01 | 健康之路 kubernetes(k8s) 實踐之路 : 開篇及概況
近幾年容器相關的技術大行其道,容器、docker、k8s、mesos、service mesh、serverless等名詞相信大家多少都有聽過,國內網際網路公司無一不接觸和使用相關技術。
健康之路早在2016年就啟動了容器化的評估。眼觀現在容器化相關技術的穩定性和可行性也得到了很多的驗證,在這樣的前提下我們啟動了容器化實踐之路。
當然在實踐的過程中我們也不乏遇到了一些問題,我們希望通過文字來記錄和分享我們遇到的一些事情,也希望為大家的容器化之路帶來幫助。
概要
目標讀者
此係列文章不會涉及到很多的k8s技術,只涉及到我們最終定案和使用的方案。並且文章不會從頭開始,會假設大家對k8s有一定了解有一些基礎,最佳的目標讀者是正在應用k8s初期和準備應用k8s的公司。
因為k8s的生態非常好,相關文章也特別多,入門及介紹文章、文件非常的多,大家可以自行的去補充相關的知識。
但有一個很重要的問題是沒有完整的生產可用的系列文章,很多是針對k8s能力的技術文章和實現剖析。
就算有大廠的應用案例文章但談及的粒度也比較粗只能提供一個大概的解決思路細的問題還要需要自己去摸索。
剛接觸k8s該如何學習?
如果大家剛入門k8s推薦主看官方文件(英文)不要因為英文而怯步,通過翻譯軟體基本可以大致看懂。原因呢很簡單:k8s發展的非常迅速,只有官方文件才是最可靠的,很多內容已經是過時的了。
