
用Python爬取"王者農藥"英雄面板


0.引言
作為一款現象級遊戲,王者榮耀,想必大家都玩過或聽過,遊戲裡中各式各樣的英雄,每款面板都非常精美,用做電腦桌布再合適不過了。本篇就來教大家如何使用Python來爬取這些精美的英雄面板。
1.環境
作業系統:Windows / Linux
Python版本:3.7.2
2.需求分析
我們開啟《王者榮耀》官網,找定位到英雄列表的頁面
可直接點此連結:
https://pvp.qq.com/web201605/herolist.shtml 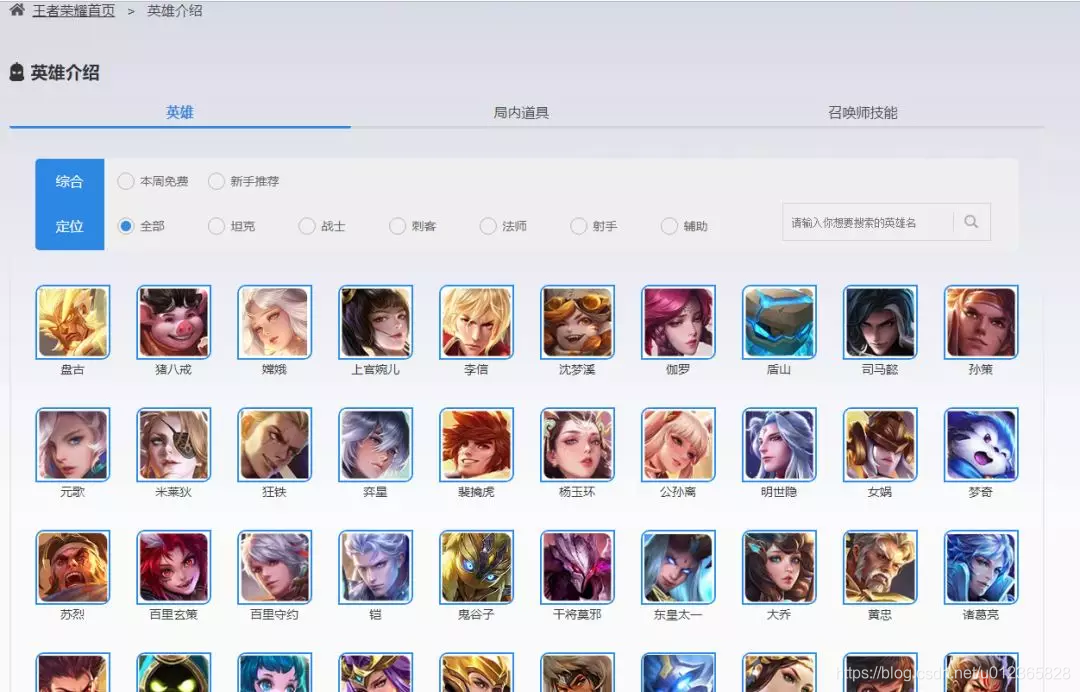
在這個網頁中包含了所有的英雄,頭像及英雄名稱。點選其中一個英雄的頭像,如“嫦娥”,進去後如下圖:
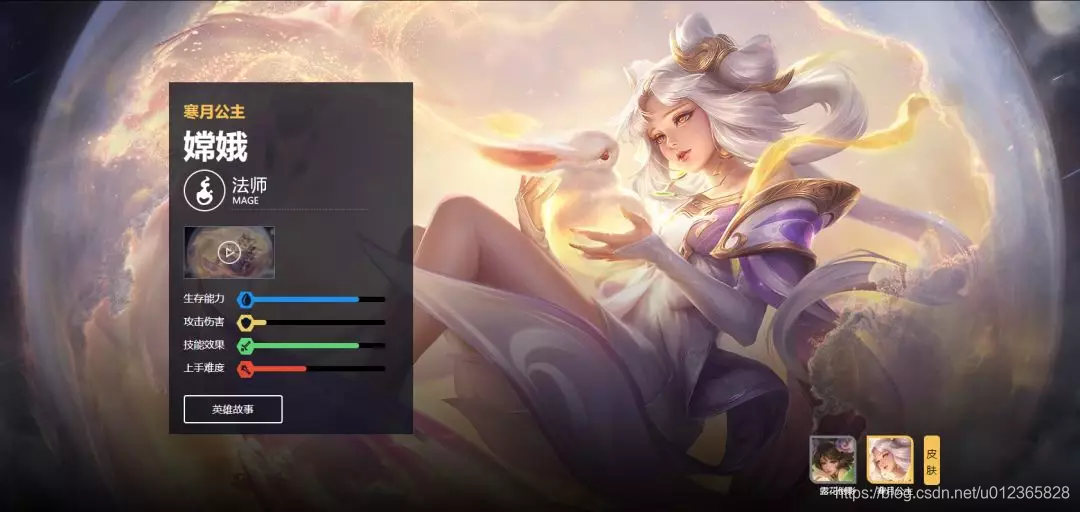
我們記下此時的網址
https://pvp.qq.com/web201605/herodetail/515.shtml
再後退到英雄列表頁面,點“甄姬”進去檢視:
https://pvp.qq.com/web201605/herodetail/127.shtml
可以看到這些網址幾乎是固定不變的,變化的只是515、127這些數字,這些其實就是代表的英雄數字編號。
那麼第一個關鍵點就來了,怎麼找出各個英雄所對應的數字編號呢?
