
Ansj與hanlp分詞工具對比
一、Ansj
1、利用DicAnalysis可以自定義詞庫:
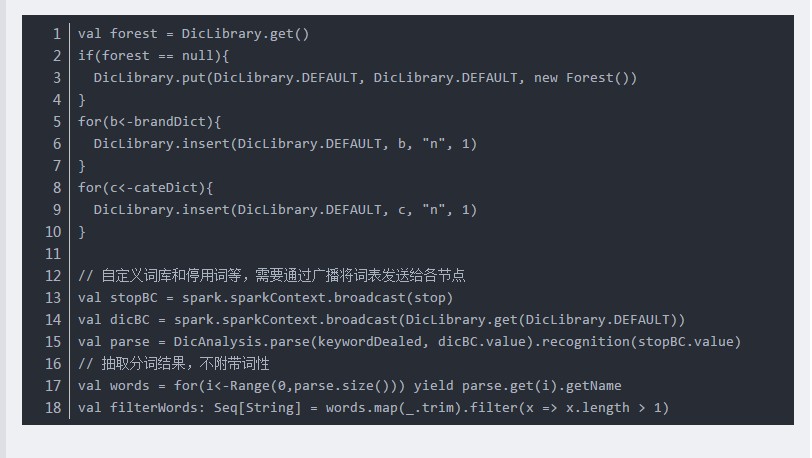
2、但是自定義詞庫存在侷限性,導致有些情況無效:
比如:“不好用“的正常分詞結果:“不好,用”。
(1)當自定義詞庫”好用“時,詞庫無效,分詞結果不變。
(2)當自定義詞庫
“不好用”時,分詞結果為:“不好用”,即此時自定義詞庫有效。
3、由於版本問題,可能DicAnalysis, ToAnalysis等類沒有序列化,導致讀取hdfs資料出錯
此時需要繼承序列化介面
1|case class myAnalysis() extends DicAnalysis with Serializable
2|val seg = new myAnalysis()
二、HanLP
同樣可以通過CustomDictionary自定義詞庫:
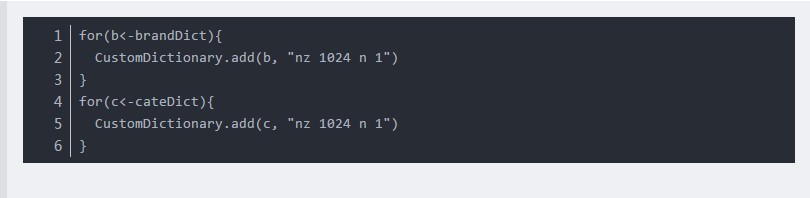
但是在統計分詞中,並不保證自定義詞典中的詞一定被切分出來,因此使用者可在理解後果的情況下通過
1|StandardTokenizer.SEGMENT.enableCustomDictionaryForcing(true)強制生效
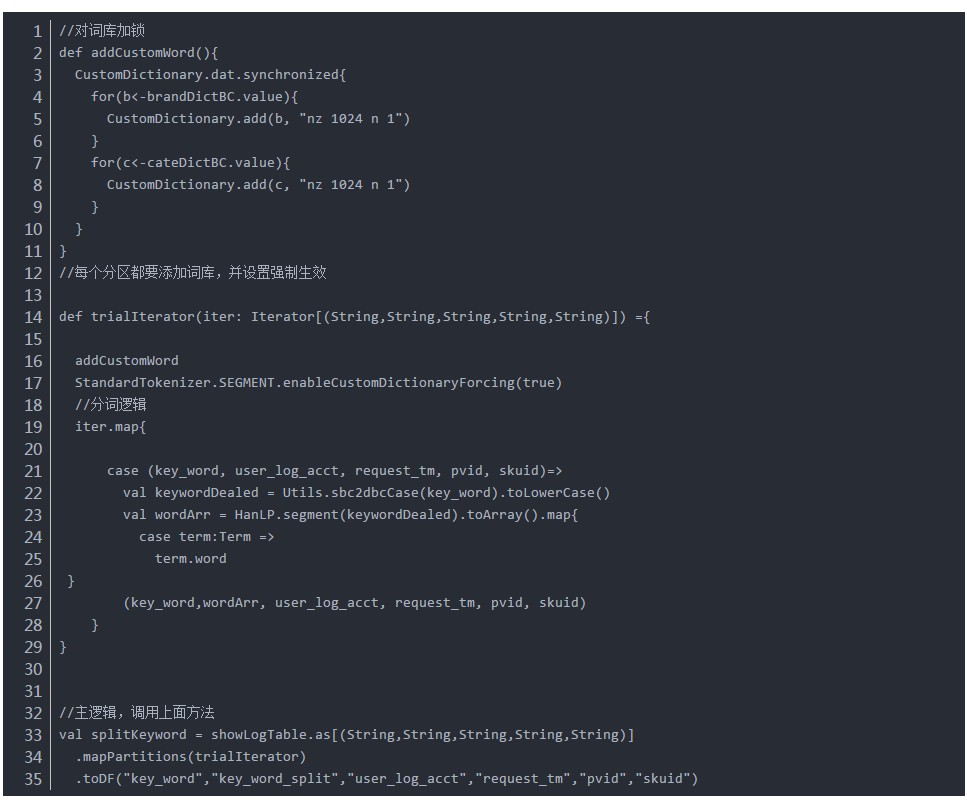
併發問題:
CustomDictionary是全域性變數,不能在各節點中更改,否則會出現併發錯誤。
但是HanLP.segment(sentence),只有一個引數,不能指定CustomDictionary,導致在各個excutors計算的時候全域性CustomDictionary無效。
由於CustomDictionary是全域性變數,因此我採用一個方式:每個分割槽都對CustomDictionary加鎖並新增一次詞庫,效能影響較小:
相關推薦
Ansj與hanlp分詞工具對比
一、Ansj 1、利用DicAnalysis可以自定義詞庫: 2、但是自定義詞庫存在侷限性
Lucene7.0與HanLP分詞器整合索引資料庫建立索引檔案
HanLP官網:http://hanlp.linrunsoft.com/ GitHup地址:https://github.com/hankcs/HanLP HanLP外掛地址:https://github.com/hankcs/hanlp-lucene-plugin 需要一下ja
大資料工具:IKAnalyzer分詞工具介紹與使用
簡單介紹IKAnalyzer分詞工具與使用 文章目錄 簡介 IKAnalyzer的引入使用 IK的兩個重要詞典 IK的使用 簡介 以下簡介參考前輩和專案文件介紹 為什麼要分詞呢,當
開源中文分詞工具探析(三):Ansj
Ansj是由孫健(ansjsun)開源的一箇中文分詞器,為ICTLAS的Java版本,也採用了Bigram + HMM分詞模型(可參考我之前寫的文章):在Bigram分詞的基礎上,識別未登入詞,以提高分詞準確度。雖然基本分詞原理與ICTLAS的一樣,但是Ansj做了一些工程上的優化,比如:用DAT高效地實現檢
