
螞蟻金服開源的機器學習工具 SQLFlow,有何特別之處?

近日,螞蟻金服副 CTO 胡喜正式宣佈開源機器學習工具 SQLFlow,他在大會演講中表示:“未來三年,AI 能力會成為每一位技術人員的基本能力。我們希望通過開源 SQLFlow,降低人工智慧應用的技術門檻,讓技術人員呼叫 AI 像 SQL 一樣簡單。” SQLFlow 能夠抽象出端到端從資料到模型的研發過程,配合底層的引擎及自動優化,具備基礎 SQL 知識的技術人員即可完成大部分的機器學習模型訓練及預測任務。
SQLFlow 由何而來?螞蟻金服對於 SQLFlow 未來還有哪些規劃?一起來深入瞭解。
SQLFlow 的目標是將 SQL 引擎和 AI 引擎連線起來,讓使用者僅需幾行 SQL 程式碼就能描述整個應用或者產品背後的資料流和 AI 構造。其中所涉及的 SQL 引擎包括 MySQL、Oracle、Hive、SparkSQL、Flink 等支援用 SQL 或其某個變種語言描述資料,以及描述對資料的操作的系統。而這裡所指的 AI 引擎包括 TensorFlow、PyTorch 等深度學習系統,也包括 XGBoost、LibLinear、LibSVM 等傳統機器學習系統。
SQLFlow 研發團隊認為,在 SQLFlow 和 AI 引擎之間存在一個很大的空隙——如何把資料變成 AI 模型需要的輸入。谷歌開源的 TensorFlow 專案開了一個好頭,TFX Data Transform 和 feature column API 都是意圖填補這個空缺的專案。但是這個空缺很大,是各種 SQL 引擎和各種 AI 引擎的笛卡爾積,遠不是 TensorFlow 的這兩個子專案就足以填補的,需要一個開源社群才行。要填補好這個空缺,需要先讓使用者意識到其重要性,這也是螞蟻金服開源 SQLFlow 的意圖之一。
SQLFlow 位於 AI 軟體系統生態的最頂端,最接近使用者,它也位於資料和資料流軟體生態之上。
其實,將 SQL 和 AI 連線起來這個想法並非 SQLFlow 原創。谷歌於 2018 年年中釋出的 BigQueryML 同樣旨在“讓資料科學家和分析師只用 SQL 語言就可以實現流行的機器學習功能並執行預測分析”。除了 Google 的 BigQueryML,微軟基於 SQL Server 的 AI 擴充套件,以及 Teradata 的 SQL for DL 同樣旨在連線 SQL 和 AI,讓人工智慧的應用變得像 SQL 一樣簡單。而 SQLFlow 與上述各個系統最根本的差異在於:SQLFlow 是開源的,以上系統都不是。
開發 SQLFlow 的初衷
螞蟻金服和很多網際網路公司一樣,不同產品背後有很多功能都依賴於 AI,比如使用者信用的評估就是一套預測模型。到目前為止,每一個這樣的功能的實現,都依賴一個工程師團隊開發多個子系統——讀取資料庫或者線上日誌流、這兩類資料的 join、各種資料篩選、資料到模型輸入(常說的 features)的對映、訓練模型、用訓練好的模型來做預測。整個過程下來耗時往往以月計,如果加班加點放棄寫 unit test 程式碼,可能縮短到以週記。