我們回到最初的英雄列表頁面,開啟瀏覽器的開發者工具<F12>,重新整理頁面、仔細觀察,你會找到一個herolist.json的檔案,如圖所示:
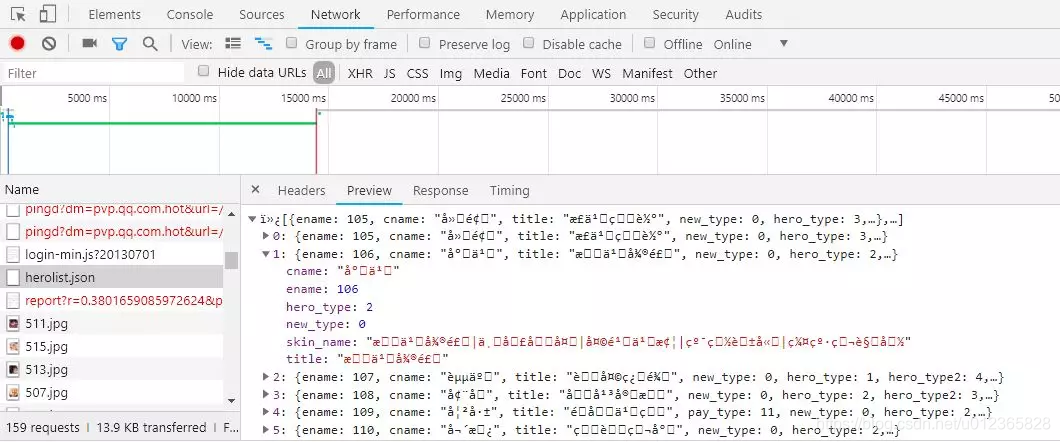
這裡記錄了各個英雄的資訊,其中就包含了每個英雄對應的數字編號了,請忽略這裡截圖中的亂碼顯示。我們切到herolist.json中的Headers,就可以拿到該請求的URL地址,進而就可以把英雄及其對應的數字,編號都提取出來了。
有了英雄編號的對應關係,再找尋下英雄面板的連結規律。
現在重新進入一個英雄的網址,開啟瀏覽器的開發者工具,重新整理頁面,在Network下重新整理並找到英雄的面板圖片,如圖所示:
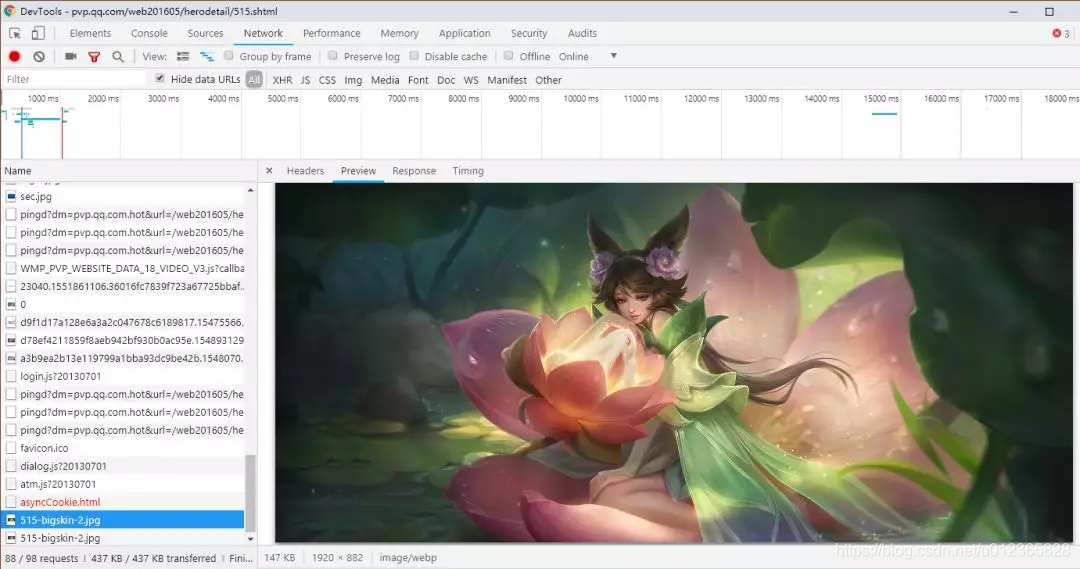
在Headers中檢視該圖片的網址,檢視即Request URL處的連結:
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/515/515-bigskin-1.jpg
{kind=link}
找尋一個看看
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/529/529-bigskin-1.jpg
{kind=link}
繼續尋一個看看
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/127/127-bigskin-4.jpg
{kind=link}
仔細分析如上三個連結,我們可以把英雄面板的URL拆分開來看。它是由一個固定字首(我們可以記為base_url),再加上英雄數字編號、"bigskin"、面板編號、".jpg"組合而成,如下:
base_url / hero_num / hero_num - bigskin - heroskin_num .jpg
拿到了各個英雄面板的URL地址後,我們就可以進行圖片的下載並儲存在本地了。
3.程式碼演示
首先匯入我們所用到的模組
import requests
import os
注:requests是非內建模組,若環境中沒有,需自行安裝:
