
簡單描述深度優先和廣度優先遍歷,以及區別?
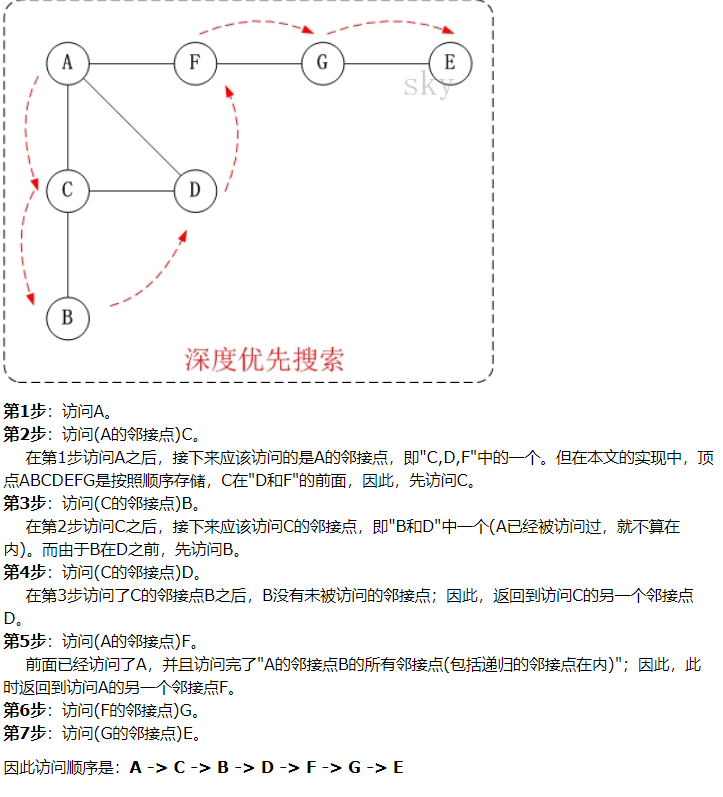
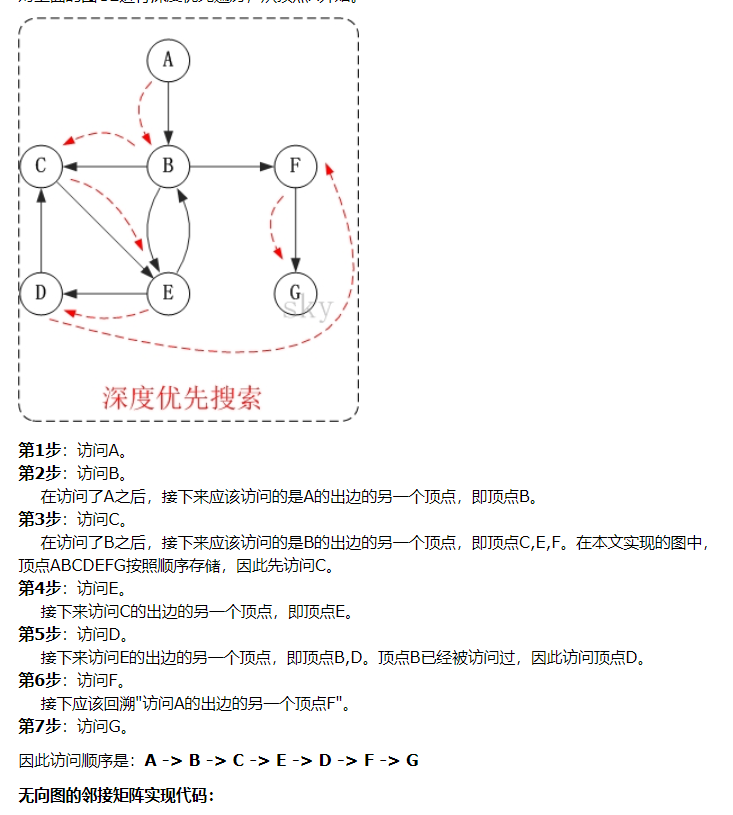
深度優先遍歷從某個頂點出發,首先訪問這個頂點,然後找出剛訪問這個結點的第一個未被訪問的鄰結點,然後再以此鄰結點為頂點,繼續找它的下一個新的頂點進行訪問,重複此步驟,直到所有結點都被訪問完為止。
深度優先有什麼用?最大路徑問題
廣度優先遍歷:
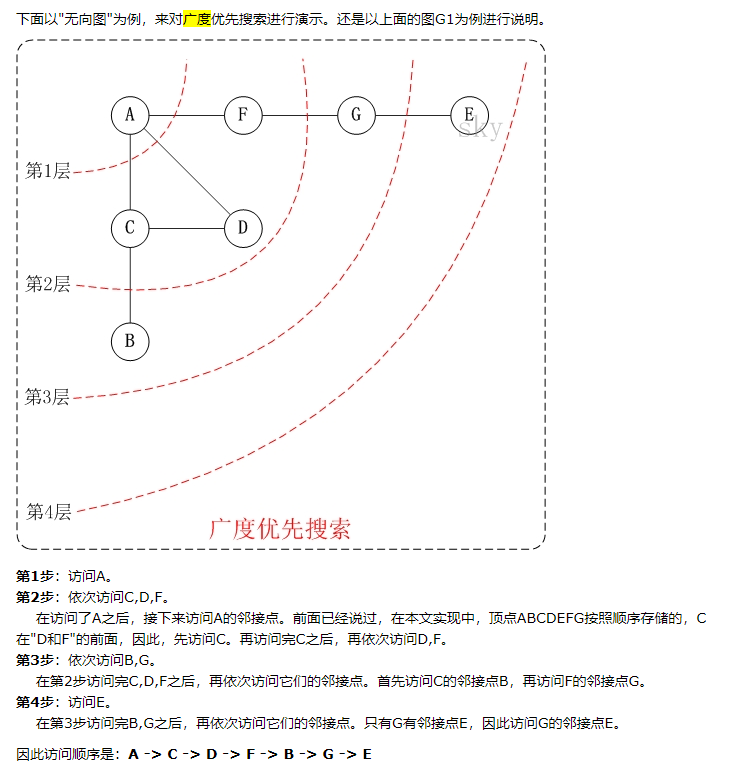
