
spark的安裝配置
一、系統安裝:centos7
1.新建三臺虛擬機器
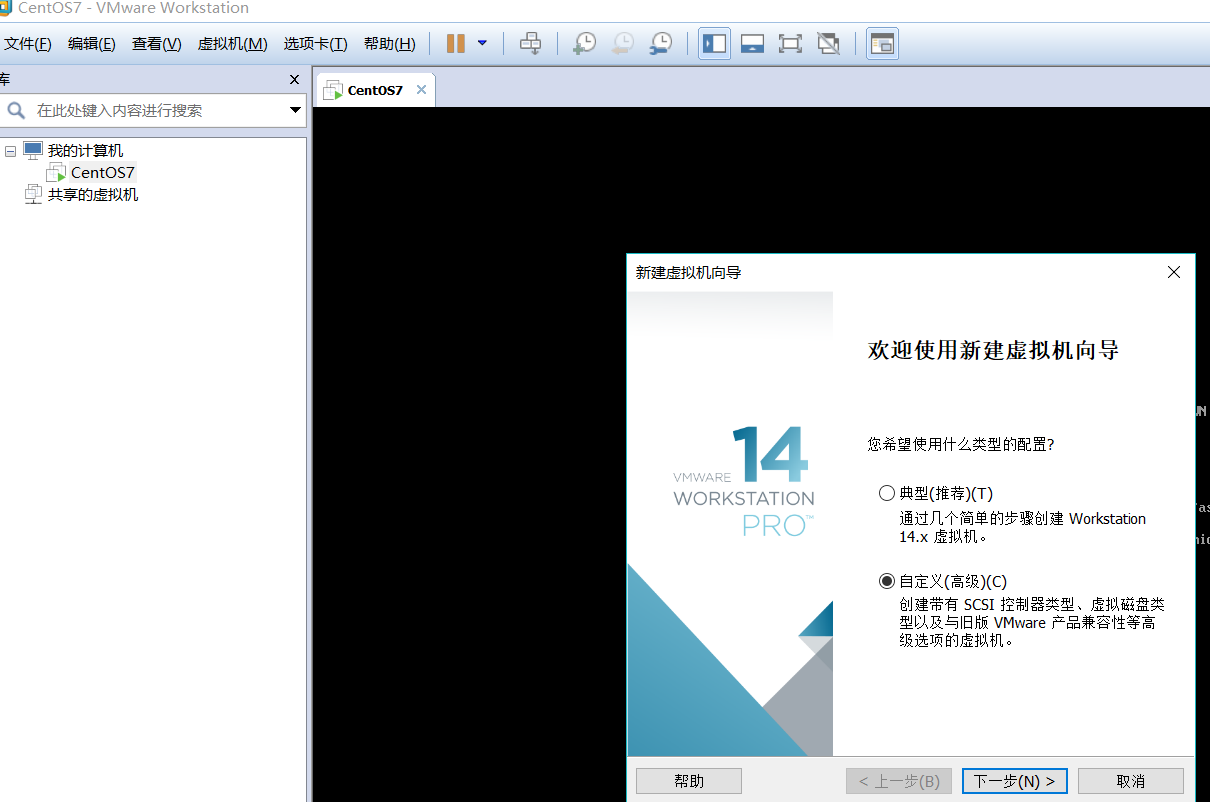
2.新建完成後進入虛擬機器安裝系統,選擇最小安裝
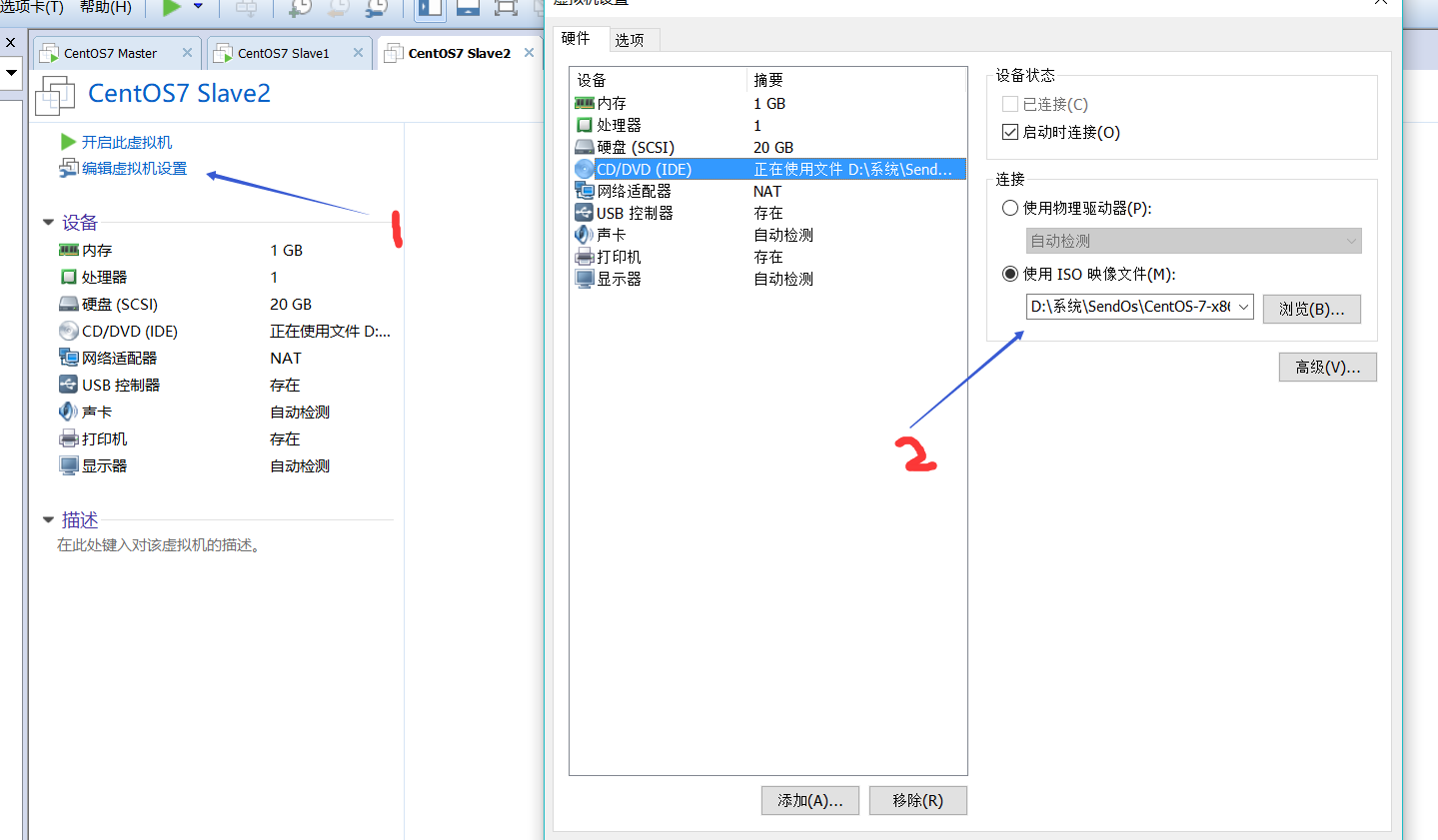
3.配置ip
cd /etc/sysconfig/network-scripts/
vi ifcfg-ens33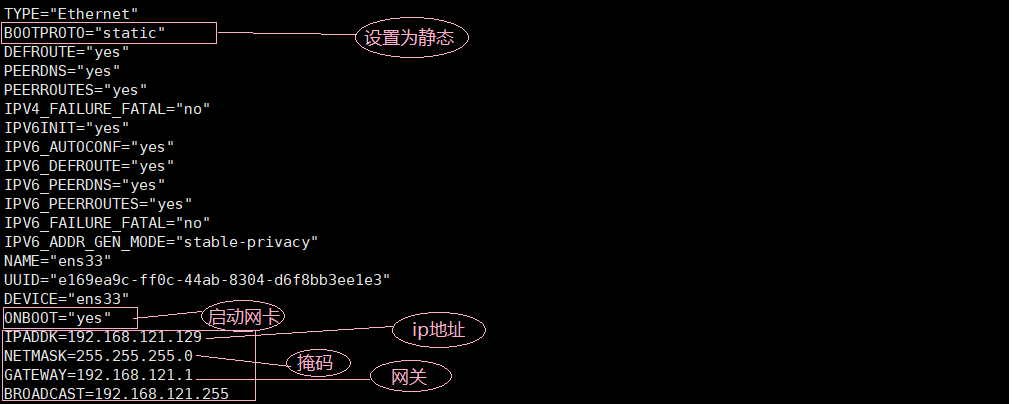
4.設定hostname(伺服器名稱)
hostname 檢視伺服器名稱
hostnamectl set-hostname master 設定伺服器名稱為master(主)/slave1(從)/slave2修改vi /etc/hosts檔案 使ip和名稱一一對應

測試ping slave1能否ping通
5.ssh
①檢測ssh是否已安裝
rpm -qa|grep openssh②安裝ssh
yum install ssh 安裝SSH協議
service sshd restart 啟動服務③配置ssh免密登入
1)SSH無密碼原理
Master(NameNode | JobTracker)作為客戶端,要實現無密碼公鑰認證,連線到伺服器Salve(DataNode | Tasktracker)上時,需要在Master上生成一個金鑰對,包括一個公鑰和一個私鑰,而後將公鑰複製到所有的Slave上。當Master通過SSH連線Salve時,Salve就會生成一個隨機數並用Master的公鑰對隨機數進行加密,併發送給Master。Master收到加密數之後再用私鑰解密,並將解密數回傳給Slave,Slave確認解密數無誤之後就允許Master進行連線了。這就是一個公鑰認證過程,其間不需要使用者手工輸入密碼。重要過程是將客戶端Master複製到Slave上。
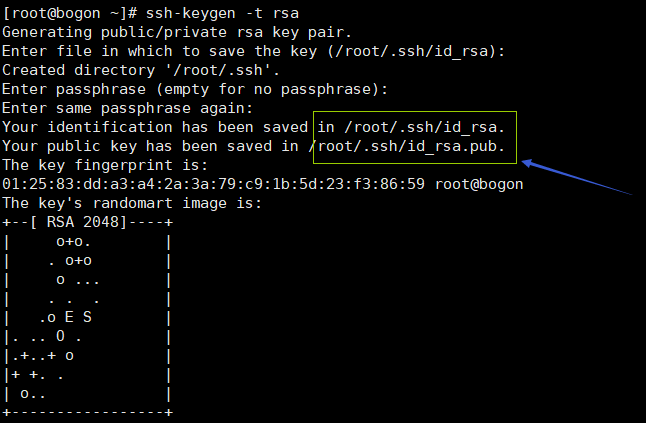
2)生成祕鑰
cd ~
ssh-keygen -t rsa
輸入命令後一直按回車,不要輸入,(cd ~/.ssh)目錄下可以生成一個公鑰一個私鑰
3)在Master節點上把id_rsa.pub追加到授權的key裡面去
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 把公鑰追加至授權key中 chmod 600 ~/.ssh/authorized_keys 修改authorized_keys許可權 service sshd restart 重啟ssh授權 ssh localhost 在master本機測試是否可以免密登入
4)Master與其他節點無密登入
從master中把authorized_keys分發到各個結點上格式為(scp ~/.ssh/authorized_keys 遠端使用者名稱@遠端伺服器IP:~/)
