
02 | 健康之路 kubernetes(k8s) 實踐之路 : 生產可用環境及驗證
上一篇《 01 | 健康之路 kubernetes(k8s) 實踐之路 : 開篇及概況 》我們介紹了我們的大體情況,也算邁出了第一步。今天我們主要介紹下我們生產可用的叢集架設方案。涉及了整體拓補圖,和我們採用的硬體配置,目前存在的問題等內容。
遵循上一篇提到的系列風格,這邊不涉及基礎的內容,這些基礎的內容大家可以通過官方文件或其它渠道進行補充,主要還是分享實踐經驗及注意點。
涉及到的內容
- LVS
- HAProxy
- Harbor
- Etcd
- Kubernetes (master、node)
整體拓撲圖
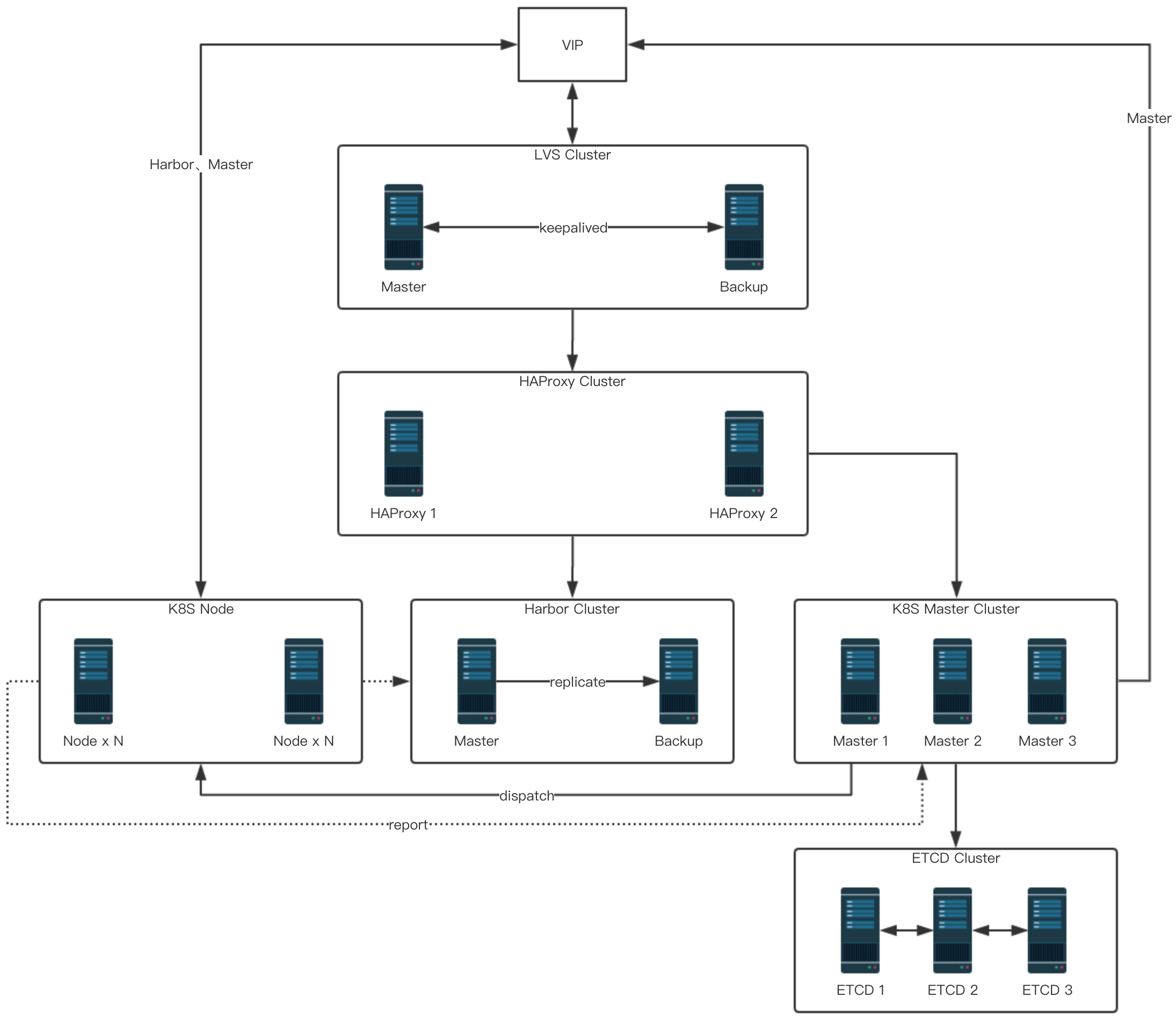
以上就是我們目前在生產線的整體拓補圖(隱去了IP,除了 K8S Node塊其它例項數與圖中一致)
SLB
LVS 、HAProxy 被規劃為基礎層,主要提供了一個高可用的7層負載均衡器。
由LVS keepalived 提供一個高可用的VIP(虛擬IP)。
這個VIP DR模式轉發到後端的兩臺HAProxy伺服器。
HAProxy反代了K8S Master和Harbor伺服器,提供了K8S Master API和Harbor的高可用和負載均衡能力。
為什麼不使用Nginx?