輔助的話大家可以去搜尋一些系列文章(一樣的零散的文章因為k8s的版本不一致而容易造成困擾),本人是通過XX時間上的k8s系列課程入門的,推薦剛入門的同學可以先從這個系列開始。對k8s有一定的掌握力後根據系列課程的內容再去k8s官方文件上加強學習一遍。
近期阿里雲有推出了一個系列課程:《CNCF × Alibaba 雲原生技術公開課》(XX時間上面系列的作者也在其中哦)目前還在更新中,內容也寫得非常好可以在用來加強學習一下。
我們目前做了什麼?
Fleet(自研,基於k8s打造的公司適用的容器運維和持續整合系統)
公司微服務框架的升級(相容k8s引入後的原微服務呼叫)
生產線高可用k8s叢集搭建
伺服器資源(CPU、記憶體)緊張時頻繁宕機的優化和避免
高可用BGP ClusterIP和PodIP及通過交換機打通現有網路與k8s叢集內網路的互通
全域性容器hosts
Java8(JVM)在容器中的調優和優化
PHP容器化
簡單的監控和告警(Prometheus + Grafana)
技術選型
- 編排系統:kubernetes(當前版本1.14.1)
- CRI:Docker(當前版本18.09.4)
- CNI:Calico(當前版本3.7.2)
- Image Registry:Harbor(當前版本1.7.5,準備升級1.8.0)
- 負載均衡:LVS、HAProxy
- 叢集引導:kubeadm(當前版本1.14.1)