scp ~/.ssh/authorized_keys slave1:~/.ssh
scp ~/.ssh/authorized_keys slave2:~/.ssh 測試ssh slave1能否免密登入
二、必備軟體安裝
1.安裝java
1)進入opt目錄下載 (如果wget命令未找到就 yum -y install wget)
cd /opt
wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/8u141-b15/336fa29ff2bb4ef291e347e091f7f4a7/jdk-8u141-linux-x64.tar.gz"2)解壓
tar -zxvf jdk-8u141-linux-x64.tar.gz
3)配環境變數(https://www.cnblogs.com/ilovexiao/p/3946467.html)
cat /etc/profile 進入配置目錄
在末尾加入java環境變數
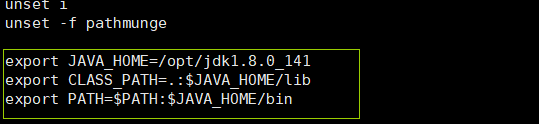
source /etc/profile 使配置馬上生效測試
java
javac
java -version2.安裝hadoop
①進入opt目錄下載
wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz" ②解壓
tar -zxvf hadoop-2.7.7.tar.gz
③/opt/hadoop-2.7.7/etc/hadoop/目錄下配置檔案修改
1)JAVA_HOME
進入到cd /opt/hadoop-2.7.7/etc/hadoop/路徑下 hadoop-env.sh和yarn-env.sh 末尾新增JAVA_HOME
cd /opt/hadoop-2.7.7/etc/hadoop/
vi hadoop-env.sh
vi yarn-env.sh
![]()
2)修改core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml,slaves 配置檔案
core-site.xml
vi core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.7/tmp</value> <--!沒有tmp資料夾需要新建-->
</property>
</configuration> hdfs-site.xml
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>設定副本數</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-2.7.7/dfs/name</value>
<description>設定存放NameNode的檔案路徑</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-2.7.7/dfs/data</value>