Java分詞工具HanLP
HanLP是由一系列模型與演算法組成的Java工具包,目標是普及自然語言處理在生產環境中的應用。不僅僅是分詞,而是提供詞法分析、句法分析、語義理解等完備的功能。HanLP具備功能完善、效能高效、架構清晰、語料時新、可自定義的特點。 HanLP完全開源,包括詞典
NLP自然語言處理中英文分詞工具集錦與基本使用介紹
一、中文分詞工具 (1)Jieba (2)snowNLP分詞工具 (3)thulac分詞工具 (4)pynlp
HanLP《自然語言處理入門》筆記--3.二元語法與中文分詞
筆記轉載於GitHub專案:https://github.com/NLP-LOVE/Introduction-NLP 3. 二元語法與中文分詞 上一章中我們實現了塊兒不準的詞典分詞,詞典分詞無法消歧。給定兩種分詞結果“商品 和服 務”以及“商品 和 服務”,詞典分詞不知道哪種更加合理。 我們人類確知道第二種更
漢語分詞工具的研發-----
中文 analysis targe item api arc 動手 ica 8.4 當時打醬油做的大創,除了看源代碼之外,什麽數學原理,始終沒有動手實踐過,站在巨人的肩上,就這麽完成了大創。。 想不到時隔兩年還要被迫回來學習,所以呀 出來混 還是要腳踏實地 親力親為
jieba分詞工具的使用
多個 ictclas 基礎上 創新 需要 ica 入參 標註 erb 煩煩煩( ˇ?ˇ ) http://www.oschina.net/p/jieba/ 搬運工。。。。。 jieba "結巴"中文分詞:做最好的Python中文分詞組件 "Jieba"。 Feature
PyNLPIR python中文分詞工具
命名 hub 兩個 工具 ict mage ret wid tty 官網:https://pynlpir.readthedocs.io/en/latest/ github:https://github.com/tsroten/pynlpir NLPIR分詞系
開源中文分詞工具探析(六):Stanford CoreNLP
inf git deb seq 效果 analysis stream fix sps CoreNLP是由斯坦福大學開源的一套Java NLP工具,提供諸如:詞性標註(part-of-speech (POS) tagger)、命名實體識別(named entity recog
IKAnalyzer分詞工具不能處理完所有數據,中途中斷
blank jar 什麽 不知道 arc archive 進行 bubuko image 不知道為什麽,本來1萬條的數據在進行分詞時候,只分了8千就結束了。試了另一批數據2萬條的數據,可以完全分完。 後來把jar包的版本更換掉:將2013版的換成2012_u6版的,就可以正
轉載:Spark 使用ansj進行中文分詞