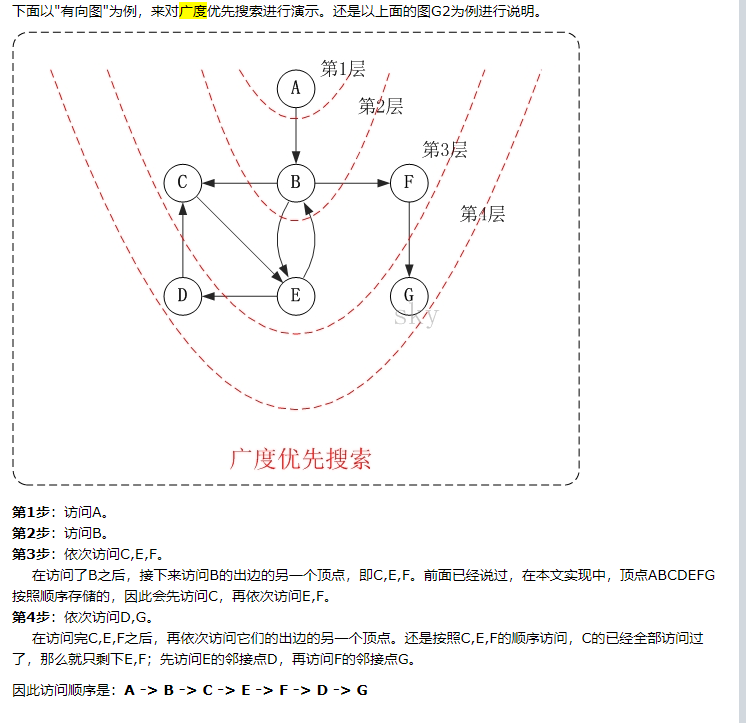
廣度優先遍歷從某個頂點出發,首先訪問這個頂點,然後找出這個結點的所有未被訪問的鄰接點,訪問完後再訪問這些結點中第一個鄰接點的所有結點,重複此方法,直到所有結點都被訪問完為止。
廣度優先有什麼用?最短路徑問題
區別:
兩種方法最大的區別在於前者(深度)從頂點的第一個鄰接點一直訪問下去再訪問頂點的第二個鄰接點;(廣度)後者從頂點開始訪問該頂點的所有鄰接點再依次向下,一層一層的訪問
相關推薦
簡單描述深度優先和廣度優先遍歷,以及區別?