- 監控告警:Prometheus + Grafana
- Fleet
- 後端:Java8 + Spring全家桶 + fabric8io kubernetes-client
- 前端:TypeScript + React + Ant Design Pro
k8s部署方式的選擇
我們之前有考慮過兩種方案進行k8s叢集的部署。
- 物理機+k8s
- 虛擬機器+k8s
最終我們選擇了虛擬機器+k8s。
因為我們覺得虛擬機器帶來的損耗是我們可以忍受的。一些效能的損耗換來較好的維護性這是我們想要的。
我們的現狀
由於早期的技術正確選型,公司在以微服務的架構方式進行開發已經經歷了很長的時間。
所以我們的大部分應用都是無狀態的。這點為我們遷移k8s帶來了非常多的幫助(總所周知有狀態的應用程式是非常難遷移的,同樣在k8s中也顯得比較麻煩)。
所以如果大家現在大部分的應用還是有狀態的,可以先考慮進行應用重構在考慮遷移至k8s。
開發線(整體遷移進行中)
在開發線我們基本上已經可以遷移到k8s上,也正在逐步回收資源,將回收後的資源逐步加入k8s中,目前運行了80天左右,最後一次故障在一個月前(開發線資源緊張,因為資源緊張觸發了一個node頻繁宕機的小坑,後面會有專門的篇幅跟大家詳細分享),已穩定運行了30天左右。
目前我們的開發線k8s叢集因為資源關係不是高可用的。
master一臺(etcd堆疊)
node五臺