<description>設定存放DataNode的檔案路徑</description>
</property>
</configuration>mapred-site.xml(如果目錄下沒有mapred-site.xml,只有mapred.xml.template,我們要複製該檔案,並命名為mapred.xml,該檔案用於指定MapReduce使用的框架)
cp mapred-site.xml.template mapred-site.xml (沒有mapred-site.xml才需要執行)vi mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration> yarn-site.xml
vi yarn-site.xml<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
slaves 檔案 (清空後輸入兩臺從主機名稱)
vi slaves slave1
slave2
④分發hadoop到從節點
scp -r /opt/hadoop-2.7.7 slave1:/opt/hadoop-2.7.7
scp -r /opt/hadoop-2.7.7 slave2:/opt/hadoop-2.7.7⑤啟動hadoop
1)在Master伺服器啟動hadoop,從節點會自動啟動,進入/opt/hadoop-2.7.0目錄
2)初始化,輸入命令,bin/hdfs namenode -format
3)全部啟動sbin/start-all.sh,也可以分開sbin/start-dfs.sh、sbin/start-yarn.sh
4)終止伺服器:sbin/stop-all.sh
5)輸入命令jps,可以看到相關資訊
⑥瀏覽器訪問
1)關閉防火牆systemctl stop firewalld.service
2)瀏覽器開啟http://192.168.121.129:8088/
3)瀏覽器開啟http://192.168.121:129:50070/
相關推薦
centOS7下Spark安裝配置
節點 bin scala www. emp 讓其 slave park exec 環境說明: 操作系統: centos7 64位 3臺 centos7-1 192.168.190.130 master centos7-
Spark 安裝配置簡單測試
簡介 Spark是UC Berkeley AMP lab (加州大學伯克利分校的AMP實驗室)所開源的類Hadoop MapReduce的通用並行框架,Spark,擁有Hadoop MapReduce所具有的優點;但不同於MapReduce的是Job中間輸出結
spark安裝配置和程式碼框架(轉)
之前查閱原始碼啊,效能測試啊調優啊。。基本告一段落,專案也接近尾聲,那麼整理下spark所有配置引數與優化策略,方便以後開發與配置: Spark安裝配置與程式碼框架 spark-default.conf 配置 spark.executor.instance