深度優先遍歷從某個頂點出發,首先訪問這個頂點,然後找出剛訪問這個結點的第一個未被訪問的鄰結點,然後再以此鄰結點為頂點,繼續找它的下
實驗三:二叉樹的操作(結構轉換,遞迴和非遞迴的先序、中序和後序遍歷,以及層次遍歷,葉子結點和總結點的計數)
(1)將一棵二叉樹的所有結點儲存在一維陣列中,虛結點用#表示,利用二叉樹性質5,建立二叉樹的二叉連結串列。 (2) 寫出對用二叉連結串列儲存的二叉樹進行先序、中序和後序遍歷的遞迴和非遞迴演算法。 (3)寫出對用二叉連結串列儲存的二叉樹進行層次遍歷演算法。 (4)求二叉樹
圖的遍歷之深度優先和廣度優先
優先 ges sky 深度優先 們的 老師 ear blog earch 圖的遍歷之深度優先和廣度優先 深度優先遍歷 假設給定圖G的初態是所有頂點均未曾訪問過。在G中任選一頂點v為初始出發點(源點),則深度優先遍歷可定義如下:首先訪問出發點v,並將其標記為已訪問過;然後依
基於鄰接表儲存的圖的深度優先和廣度優先遍歷
一.深度優先遍歷是連通圖的一種遍歷方法: 設x是當前被訪問頂點,在對x做過訪問標記後,選擇一條從x出發的未檢測過的邊(x, y)。若發現頂點y已訪問過,則重新選擇另一條從x出發的未檢測過的邊,否則沿邊(x,y) 到達未曾訪問過的y,對y訪問並將其標記為已訪問過;
C++ 圖的鄰接矩陣表示以及深度優先和廣度優先遍歷
Node.h 宣告頂點類 #pragma once class Node { public: Node(char data=0); char m_cData; bool m_bIsVisited; }; Node.cpp 實現頂點的成員以及操作函式 #incl
python 圖的遍歷-深度優先和廣度優先
Python的圖實現有很多別人已經寫好的(比如我下面寫的就是參考python-graph),可是不適合一個剛開始的學習的人,我就簡化了一下,實現可深度優先和廣度優先遍歷。 #!/usr/bin/env python #-*- coding:utf8 -*- clas
python 圖 遍歷-深度優先和廣度優先 II
在上一篇(python 圖 遍歷-深度優先和廣度優先)的程式碼上加了最小生成樹和拓撲序列功能。程式碼如下: #!/usr/bin/env python #-*- coding:utf8 -*- import copy class Graph(object):
深度優先和廣度優先遍歷迷宮
package didi; import java.util.Stack; /** * 深度優先迷宮問題 {{1,1,0,1}, {1,1,0,1}, {0,1,1,1}, {0,0,1,1}}; {1,1,1,0,1}, {1,0,1,0,1}, {1,0,1,1
用深度優先和廣度優先遍歷資料夾下符合條件的檔案
第一步:需要有一個萬能過濾器:MyFileFilter.java package com.ten.practice.test15; import java.io.File; import jav
資料結構--圖的理解:深度優先和廣度優先遍歷及其 Java 實現
遍歷 圖的遍歷,所謂遍歷,即是對結點的訪問。一個圖有那麼多個結點,如何遍歷這些結點,需要特定策略,一般有兩種訪問策略: 深度優先遍歷廣度優先遍歷 深度優先 深度優先遍歷,從初始訪問結點出發,我們知道初始訪問結點可能有多個鄰接結點,深度優先遍歷的策略就是首先訪問第一個
圖的深度優先和廣度優先遍歷及兩點間最優路徑實現