以上問題正是 SQLFlow 系統希望替工程師們解決的問題。螞蟻金服擁有數千資料分析師,他們日常工作用的就是 SQL 語言。雖然資料分析師在網際網路行業往往不像用 Python、Java、C++ 的工程師那樣醒目,但是在很多有面向商業夥伴的業務的公司裡,比如 LinkedIn,他們的貢獻和人數都能與工程師相匹敵。SQLFlow 最早的初衷,就是希望解決分析師既要操作資料又要使用 AI、往往需要在兩個甚至更多的系統之間切換、工作效率低的窘境。
SQLFlow 旨在大幅提升效率,讓上述功能實現所花費的時間進一步縮短到能以日計,甚至以小時計的程度。
要達到這樣的效率,必須有一種效率極高的描述工作意圖的方式。SQL 是一種典型的描述意圖,而不描述過程的程式語言。使用者可以說我要 join 兩個表,但是不需要寫迴圈和構造 hash map 來描述如何 join 兩個表。這個特性使得 SQL 能極大地提升開發效率,這正是 SQLFlow 選擇擴充套件 SQL 語法支援 AI 這條思路的原因。
不過,高效率的背後是更大的工程技術挑戰。SQLFlow 需要做到能根據使用者的意圖,自動生成達到意圖的 Python、C++、Go 語言的程式。
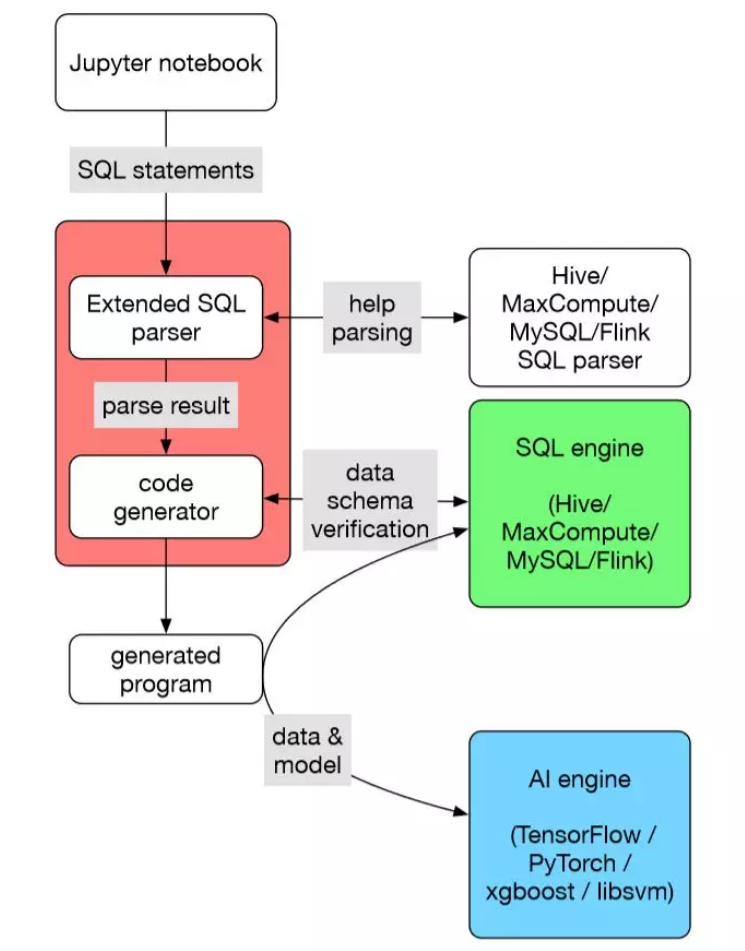
SQLFlow 的架構設計
設計目標
在連線 SQL 和 AI 應用這一方向上,業內已有相關工作。開發者可以使用像 DOT_PRODUCT 這樣的運算子在 SQL 中編寫簡單的機器學習預測(或評分)演算法。但是,從訓練程式到 SQL 語句需要進行大量的模型引數複製貼上的工作。目前在一些商業軟體中,已經有部分專有 SQL 引擎提供了支援機器學習功能的擴充套件。
- Microsoft SQL Server:Microsoft SQL Server 支援機器學習服務,可以將 R 或 Python 編寫的機器學習程式作為外部指令碼執行。
- Teradata SQL for DL:Teradata 也提供了 RESTful 服務,可以通過擴充套件的 SQL SELECT 語法呼叫。
- Google BigQuery:Google BigQuery 通過引入 CREATE MODEL 語句讓用 SQL 實現機器學習成為可能。
但上述已有的解決方案都無法解決螞蟻金服團隊的痛點,他們的目標是打造一個完全可擴充套件的解決方案。
- 這一解決方案應與許多 SQL 引擎都相容,而不是隻能相容特定版本或型別的 SQL 引擎。
- 它應該支援複雜的機器學習模型,包括用於深度學習的 TensorFlow 和用於樹模型的 XGBoost。
- 能夠靈活地配置和執行前沿機器學習演算法,包括指定特徵交叉,無需在 SQL 語句中嵌入 Python 或 R 程式碼,以及完全整合超引數估計等。
應對上述挑戰的關鍵在於打造一套 SQL 擴充套件語法。研發團隊首先從僅支援 MySQL 和 TensorFlow 的原型開發開始,後續計劃支援更多 SQL 引擎和機器學習工具包。