這個使用nginx也完全沒問題,根據自己的喜好選擇,這邊選擇HAProxy的主要原因是k8s官方文件中出現了HAProxy。
能否不使用HAProxy,直接從LVS轉發到Master?
理論上可行,我們沒有試驗。
如果不缺兩臺機器推薦還是架設一層具有7層代理能力的服務。
k8s apiserver、harbor、etcd都是以HTTP的方式提供的api,如果有7層代理能力的服務後續會更容易維護和擴充套件。
硬體配置
用途 | 數量 | CPU | 記憶體 |
Keepalived | 2 | 2 | 4GB |
HAProxy | 2 | 2 | 4GB |
kubernetes叢集
kubernetes叢集主要有兩種型別的節點:master和node。
master則是叢集領導。
node是工作者節點。
可以看出這邊主要的工作在master節點,node節點根據具體需求隨意增減就好了。
master節點的高可用拓補官方給出了兩種方案。
External etcd topology(外部etcd)
可以看出最主要的區別在於etcd。
第一種方案是所有k8s master節點都執行一個etcd在本機組成一個etcd叢集。
第二種方案則是使用外部的etcd叢集(額外搭建etcd叢集)。
我們採用的是第二種,外部etcd,拓補圖如下:

如果採用堆疊的etcd拓補圖則是:

這邊大家可以根據具體的情況選擇,推薦使用第二種,外部的etcd。
參考來源:https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/ha-topology/
Master節點的元件
- apiserver
- controller-manager
- scheduler
一個master節點主要含有上面3個元件 ( 像cloud-controller-manager這邊就不多做說明了,正常不會用到 )。
apiserver: 一個api伺服器,所有外部與k8s叢集的互動都需要經過它。(可水平擴充套件)
controller-manager: 執行控制器邏輯(迴圈通過apiserver監控叢集狀態做出相應的處理)(一個master叢集中只會有一個節點處於啟用狀態)
scheduler: 將pod排程到具體的節點上(一個master叢集中只會有一個節點處於啟用狀態)
可以看到除了apiserver外都只允許一個 例項處於啟用狀態(類HBase)運行於其它節點上的例項屬於待命狀態,只有當啟用狀態的例項不可用時才會嘗試將自己設為啟用狀態。
這邊牽扯到了領導選舉(zookeeper、consul等分散式集群系統也是需要領導選舉)
Master高可用需要幾個節點?失敗容忍度是多少?
k8s依賴etcd所以不存在資料一致性的問題(把資料一致性壓到了etcd上),所以k8s master不需要採取投票的機制來進行選舉,而只需節點健康就可以成為leader。
所以這邊master並不要求奇數,偶數也是可以的。
那麼master高可用至少需要2個節點,失敗容忍度是(n/0)+1,也就是隻要有一個是健康的k8s master叢集就屬於可用狀態。(這邊需要注意的是master依賴etcd,如果etcd不可用那麼master也將不可用)