轉載:https://www.cnblogs.com/JustIsQiGe/p/8006734.html 在Spark中使用ansj分詞先要將ansj_seg-5.1.1.jar和nlp-lang-1.7.2.jar加入工程 ansj原始碼github:https://github.com/
Elasticsearch整合HanLP分詞器
1、通過git下載分詞器程式碼。 連線如下:https://gitee.com/hualongdata/hanlp-ext hanlp官網如下:http://hanlp.linrunsoft.com/ 2、下載gradle,如果本機有,就可以略過此步驟。通過gradle
自然語言處理——中文分詞原理及分詞工具介紹
本文首先介紹下中文分詞的基本原理,然後介紹下國內比較流行的中文分詞工具,如jieba、SnowNLP、THULAC、NLPIR,上述分詞工具都已經在github上開源,後續也會附上github連結,以供參考。 1.中文分詞原理介紹 1.1 中文分詞概述 中文分詞(Chinese Word Seg
lucene使用hanlp分詞
maven依賴 4.0.0 ff dd 0.0.1-SNAPSHOT jar dd http://maven.apache.org org.apache.lucene lucene-core ${lucene.version} org.apache.lucene lucene-
Elasticsearch初探(3)——簡單查詢與中文分詞
一、簡單查詢 1.1 查詢全部 請求方式: GET 請求路徑: ES服務的IP:埠/索引名/{分組,可省略}/_search 以上篇文章建立的索引為例,搜尋結果如下: { "took": 0, "timed_out": false, "
Spring框架中呼叫HanLP分詞的方法
事情是這樣的,最近實驗室在搞一個Java Web的專案,用的Spring MVC的框架。專案組有很多沒做過Spring的學弟學妹,為了提高效率,我讓大家自己先拋開Spring來寫自己負責的模組,我來把各個模組在Spring裡整合。 專案裡有一個文字分析的模組是一
NLPIR(ICTCLAS2015)分詞工具Java開發簡介
分詞往往是自然語言處理的第一步。在分詞的基礎上,我們可以進行關鍵字的提取、搜尋、糾錯等應用。在理論上,分詞可以採用的方法有很多,最經典的辦法莫過於HMM模型、CRF及其它語言模型如Bigram、Trigram等。NLPIR(又名:ICTCLAS2015)是由中科院張華平博士研發的,基於HMM模型免費
HanLP分詞器的使用方法
前言:分析關鍵詞如何在一段文字之中提取出相應的關鍵詞呢? 之前我有想過用機器學習的方法來進行詞法分析,但是在專案中測試時正確率不夠。於是這時候便有了 HanLP-漢語言處理包 來進行提取關鍵詞的想法。 下載:.jar .properties data等檔案這裡提供官網下載地址 HanLP下載,1.3.3資料