通用遍歷 參考:https://segmentfault.com/a/1190000002685939 遍歷 圖的遍歷,所謂遍歷,即是對結點的訪問。一個圖有那麼多個結點,如何遍歷這些結點,需要特定策略,一般有兩種訪問策略: 深度優先遍歷 廣度優先遍歷 深度優先 深度優先遍歷
二叉樹的深度優先和廣度優先遍歷
typedef enum{L,R} tagtype;typedef struct { Bitree ptr; tagtype tag;}stacknode;typedef struct{ stacknode Elem[maxsize]; int top;}SqStack;void Po
Java 實現深度優先和廣度優先遍歷
廣度優先搜尋演算法(breadth First Search, BFS) 類似於一個分層搜尋的過程,廣度優先遍歷需要使用一個佇列以保持訪問過的結點的順序,以便按這個順序來訪問這些結點的鄰接結點。 具體演算法表述如下: 訪問初始結點v並標記結點v為已訪問。
關於DOM節點的深度優先和廣度優先遍歷
HTML的樹形結構如上深度優先遍歷對於樹的深度優先遍歷,執行結果應該如下:採用遞迴方式 var arr=[]; //深度優先 function traversalDFSDOM (rootDom) { if(!rootDom)return;
深度優先和廣度優先的基礎應用
logs node con min fan step 分享 lin 判斷 圖來自啊哈算法 這裏描述的問題就是如何從1,1走到4,3 這裏有兩個解決方案,一個是用深度優先算法 初始化地圖,和標記點 int[,] ditu = new int[5,
第三篇 深度優先和廣度優先
-h oot -c 廣度優先遍歷 code 技術分享 sub depth not PS:一個網站下除了主域名,還會有多個子域名 需要通過遍歷把所有域名取到 深度優先的算法,根據上面的截圖,爬取url的順序是A--B--D--E--I---C--F-G--
深度優先和廣度優先算法
後序遍歷 wid span cde 廣度 str 特殊 產生 求解 1、深度優先算法 遍歷規則:不斷地沿著頂點的深度方向遍歷。頂點的深度方向是指它的鄰接點方向。 最後得出的結果為:ABDECFHG。 Python代碼實現的偽代碼如下: 2、廣度優先算法: 遍歷規
ES優化聚合查詢之深度優先和廣度優先
策略 字段 示例 pre collect 功率 模式 二層 信息 1.優化聚合查詢示例 假設我們現在有一些關於電影的數據集,每條數據裏面會有一個數組類型的字段存儲表演該電影的所有演員的名字。 { "actors" : [ "Fred Jones"
淺談深度優先和廣度優先(scrapy-redis)
首先先談談深度優先和廣度優先的定義 深度優先搜尋演算法(英語:Depth-First-Search,DFS)是一種用於遍歷或搜尋樹或圖的演算法。沿著樹的深度遍歷樹的節點,儘可能深的搜尋樹的分支。當節點v的所在邊都己被探尋過,搜尋將回溯到發現節點v的那條邊的起始節點。這一過程一直進行到已發現從源節點可達的所有
關於深度優先和廣度優先
在爬蟲系統中,待抓取URL佇列是很重要的一部分,待抓取URL佇列中的URL以什麼樣的順序排佇列也是一個很重要的問題,因為這涉及到先抓取哪個頁面,後抓取哪個頁面。而決定這些URL排列順序的方法,叫做抓取策略。下面是常用的兩種策略:深度優先、廣度優先 scrapy框架預設的是深度優先