pip install requests
3.1 提取英雄名字及數字
使用herolist.json拿到herolist,並提取出我們關心的內容
# 英雄的名字json
url = 'http://pvp.qq.com/web201605/js/herolist.json'
head = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'}
response = requests.get(url, headers=head)
hero_list = response.json()
# 提取英雄名字和數字
hero_name=list(map(lambda x:x['cname'], hero_list))
hero_number=list(map(lambda x:x['ename'], hero_list))
3.2 構造英雄面板的URL
首先準備好我們的BASE_URL,即英雄面板的固定字首。
h_l='http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'
接下來構造好英雄面板的URL,同時我們需要對每一個英雄的所有面板進行遍歷,如下:
# 逐一遍歷英雄
for i in hero_number:
# 逐一遍歷面板,此處假定一個英雄最多有15個面板
for sk_num in range(15):
hsl = h_l + str(i)+'/'+str(i)+'-bigskin-'+str(sk_num)+'.jpg'
hl = requests.get(hsl)
3.3 儲存圖片
最後我們就只需將獲取到的圖片儲存在本地即可。
# 將圖片儲存下來,並以"英雄名稱_面板序號"方式命名
with open(hero_name[num] + str(sk_num) + '.jpg', 'wb') as f:
f.write(hl.content)
4.效果展示
最終的爬取效果如下圖所示。
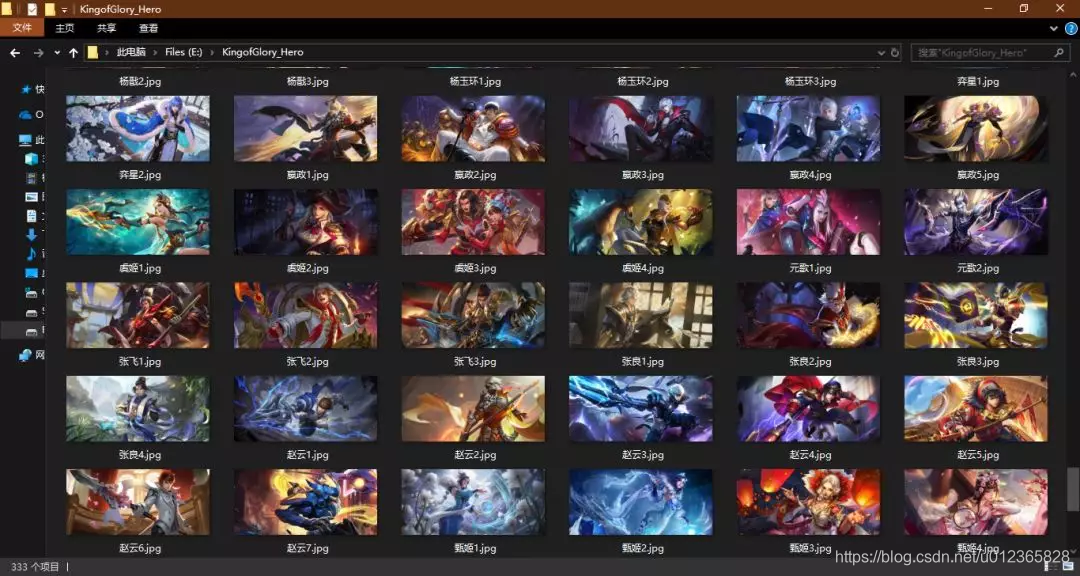
5.總結
短短几十行程式碼就可以把心愛英雄的精美面板儲存下來,趕快實操起來吧!