Hive on Spark安裝配置詳解(都是坑啊)
簡介 本文主要記錄如何安裝配置Hive on Spark,在執行以下步驟之前,請先確保已經安裝Hadoop叢集,Hive,MySQL,JDK,Scala,具體安裝步驟不再贅述。 背景 Hive預設使用MapReduce作為執行引擎,即Hive on mr。實際上,H
大數據筆記(二十七)——Spark Core簡介及安裝配置
sin cli sca follow com clu 同時 graphx 信息 1、Spark Core: 類似MapReduce 核心:RDD 2、Spark SQL: 類似Hive,支持SQL 3、Spark Streaming:類似
Spark Standalone Mode安裝配置
一、Spark下載安裝 官網地址:http://spark.apache.org/downloads.html [email protected]:/usr/local# tar -zxvf spark-1.6.0-bin-hadoop2.6.tgz [email
Spark安裝以及配置
2>在/usr/local/src/中解壓spark-2.0.2-bin-hadoop2.6.tgz 3>在spark根目錄中,進入/conf目錄下,建立slaves和 spark-env.sh檔案,我這裡配的是叢集的方式,所以在slaves中新增 sla
大資料基礎(五)從零開始安裝配置Hadoop 2.7.2+Spark 2.0.0到Ubuntu 16.04
raw to spark 0 install ubuntu 14.04.01 desktop x64 1 system基礎配置 《以下都是root模式》 1.3 root password sudo passwd root 1.5 root登入選項 a.在terminal下
python中安裝配置pyspark庫教程需要配合spark+hadoop使用
單獨安裝pyspark庫在單機上是沒法執行的,需要有相應的分散式軟體,這裡可以是spark+hadoop,配置安裝教程連結:spark2.3在window10當中來搭建python3的使用環境pyspark配置pyspark庫之前在安裝spark的時候,提到過pyspark庫
CDH安裝配置zeppelin-0.7.3以及配置spark查詢hive表
1.下載zeppelin http://zeppelin.apache.org/download.html 我下載的是796MB的那個已經編譯好的,如果需要自己按照環境編譯也可以,但是要很長時間編譯,這個版本包含了很多外掛,我雖然是CDH環境但是這個也可以使用。 2.修改
docker中spark+scala安裝配置
