
用Python爬取"王者農藥"英雄皮膚

0.引言
作為一款現象級遊戲,王者榮耀,想必大家都玩過或聽過,遊戲裏中各式各樣的英雄,每款皮膚都非常精美,用做電腦壁紙再合適不過了。本篇就來教大家如何使用Python來爬取這些精美的英雄皮膚。
1.環境
操作系統:Windows / Linux
Python版本:3.7.2
2.需求分析
我們打開《王者榮耀》官網,找定位到英雄列表的頁面
可直接點此鏈接:
https://pvp.qq.com/web201605/herolist.shtml 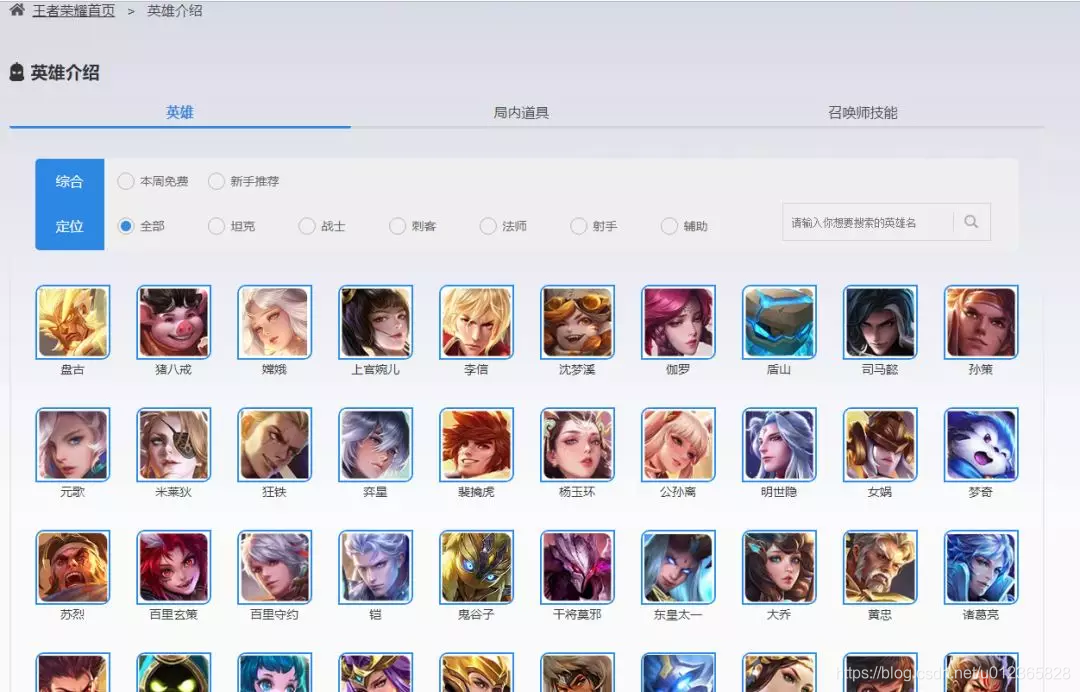
在這個網頁中包含了所有的英雄,頭像及英雄名稱。點擊其中一個英雄的頭像,如“嫦娥”,進去後如下圖:
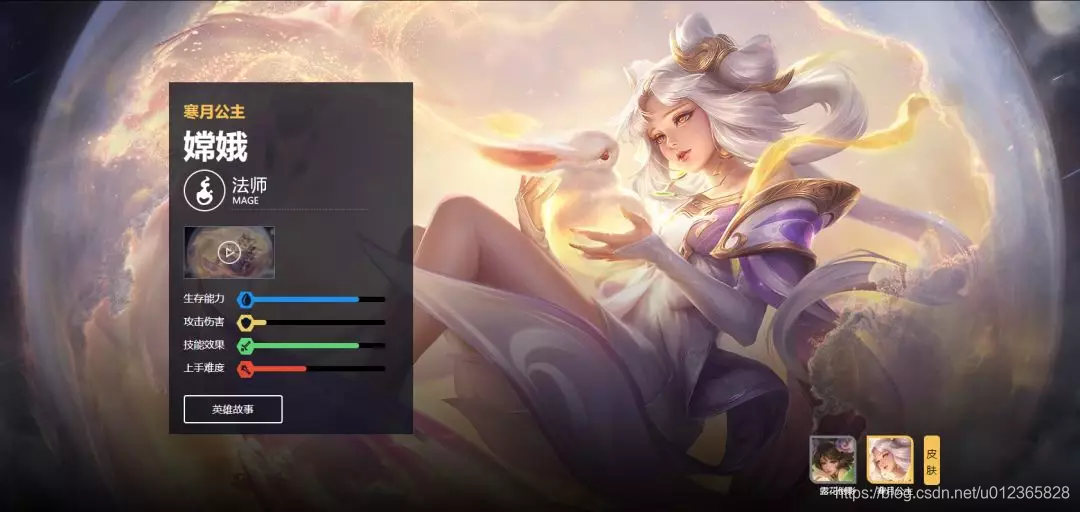
我們記下此時的網址
https://pvp.qq.com/web201605/herodetail/515.shtml
再後退到英雄列表頁面,點“甄姬”進去查看:
https://pvp.qq.com/web201605/herodetail/127.shtml
可以看到這些網址幾乎是固定不變的,變化的只是515、127這些數字,這些其實就是代表的英雄數字編號。
那麽第一個關鍵點就來了,怎麽找出各個英雄所對應的數字編號呢?