從 SQL 到機器學習
SQLFlow 可以看作一個翻譯器,它把擴充套件語法的 SQL 程式翻譯成一個被稱為 submitter 的程式,然後執行。 SQLFlow 提供一個抽象層,把各種 SQL 引擎抽象成一樣的。SQLFlow 還提供一個可擴充套件的機制,使得大家可以插入各種翻譯機制,得到基於不同 AI 引擎的 submitter 程式。
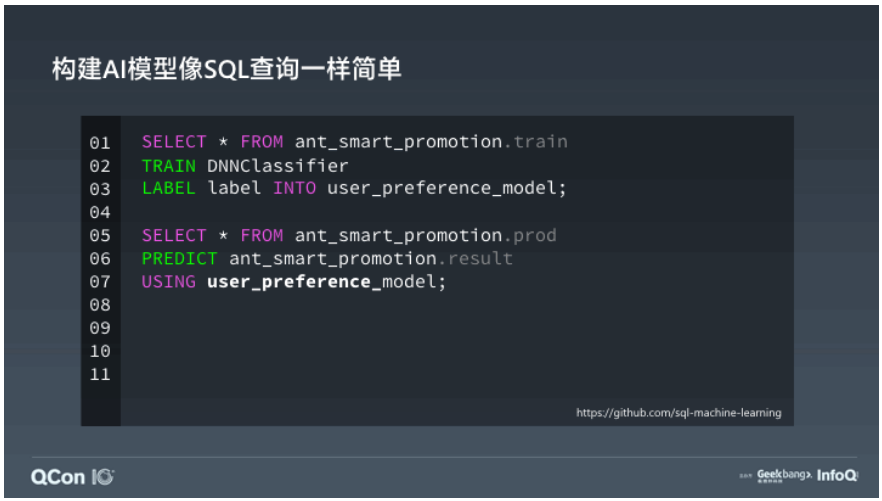
SQLFlow 對 SQL 語法的擴充套件意圖很簡單:在 SELECT 語句後面,加上一個擴充套件語法的 TRAIN 從句,即可實現 AI 模型的訓練。或者加上一個 PREDICT 從句即可實現用現有模型做預測。這樣的設計大大簡化了資料分析師的學習路徑。
此外,SQLFlow 也提供一些基本功能,可以供各種 submitter 翻譯外掛使用,用來根據資料的特點,推導如何自動地把資料轉換成 features。這樣使用者就不需要在 TRAIN 從句裡描述這個轉換。
以上這些設計意圖在 SQLFlow 的開原始碼中都有體現。當然,SQLFlow 開發時間還比較短,仍然存在很多做的不夠細緻的地方。螞蟻金服將其開源的另一個目的,就是希望能夠和各個 SQL 引擎團隊和各個 AI 團隊一起打造這座橫跨資料和 AI 的橋樑。
基於 Go 語言開發
SQLFlow 基於 Go 語言開發,Go 語言的眾多優點使其成為了 SQLFlow 研發團隊的首選。除了 Go 社群討論較多的優勢以外,以下兩點被重點提及:
首先 Go 容易學習卻擁有極高的開發效率。它的 keyword 數量比 C 語言還要少,但是描述能力(平均每一行程式碼能表示的意圖)接近 Python。
另一個原因是 Go 的程式碼庫易於長期維護。一項工作用 Python 或者 C++ 來寫,會有很多種寫法,都能跑。用 Go 來寫,往往只有一種寫法。這就使得 Go 程式設計師社群裡不會有很多風格共存,也就不需要 Google C++ style 這樣的程式碼規範來限制不許用 C++ 的哪些特性,也不會像 Python 程式碼開發時那樣,各種程式碼風格之間形成鄙視鏈,在 code review 過程裡帶來不必要的爭執。
與阿里 PAI 的關係
SQLFlow 研發團隊認為,AI 和機器學習的生態可以分為很多層。其中 TensorFlow、PyTorch、XGBoost、LibLinear 這些系統位於最底層,距離終端使用者最遠,只有很硬核的使用者才能熟練掌握和使用,而這部分使用者在網際網路從業者裡佔的比例較小。
SQLFlow 和阿里推出的機器學習平臺 PAI 均位於生態的最頂層,需要呼叫下層的技術棧,二者均直接面對終端使用者,而這些使用者中可能有大量並不具備 AI 背景知識。
PAI 系統通過先進的圖形使用者介面來解決 AI 難理解、難應用的挑戰——比如託拽基礎 AI 元件來構造複雜的模型和資料流。
