
BAT面試必問HashMap原始碼分析
HashMap 簡介
HashMap 主要用來存放鍵值對,它基於雜湊表的Map介面實現,是常用的Java集合之一。
JDK1.8 之前 HashMap 由 陣列+連結串列 組成的,陣列是 HashMap 的主體,連結串列則是主要為了解決雜湊衝突而存在的(“拉鍊法”解決衝突).JDK1.8 以後在解決雜湊衝突時有了較大的變化,當連結串列長度大於閾值(預設為 8)時,將連結串列轉化為紅黑樹,以減少搜尋時間。
底層資料結構分析
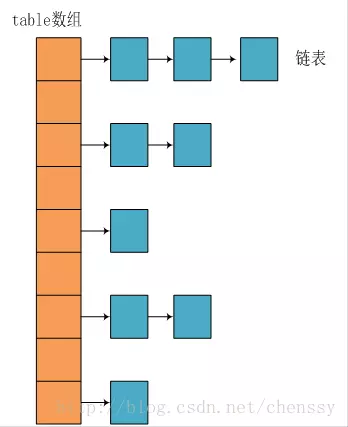
JDK1.8之前
JDK1.8 之前 HashMap 底層是 陣列和連結串列 結合在一起使用也就是 連結串列雜湊。HashMap 通過 key 的 hashCode 經過擾動函式處理過後得到 hash 值,然後通過 (n - 1) & hash
所謂擾動函式指的就是 HashMap 的 hash 方法。使用 hash 方法也就是擾動函式是為了防止一些實現比較差的 hashCode() 方法 換句話說使用擾動函式之後可以減少碰撞。
JDK 1.8 HashMap 的 hash 方法原始碼:
JDK 1.8 的 hash方法 相比於 JDK 1.7 hash 方法更加簡化,但是原理不變。
| 1 2 3 4 5 6 7 |
|
對比一下 JDK1.7的 HashMap 的 hash 方法原始碼.
| 1 2 3 4 5 6 7 8 |
|
相比於 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的效能會稍差一點點,因為畢竟擾動了 4 次。
所謂 “拉鍊法” 就是:將連結串列和陣列相結合。也就是說建立一個連結串列陣列,陣列中每一格就是一個連結串列。若遇到雜湊衝突,則將衝突的值加到連結串列中即可。
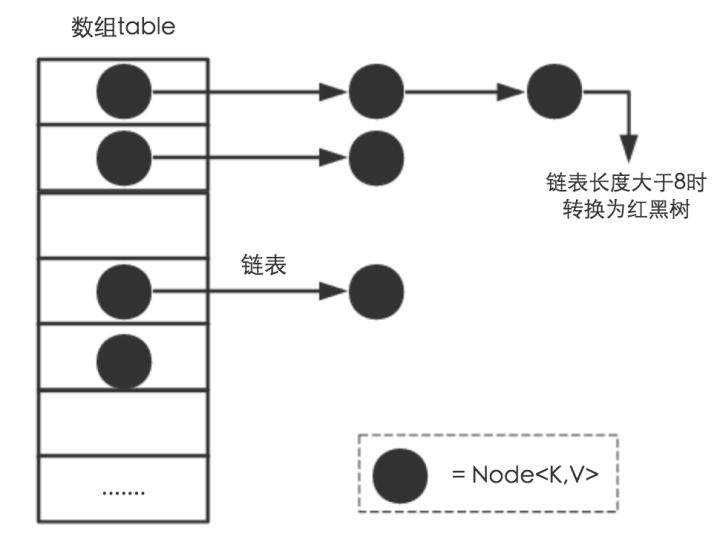
JDK1.8之後
相比於之前的版本,jdk1.8在解決雜湊衝突時有了較大的變化,當連結串列長度大於閾值(預設為8)時,將連結串列轉化為紅黑樹,以減少搜尋時間。
類的屬性:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
- loadFactor載入因子
loadFactor載入因子是控制陣列存放資料的疏密程度,loadFactor越趨近於1,那麼 陣列中存放的資料(entry)也就越多,也就越密,也就是會讓連結串列的長度增加,load Factor越小,也就是趨近於0,
loadFactor太大導致查詢元素效率低,太小導致陣列的利用率低,存放的資料會很分散。loadFactor的預設值為0.75f是官方給出的一個比較好的臨界值。
