
神經網絡的雙曲線正切激活函數
分享一下我老師大神的人工智能教程吧。零基礎!通俗易懂!風趣幽默!還帶黃段子!希望你也加入到我們人工智能的隊伍中來!http://www.captainbed.net
在數學中,雙曲函數類似於常見的(也叫圓函數的)三角函數。基本雙曲函數是雙曲正弦“sinh”,雙曲余弦“cosh”,從它們導出雙曲正切“tanh”等。也類似於三角函數的推導。反函數是反雙曲正弦“arsinh”(也叫做“arcsinh”或“asinh”)依此類推。

y=tanh x,定義域:R,值域:(-1,1),奇函數,函數圖像為過原點並且穿越Ⅰ、Ⅲ象限的嚴格單調遞增曲線,其圖像被限制在兩水平漸近線y=1和y=-1之間。
它的導數如下:
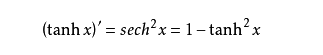
它的曲線圖:
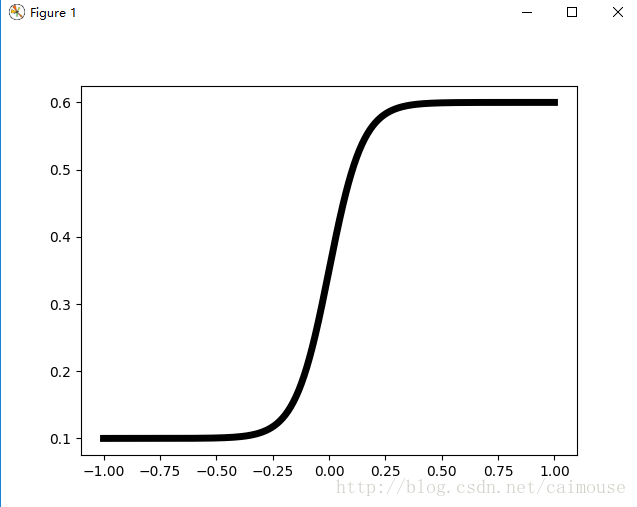
源碼:
#python 3.5.3/TensorFlow 1.0/win 10
#2017-03-27 蔡軍生 http://blog.csdn.net/caimouse
#
import pylab
import numpy as np
N = 500
delta = 0.6
X = -1 + 2. * np.arange(N) / (N - 1)
pylab.plot(X, (1.4 + np.tanh(4. * X / delta)) / 4, ‘k-‘,linewidth = 5)
pylab.show()它的意義:
第一個問題:為什麽引入非線性激勵函數?
如果不用激勵函數(其實相當於激勵函數是f(x) = x),在這種情況下你每一層輸出都是上層輸入的線性函數,很容易驗證,無論你神經網絡有多少層,輸出都是輸入的線性組合,與沒有隱藏層效果相當,這種情況就是最原始的感知機(Perceptron)了。
正因為上面的原因,我們決定引入非線性函數作為激勵函數,這樣深層神經網絡就有意義了(不再是輸入的線性組合,可以逼近任意函數)。最早的想法是sigmoid函數或者tanh函數,輸出有界,很容易充當下一層輸入(以及一些人的生物解釋balabala)。
第二個問題:為什麽引入Relu呢?
第一,采用sigmoid等函數,算激活函數時(指數運算),計算量大,反向傳播求誤差梯度時,求導涉及除法,計算量相對大,而采用Relu激活函數,整個過程的計算量節省很多。
第三,Relu會使一部分神經元的輸出為0,這樣就造成了網絡的稀疏性,並且減少了參數的相互依存關系,緩解了過擬合問題的發生(以及一些人的生物解釋balabala)。
當然現在也有一些對relu的改進,比如prelu,random relu等,在不同的數據集上會有一些訓練速度上或者準確率上的改進,具體的大家可以找相關的paper看。
多加一句,現在主流的做法,會在做完relu之後,加一步batch normalization,盡可能保證每一層網絡的輸入具有相同的分布[1]。而最新的paper[2],他們在加入bypass connection之後,發現改變batch normalization的位置會有更好的效果。大家有興趣可以看下。
1. TensorFlow API攻略
http://edu.csdn.net/course/detail/44952. TensorFlow入門基本教程 http://edu.csdn.net/course/detail/4369
3. C++標準模板庫從入門到精通
http://edu.csdn.net/course/detail/33244.跟老菜鳥學C++
http://edu.csdn.net/course/detail/2901
5. 跟老菜鳥學python
http://edu.csdn.net/course/detail/25926. 在VC2015裏學會使用tinyxml庫
http://edu.csdn.net/course/detail/25907. 在Windows下SVN的版本管理與實戰
http://edu.csdn.net/course/detail/2579
8.Visual Studio 2015開發C++程序的基本使用
http://edu.csdn.net/course/detail/2570
9.在VC2015裏使用protobuf協議
http://edu.csdn.net/course/detail/258210.在VC2015裏學會使用MySQL數據庫
http://edu.csdn.net/course/detail/2672
再分享一下我老師大神的人工智能教程吧。零基礎!通俗易懂!風趣幽默!還帶黃段子!希望你也加入到我們人工智能的隊伍中來!http://www.captainbed.net
神經網絡的雙曲線正切激活函數