harbor一臺
總計7臺虛擬機器
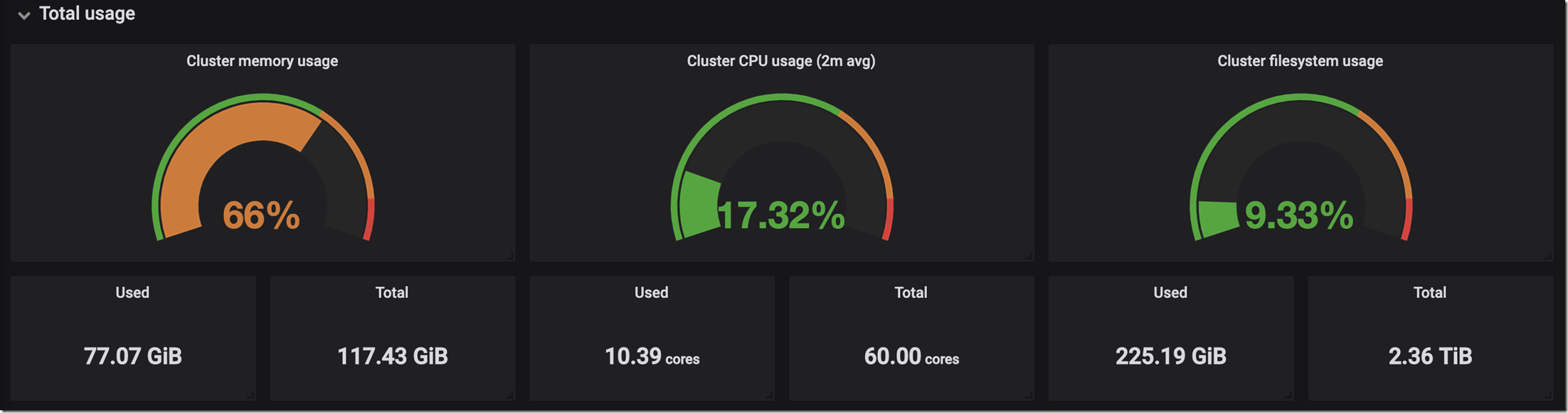
應用情況

伺服器資源情況
生產線(邊緣應用遷移)
在生產線我們騰挪了一部分資源用來搭建高可用的k8s叢集環境。
同時我們在生產線的動作也比較保守,目前遷移了小部分邊緣應用(非核心業務)到生產線。同時公司RP微服務元件使用的是TCP長連線也踩了一個負載均衡的小坑目前還在優化相容中。後面會有詳細的篇幅來說明這個問題。
由於生產線資源比較充足至搭建完成沒有發生過k8s故障(中間有因為網路策略配置失誤導致了一小段服務不可訪問)。
目前已穩定執行53天。
master三臺
node四臺
etcd三臺
harbor兩臺
lvs兩臺
haproxy兩臺
總計17臺虛擬機器
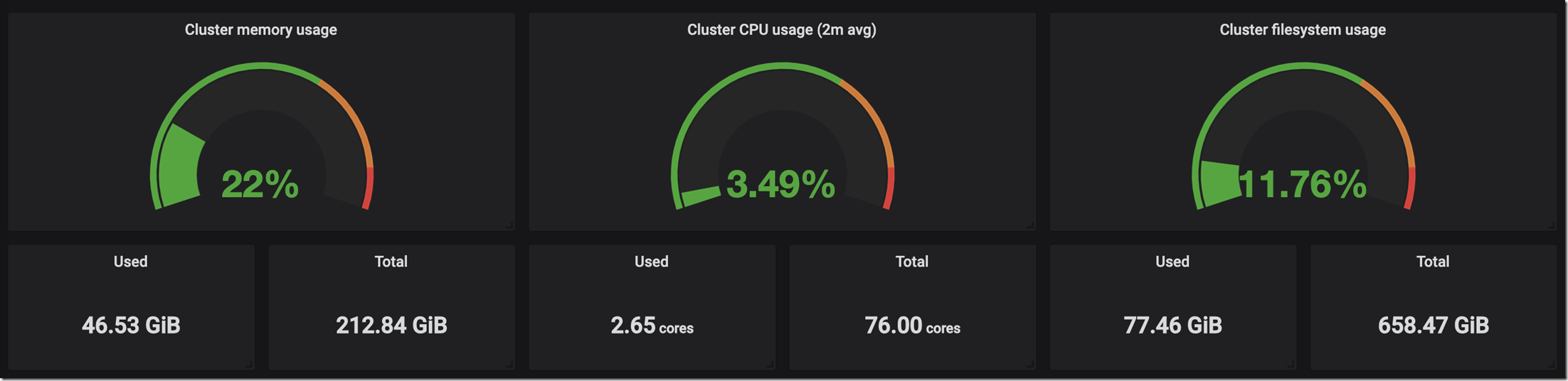
應用情況

伺服器資源情況
我們的不足和後續要做的事情
我們目前沒有使用到CSI相關的內容,我們目前也不支援有狀態的應用程式。後續我們會考慮建立Ceph叢集來加入這塊的能力。
我們目前也沒有使用Ingress能力(我們目前採用Service的ClusterIP),後續根據急迫程度可能會考慮加入Ingress能力。
我們目前沒有做日誌收集(目前是依賴程式自己的日誌傳輸邏輯自行檢視或通過Fleet系統的控制檯日誌功能WebShell功能進行診斷)