- threshold
threshold = capacity * loadFactor,當Size>=threshold的時候,那麼就要考慮對陣列的擴增了,也就是說,這個的意思就是 衡量陣列是否需要擴增的一個標準。
Node節點類原始碼:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
|
樹節點類原始碼:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
HashMap原始碼分析
構造方法

| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
|
putMapEntries方法:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
|
put方法
HashMap只提供了put用於新增元素,putVal方法只是給put方法呼叫的一個方法,並沒有提供給使用者使用。
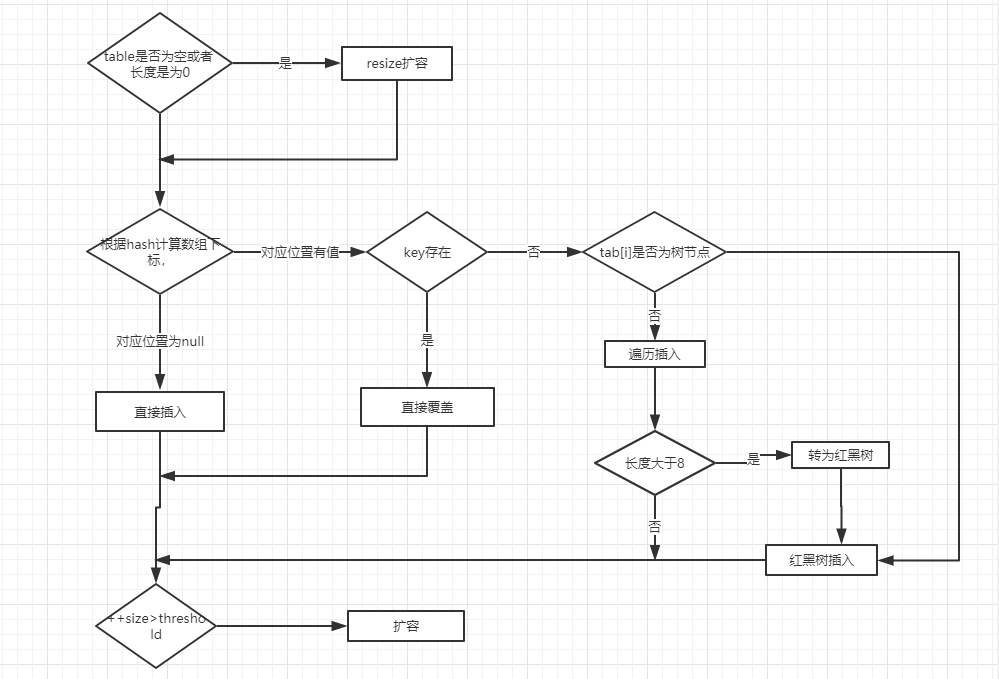
對putVal方法新增元素的分析如下:
- ①如果定位到的陣列位置沒有元素 就直接插入。
- ②如果定位到的陣列位置有元素就和要插入的 key 比較,如果key相同就直接覆蓋,如果 key 不相同,就判斷 p 是否是一個樹節點,如果是就呼叫
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)將元素新增進入。如果不是就遍歷連結串列插入。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
|
我們再來對比一下 JDK1.7 put方法的程式碼
對於put方法的分析如下:
- ①如果定位到的陣列位置沒有元素 就直接插入。
- ②如果定位到的陣列位置有元素,遍歷以這個元素為頭結點的連結串列,依次和插入的key比較,如果key相同就直接覆蓋,不同就採用頭插法插入元素。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
get方法
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
resize方法
進行擴容,會伴隨著一次重新hash分配,並且會遍歷hash表中所有的元素,是非常耗時的。在編寫程式中,要儘量避免resize。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
|
HashMap常用方法測試
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
|