我們回到最初的英雄列表頁面,打開瀏覽器的開發者工具<F12>,刷新頁面、仔細觀察,你會找到一個herolist.json的文件,如圖所示:
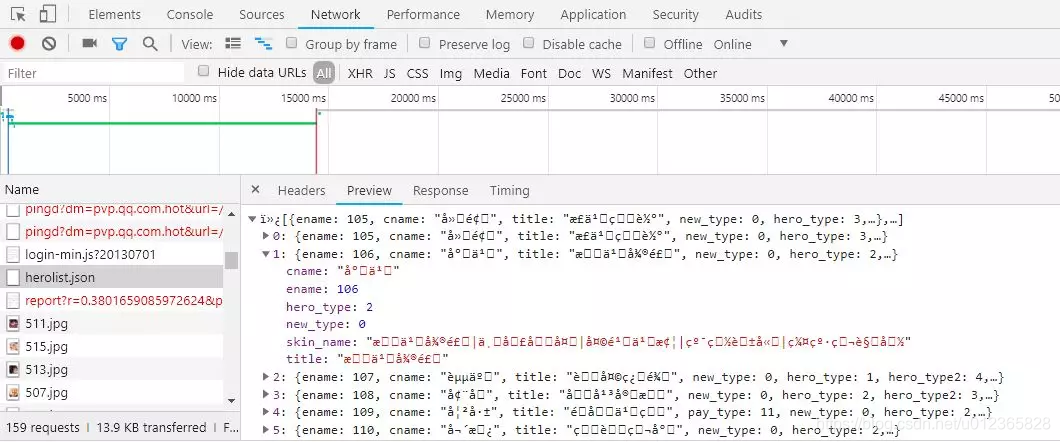
這裏記錄了各個英雄的信息,其中就包含了每個英雄對應的數字編號了,請忽略這裏截圖中的亂碼顯示。我們切到herolist.json中的Headers,就可以拿到該請求的URL地址,進而就可以把英雄及其對應的數字,編號都提取出來了。
有了英雄編號的對應關系,再找尋下英雄皮膚的鏈接規律。
現在重新進入一個英雄的網址,打開瀏覽器的開發者工具,刷新頁面,在Network下刷新並找到英雄的皮膚圖片,如圖所示:
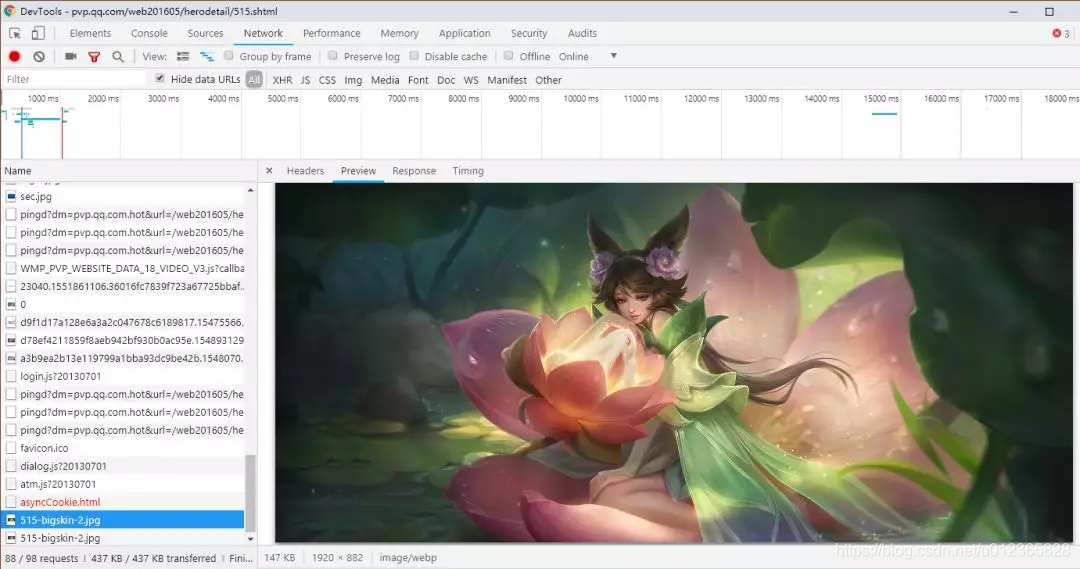
在Headers中查看該圖片的網址,查看即Request URL處的鏈接:
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/515/515-bigskin-1.jpg
找尋一個看看
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/529/529-bigskin-1.jpg
繼續尋一個看看
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/127/127-bigskin-4.jpg
仔細分析如上三個鏈接,我們可以把英雄皮膚的URL拆分開來看。它是由一個固定前綴(我們可以記為base_url),再加上英雄數字編號、"bigskin"、皮膚編號、".jpg"組合而成,如下:
base_url / hero_num / hero_num - bigskin - heroskin_num .jpg
拿到了各個英雄皮膚的URL地址後,我們就可以進行圖片的下載並保存在本地了。
3.代碼演示
首先導入我們所用到的模塊
import requests
import os註:requests是非內置模塊,若環境中沒有,需自行安裝:
pip install requests3.1 提取英雄名字及數字