我們目前的構建系統比較固定,沒有那麼靈活,後續可能會引入Drone等第三方構建系統進行構建。
.net core的容器化
有沒有系列大綱?下一篇會分享什麼?
抱歉,我實在沒有那麼強的全域性觀去梳理出全部的分享大綱。我會根據我們遇事的大致順序進行分享。我會在每篇的結尾寫出下一篇大概會分享什麼內容。
下一篇應該會分享:高可用k8s叢集搭建的內容,不會詳細的說明搭建步驟(會分享我們目前的拓補圖、高可用測試方案等內容),此係列的主要目標讀者還是有一定基礎的同學,會點到為止。
最後
首先是感謝。感謝領導CTO和經理的鼎立支援和協調。感謝k8s社群帶來的優秀能力和文件。
ps:分享的所有內容不一定完全是我的成果,其中我們的小夥伴也一直在支援這個專案。
如果大家有疑問和需要交流的可以通過評論功能或私信我(推薦優先使用評論,評論的內容也是讀者的一筆財富)。
公司(福建福州)目前還有一些技術崗位(java、大資料工程師)缺口,有興趣的同學可以給我發訊息,我可以66幫忙轉發。
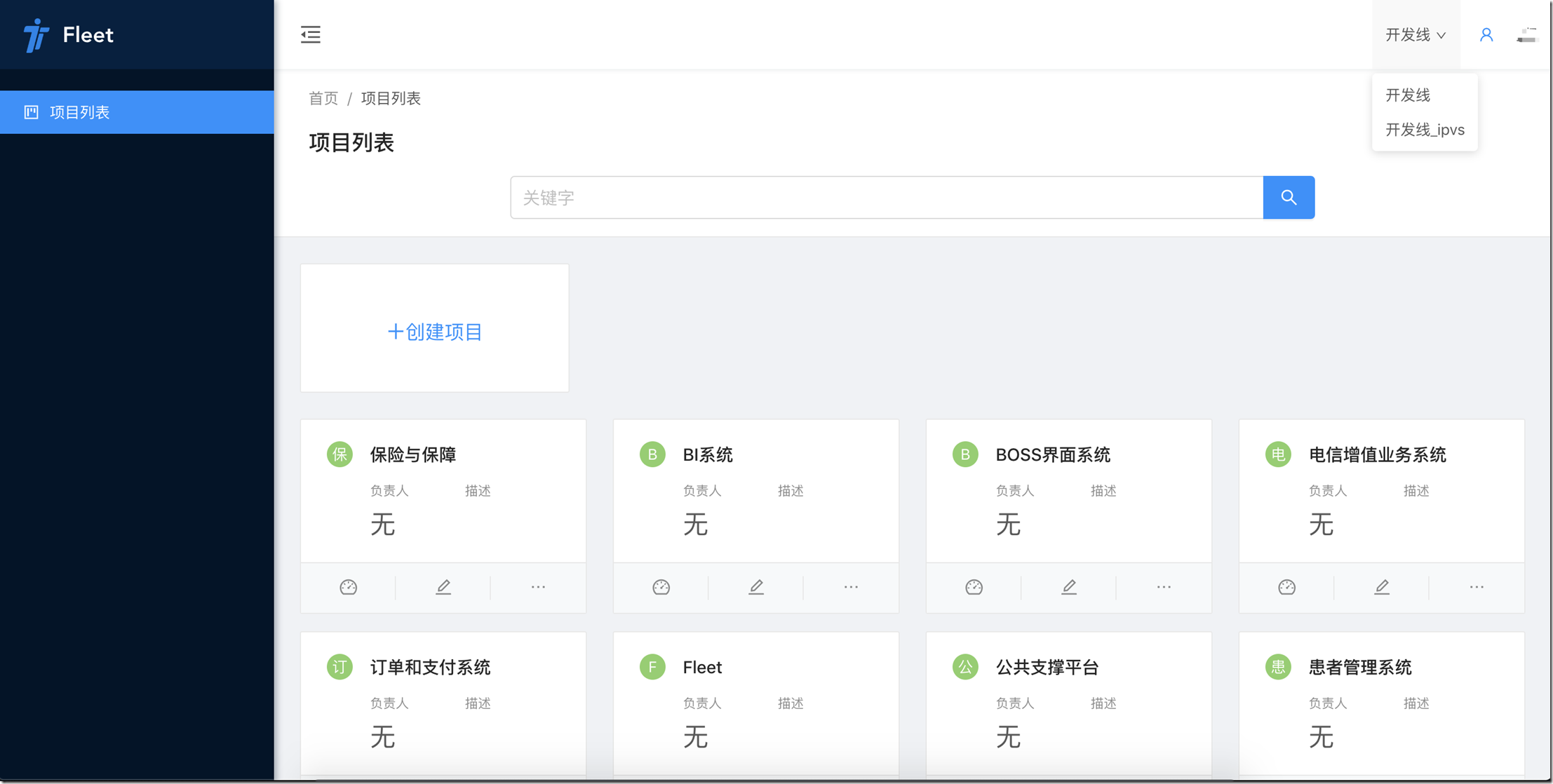
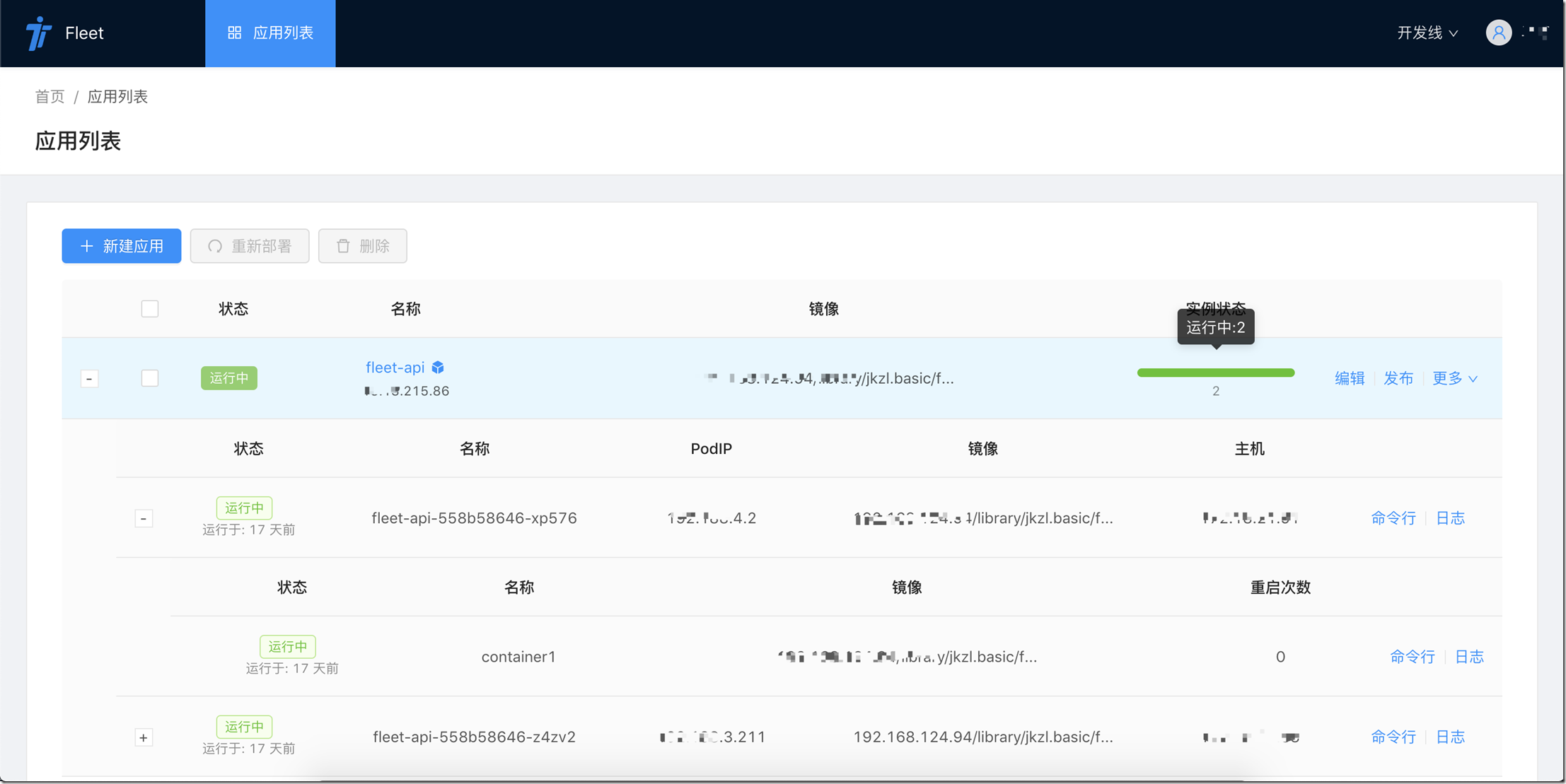
關於Fleet
Fleet系統是我們公司自研的一套容器運維和持續構建系統。
系統的後續出現方式未定。
Fleet系統我們是有分期規劃的。
目前處在2期進行中(1期是基本滿足公司開發人員遷移到k8s的日常運維和使用)。
下面是部分系統截圖