SQLFlow 則通過寫 SQL 程式的方式來實現這一目標。有能寫下來的程式,就容易存檔,容易 Code Review,容易分享知識,容易集思廣益,容易高效率迭代。此外,敲鍵盤寫程式比動滑鼠拖拽快。
SQLFlow 優化工作
SQLFlow 目前依賴 TensorFlow 等底層引擎來實現訓練和預測。為了提升 SQLFlow 在機器學習模型的訓練和預測效能,螞蟻金服有一個團隊專門做硬體加速 AI 計算的工作,最近已經有了一些令人驚喜的成績,希望在不久的將來可以和大家分享細節。另外還有一個兄弟專案專門維護螞蟻金服對 TensorFlow 的功能擴充套件,也和效能相關。
SQLFlow 專案負責人表示,訓練和預測只是整個 AI 產品功能長長的鏈條中的兩個環節。SQLFlow 這個專案是為解決整個鏈條構建而打造的,其中有很多環節的耗時比 AI 的訓練和預測多得多,因此還有極大的效能提升的空間。比如很多 SQL 引擎並不支援讓一個分散式 AI 程式併發讀取其中的資料,如果 SQLFlow 能夠解決類似的吞吐量限制,AI 的總體效率能提高數倍甚至數十倍。
在對機器學習演算法的支援方面,SQLFlow 設計的初衷就是要複用各個 AI 引擎各自的模型庫。目前 SQLFlow 支援 TensorFlow Estimator 規範的模型。比如 SQLFlow 擴充套件語法中 SELECT ... TRAIN DNNClassifier ... 這個寫法,DNNClassifier 就是一個 Python class 的名,在這個例子中是一個派生自 tf.Estimator 的 class。SQLFlow 研發團隊也正在做支援 Keras 模型的相關工作,團隊也在考慮規範 XGBoost 模型的程式寫作,使其可以被 SQLFlow 使用者方便地呼叫。
這些工作背後的思路是希望網際網路行業常見的三類技術角色:分析師、研究員、工程師的分工更清晰,從而能更專注發揮各自特長:分析師因為了解資料所以寫 SQL,呼叫 DNNClassifier 這樣由研究員用 Python 寫的模型;研究員不用操心分散式計算和模型到底是如何被分散式訓練(或預測)的,這部分工作留給工程師。與此同時,SQLFlow 作為一種粘合劑,把這三類角色的產出有機結合,以便更加高效地構造產品。
SQLFlow 未來規劃
SQLFlow 當前已經能夠帶來研發效率的提升,但尚不完美,目前 SQLFlow 還存在以下問題有待解決:
第一個問題是 parsing。SQLFlow 目前已經對接 MySQL,正在對接 Hive 和 阿里雲上的 MaxCompute,將來還希望能對接更多公司正在使用的 SQL 引擎。這些引擎的 SQL 語法大都符合 SQL 標準,但是總有一些自己獨特的擴充套件,而使用者往往不知不覺地用到了這些特點。SQLFlow 希望使用者能在已有的 SELECT 語句之後,通過簡單地新增一個 TRAIN 或者 PREDICT 從句,即可實現資料和 AI 的互聯,這就要求 SQLFlow 支援各個 SQL 引擎獨到的語法特點。