使用herolist.json拿到herolist,並提取出我們關心的內容
# 英雄的名字json
url = ‘http://pvp.qq.com/web201605/js/herolist.json‘
head = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36‘}
response = requests.get(url, headers=head)
hero_list = response.json()
# 提取英雄名字和數字
hero_name=list(map(lambda x:x[‘cname‘], hero_list))
hero_number=list(map(lambda x:x[‘ename‘], hero_list))3.2 構造英雄皮膚的URL
首先準備好我們的BASE_URL,即英雄皮膚的固定前綴。
h_l=‘http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/‘接下來構造好英雄皮膚的URL,同時我們需要對每一個英雄的所有皮膚進行遍歷,如下:
# 逐一遍歷英雄
for i in hero_number:
# 逐一遍歷皮膚,此處假定一個英雄最多有15個皮膚
for sk_num in range(15):
hsl = h_l + str(i)+‘/‘+str(i)+‘-bigskin-‘+str(sk_num)+‘.jpg‘
hl = requests.get(hsl)3.3 存儲圖片
最後我們就只需將獲取到的圖片保存在本地即可。
# 將圖片保存下來,並以"英雄名稱_皮膚序號"方式命名
with open(hero_name[num] + str(sk_num) + ‘.jpg‘, ‘wb‘) as f:
f.write(hl.content)4.效果展示
最終的爬取效果如下圖所示。
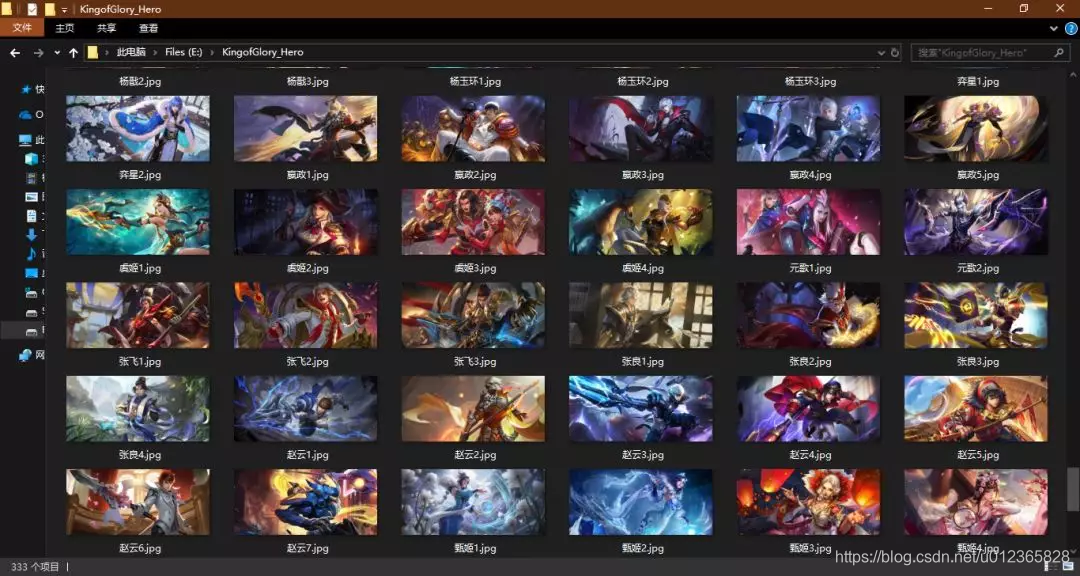
5.總結
短短幾十行代碼就可以把心愛英雄的精美皮膚保存下來,趕快實操起來吧!
關註公眾號「Python專欄」,後臺回復「zsxq04」,獲取本文全套源碼!

用Python爬取"王者農藥"英雄皮膚