關注公眾號「Python專欄」,後臺回覆「zsxq04」,獲取本文全套原始碼!

相關推薦
用Python爬取"王者農藥"英雄面板
開發十年,就只剩下這套架構體系了! >>>
用Python爬取"王者農藥"英雄皮膚
mage 所有 mar for 分享圖片 其中 美的 同時 每一個 0.引言 作為一款現象級遊戲,王者榮耀,想必大家都玩過或聽過,遊戲裏中各式各樣的英雄,每款皮膚都非常精美,用做電腦壁紙再合適不過了。本篇就來教大家如何使用Python來爬取這些精美的英雄皮膚。 1.環境
我用Python爬取網易雲音樂上的Hip-hop歌單,分析rapper如何押韻
line gone 謠言 大致 -i 態度 大眾 其中 當前 緣起 《中國有嘻哈》這個節目在這個夏天吸引了無數的目光,也讓嘻哈走進了大眾的視野。作為我今年看的唯一一個綜藝節目,它對我的影響也蠻大。這個夏天,我基本都在杭州度過,在上下班的taxi上,我幾乎都在刷這個節目,最後
用python爬取微博數據並生成詞雲
font 意思 extra 很多 返回 json 自己 技術分享 pre 很早之前寫過一篇怎麽利用微博數據制作詞雲圖片出來,之前的寫得不完整,而且只能使用自己的數據,現在重新整理了一下,任何的微博數據都可以制作出來,放在今天應該比較應景。 一年一度的虐汪節,是繼續蹲在角落默
用python爬取i春秋的課程
out clas sse dir quest index 影響 png 繼續 看課中內容是用get請求進行爬取課程,自己實踐的時候發現已經被改成post請求了,下面開始 打開課程頁面 我用的火狐,然後就是F12,點擊網絡,可能會有很多包,但不影響,點擊刪除就行,然後點擊第二
我用 Python 爬取微信好友,最後發現一個大秘密
代碼 我們 同學 strong 分享 簽名 ast ron tps 前言 你身處的環境是什麽樣,你就會成為什麽樣的人。現在人們日常生活基本上離不開微信,但微信不單單是一個即時通訊軟件,微信更像是虛擬的現實世界。你所處的朋友圈是怎麽樣,慢慢你的思想也會變的怎麽樣。最近在學習
怎麽用Python爬取抖音小視頻? 資深程序員都這樣爬取的(附源碼)
aid option rip size with open url var mark open 簡介 抖音,是一款可以拍短視頻的音樂創意短視頻社交軟件,該軟件於2016年9月上線,是一個專註年輕人的15秒音樂短視頻社區。用戶可以通過這款軟件選擇歌曲,拍攝15秒的音樂短視頻
分手後,小夥怒用Python爬取上萬空姐照片,贏取校花選舉大賽!