第二個問題是資料到 feature 的對映的自動化。目前 SQLFlow 是根據 SQL 欄位的型別(INT、FLOAT、TEXT、BLOB)來自動化對映到 feature column API,比如 numeric_column 或者 categorical_column_with_vocabulary 或者 bucketized_column。其實很多 TEXT 欄位裡儲存的資訊很複雜,可能是一個 yaml 或者 json,所以需要掃描(至少一部分)資料,才能精準地判斷這個對映。類似的,一個 BLOB 欄位裡可能是 protobuf message 的 encoding,encode 的是一個 TensorFlow 的 tensor。
第三個問題是 AI 引擎。 TensorFlow、PyTorch、XGBoost、LibLinear 這些 AI 引擎的分散式計算能力都有一些問題。TensorFlow 原生支援分散式訓練,但不支援容錯,一個程序掛了,整個作業就掛了。雖然這還可以通過 checkpointing 解決,但是不容錯就不能彈性排程,不能彈性排程就意味著叢集利用率可能極差。比如一個有 N 個 GPU 的叢集上在執行一個作業,使用了一個 GPU;此時一個新提交的作業要求使用 N 個 GPU,因為空閒 GPU 個數是 N-1,所以這個新的作業不能開始執行,而是得一直等數小時甚至數天,直到前一個作業結束、釋放那個被佔用的 GPU。這麼長時間裡,叢集利用率< 1/N。關於這個問題的解決方案,百度 PaddleEDL和阿里集團的 XDL做了一些很有益的探索。希望業界把過分集中於 AI 執行時間優化的眼光,分一部分到減少等待時間上。
接下來螞蟻金服將致力於推動 SQLFlow 在螞蟻金服業務和螞蟻金服以外的公司的使用,讓 SQLFlow 專案成為整個社群的共同工作,從中收穫更多的反饋,引導專案的發展方向,也幫助明確各項工作的優先順序。
令 SQLFlow 團隊感到欣喜的是,雖然 SQLFlow 剛開源,但目前已經有來自美國和中國幾大網際網路公司的貢獻者參與到社群工作中來。由於每個公司使用的 SQL 引擎不同,如果 SQLFlow 核心團隊能提供比較好的資料層抽象,那麼來自不同公司的貢獻者就能比較容易地把 SQLFlow 適配到自己公司的引擎上。類似的,支援多種 AI 引擎的方式也是如此。
此外,SQLFlow 團隊希望各個公司的研究員們能夠參與到開源專案中來,分享各自的模型,未來 SQLFlow 會支援各種形式的模型,以便分析師使用。
過去這幾年,螞蟻金服一直積極參與開源社群共建,自2011年宣佈第一波開源專案以來,開源專案數量每年皆有增長。目前螞蟻金服已有 30 多個開源專案,其中,Ant Design專案已獲三萬多Star,有600 多人蔘與專案建設,EggJS和SOFA 系列也成為了社群熱門。
在 SQLFlow 的 GitHub 專案中,螞蟻金服提供了 SQLFlow 的安裝指引以及快速入門的示例,對此專案感興趣的開發者不妨一試。
原文連結
本文為雲棲社群原創內容,未經