Master元件說明: https://kubernetes.io/docs/concepts/overview/components/
部署文件: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/
硬體配置
用途 | 數量 | CPU | 記憶體 |
k8s master | 3 | 4 | 6GB |
etcd
etcd是一個採用了raft演算法的分散式鍵值儲存系統。
這不是k8s專屬的是一個獨立的分散式系統,具體的介紹大家可以參考官網,這邊不多做介紹。
我們採用了 static pod的方式部署了etcd叢集。
失敗容忍度
最小可用節點數:(n/2)+1
總數 | 最少存活 | 失敗容忍 |
1 | 1 | 0 |
2 | 2 | 0 |
3 | 2 | 1 |
4 | 3 | 1 |
5 | 3 | 2 |
6 | 4 | 2 |
7 | 4 | 3 |
8 | 5 | 3 |
9 | 5 | 4 |
硬體配置
用途 | 數量 | CPU | 記憶體 |
etcd | 3 | 4 | 8GB |
官網: https://etcd.io/
官方硬體建議: https://etcd.io/docs/v3.3.12/op-guide/hardware/
部署文件: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/setup-ha-etcd-with-kubeadm/
Harbor
harbor是一個開源的docker映象庫系統。
眼尖的人可以看出,拓補圖中的harbor拓補的高可用其實是存在問題的。
我們目前採用的是雙主模式:
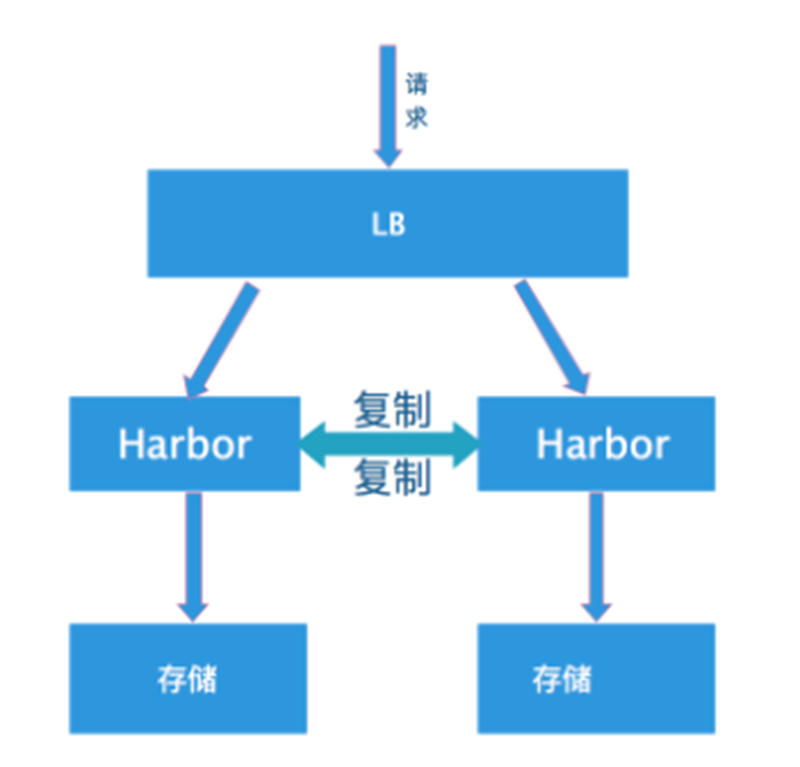
可以發現,如果複製過程中出現了問題那麼就可能會造成間歇性pull映象失敗。
真正推薦的做法是共享後端儲存,將harbor例項做成無狀態的:

由於我們剛起步,還沒有搭建分散式儲存系統,後面當搭建了Ceph集群后會轉成這種模式。
如果大家現狀允許可以直接採用共享儲存的方式搭建harbor。
高可用驗證
至此生產可用的k8s叢集已“搭建完成”。為什麼打引號?因為我們還沒有進行測試和驗證,下面給出我們列出的上線前的驗證清單。
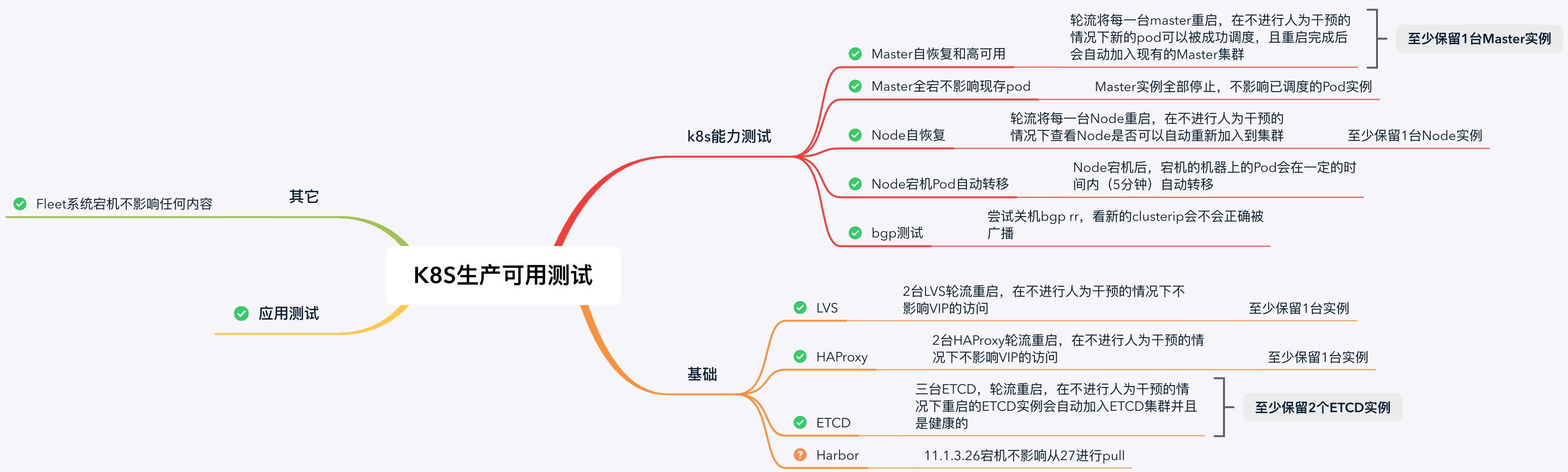
其中harbor由於我們採用的是雙主,所以目前還標記為警告狀態。
還有涉及的BGP相關的驗證不在此次文章內容中,後續會為大家說明。
寫在最後
還有一點需要注意的是物理機的可用性,如果這些虛擬機器全部在一臺物理機上那麼還是存在“單點問題”。這邊建議至少3臺物理機以上。
為什麼需要3臺物理機以上?
主要是考慮到了etcd的問題,如果只有兩臺物理機部署了5個etcd節點,那麼部署了3個etcd的那臺物理機故障了,則不滿足etcd失敗容忍度而導致etcd叢集宕機,從而導致k8s叢集宕機。
下一篇大概會是什麼內容?
應該會寫,k8s master、node的一些可選配置調優和推薦。