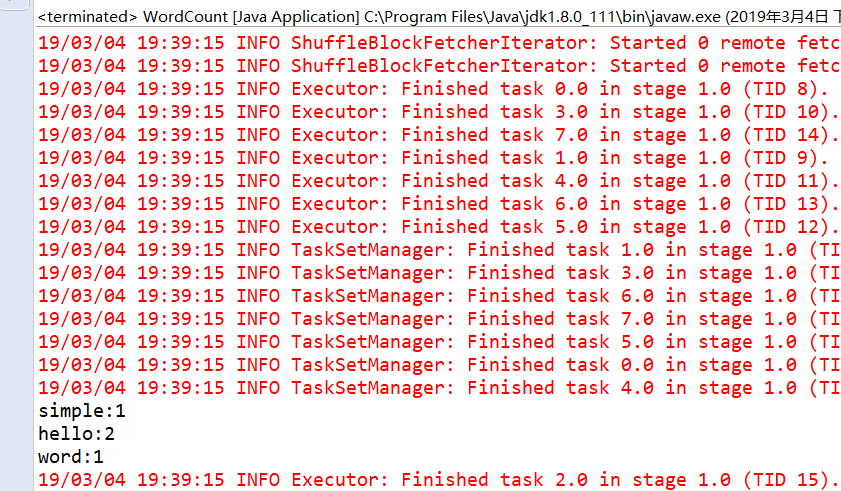
計算結果:
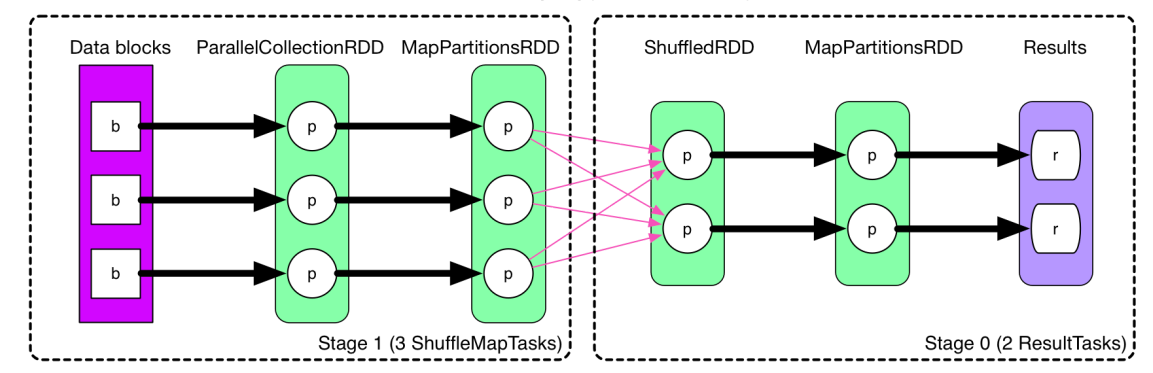
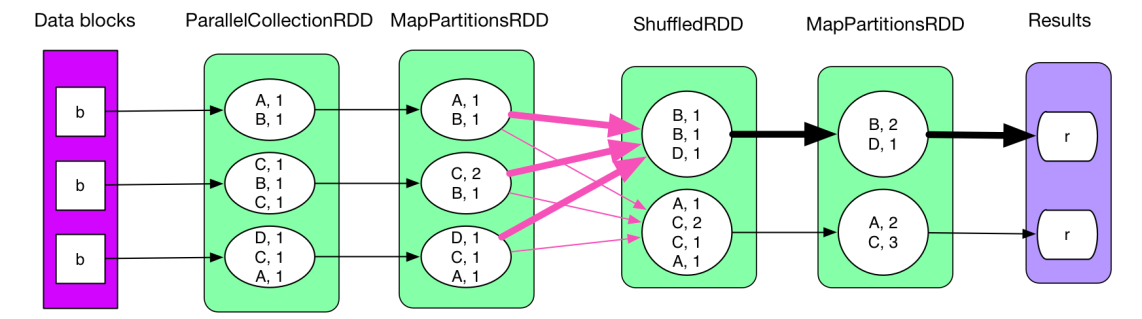
二、reduceByKey的原理如下圖