代碼 美女圖片 pst caption alt .... 不出 ima bee 首先展示下Python爬取到的成果: 我做什麽都要爭第一,這次的校花投票選舉大賽也不例外,雖然我是個男的......但是我看到了前女友竟然已經有三百多票排到第三名了,我怎麽能眼睜
誰當年還沒看過幾本小說!我用Python爬取全站的的小說!
nec 打印 b數 技術分享 mon 結果 鏈接 ons ide 然後再將請求發送出去,定義變量response,用read()方法觀察,註意將符號解碼成utf-8的形式,省的亂碼: 打印一下看結果: 看到這麽
項目實戰!我用Python爬取了14年所有的福彩3D信息
下載器 rap 寫入excel url req 理論 ola text port 前兩天,在網上看到一個有意思的問題:×××靠譜麽?為什麽還有那麽多的人相信×××? 暫且不說,×××是否靠譜?×××也分人而異,江湖上騙術很多,有些甚至會誤以為×××的準確度可以很高,這些操盤
微信PK10平臺開發與用python爬取微信公眾號文章
網址 谷歌瀏覽器 pytho google http 開發 微信 安裝python rom 本文通過微信提供微信PK10平臺開發[q-21528-76294] 網址diguaym.com 的公眾號文章調用接口,實現爬取公眾號文章的功能。註意事項 1.需要安裝python s
用python爬取股票資料的一點小結
一、背景 網上對於爬取股票資料有相對完善的教程。不過大部分教程都是隻能夠爬取一段時間的股票資料,針對某一隻股票的歷史資料爬取,目前還沒有看到比較好的教程。下面對近期學的東西進行一點點小結。 二、股票資料爬取網站 網上更多推薦的是東方財富的股票資料,連結為:http://quote.eas
用python爬取美女圖片
import urllib.request import os for i in range(2000, 2400): if not os.path.exists(‘tupian/’ + str(i)): os.makedirs(‘tupian/’ + str(i)) for j in
用python爬取拉勾網招聘資訊並以CSV檔案儲存
爬取拉勾網招聘資訊 1、在網頁原始碼中搜索資訊,並沒有搜到,判斷網頁資訊使用Ajax來實現的 2、檢視網頁中所需的資料資訊,返回的是JSON資料; 3、條件為北京+資料分析師的公司一共40087家,而實際拉勾網展示的資料只有 15條/頁 * 30頁 = 450條,所以需要判斷
下午不知道吃什麼?用Python爬取美團外賣評論幫你選餐!
一、介紹 朋友暑假實踐需要美團外賣APP評論這一份資料,一開始我想,這不就抓取網頁原始碼再從中提取資料就可以了嗎,結果發現事實並非如此,情況和之前崔大講過的分析Ajax來抓取今日頭條街拍美圖類似,都是通過非同步載入的方式傳輸資料,不同的是這次的是通過JS傳輸,其他的基本思路基本一致,希望那些資料
用python爬取某個詞條的原始碼
簡單例子:在百度中輸入關鍵詞,並爬取該網頁的原始碼 #-*- coding:utf-8-*- import urllib #負責url編碼處理 import urllib2 url = "http://www.baidu.com/s" word = {"wd":"冼焯庭"}
用Python爬取手機APP
本文轉自:https://mp.weixin.qq.com/s?__biz=MzAxMjUyNDQ5OA==&mid=2653558162&idx=1&sn=73ae2ee5d2453773bceec078e39ca0ed&chksm=806e3b2fb71
用python爬取有道翻譯遇到反爬,3分鐘反反爬繞過其反爬
利用有道翻譯的介面,自制一個翻譯程式 檢視其翻譯介面,發現post請求需要傳很多引數,而且經過測驗,satl,sigh屬於動態生成的,遇到這種問題怎麼辦?當然有時間的情況下,可以去研究這些引數在哪個響應中返回,或者怎麼構造,但是一般在工作中我們可能需求來了,不
用Python爬取微博資料生成詞雲圖片
很早之前寫過一篇怎麼利用微博資料製作詞雲圖片出來,之前的寫得不完整,而且只能使用自己的資料,現在重新整理了一下,任何的微博資料都可以製作出來,放在今天應該比較應景。 一年一度的虐汪節,是繼續蹲在角落默默吃狗糧還是主動出擊告別單身汪加入散狗糧的行列就看你啦,七夕送什麼才有心意,程式猿可以試試用
教你用python爬取喜馬拉雅FM音訊,乾貨分享~
前前言 喜馬拉雅已經更換標籤,我重新更新了下程式碼,文章暫時未改,因為思路還是如此,需要的可以掃一下文末公眾號二維碼(本人會在上面發表爬蟲以及java的文章還有送書等資源福利哦),也可以直接搜尋公眾號“ 猿獅的單身日常”,好了廣告結束... 前言 之前寫過爬取圖片的一篇文章,這回來看看如