一、scala安裝首先下載scala壓縮包 wget https://downloads.lightbend.com/scala/2.11.7/scala-2.11.7.tgz 解壓 tar -zxvf scala-2.11.7.tgz 移動目錄 mv scala-2.11
centos6 5安裝配置spark
安裝java
Linux中安裝配置spark叢集
一. Spark簡介 Spark是一個通用的平行計算框架,由UCBerkeley的AMP實驗室開發。Spark基於map reduce 演算法模式實現的分散式計算,擁有Hadoop MapReduce所具有的優點;但不同於Hadoop MapReduce的是Job中間輸出和結果可以儲存在記憶體中,從而不
Spark 1.6.2 單機版安裝配置
本文將介紹Apache Spark 1.6.2在單機的部署,與在叢集中部署的步驟基本一致,只是少了一些master和slave檔案的配置。直接安裝scala與Spark就可以在單機使用,但如果用到hdfs系統的話hadoop和jdk也要配置,建議全部安裝配置好。
Centos下Spark單機版(python)安裝配置
如果上面都成功了,那說明我們就基本安裝成功了,可以用scala或者python來開發相關程式了。但是如果我們希望能夠在一個很清新的IDE中開發程式怎麼辦?那麼這裡強烈推薦一款互動式的開發工具-jupyter notebook。接下來我們就來配置該工具,以保證能連線上sprak。
Spark 1.6.1 單機安裝配置
本文將介紹Apache Spark 1.6.1在單機的部署,與在叢集中部署的步驟基本一致,只是少了一些master和slave檔案的配置。http://blog.csdn.net/u011513853/article/details/52865076 Spark在Wi
ubuntu單機下安裝配置spark
一.安裝JDK 二.安裝SCALA 1.解壓scala-2.12.0.tgz到任意檔案目錄。 2.修改 /etc/profile配置檔案,加入以下程式碼 sudo echo export SCALA_HOME="~/hadoop/scala-2.12.0" >&g
spark python安裝配置 (初學)
需要:jdk10.0、spark2.3.1、Hadoop2.7.7(與spark對應的版本) 1、首先安裝pyspark包: pip install py4j pip install pyspark 2、安裝JDK,並配置環境,我的安裝位置為D
spark的安裝配置
一、系統安裝:centos7 1.新建三臺虛擬機器 2.新建完成後進入虛擬機器安裝系統,選擇最小安
Linux - vim安裝 配置與使用
格式 only ctx net height border term mona 方便 一 Vim 簡單介紹 曾經一直用vi,近期開始使用 vim,以下將兩者做一下比較。 vi和vim都是多模式編輯器,不同的是vim 是vi的升級版本號,它不僅兼容vi的全部指令,並且