
大資料案例(四)——MapReduce將檔案按照訂單號分成若干個小檔案
一、需求:將檔案按照訂單號分成若干個小檔案
二、資料準備
- 資料準備
Order_0000001 Pdt_01 222.8
Order_0000002 Pdt_05 722.4
Order_0000001 Pdt_05 25.8
Order_0000003 Pdt_01 222.8
Order_0000003 Pdt_01 33.8
Order_0000002 Pdt_03 522.8
Order_0000002 Pdt_04 122.4
- 按照訂單號將該檔案分成若干小檔案
- 最終顯示
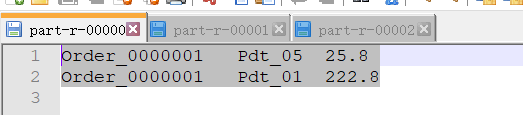
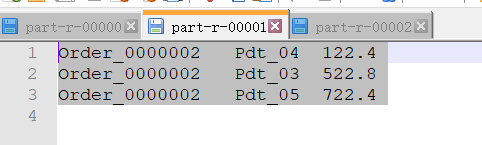
==============================part-r-0000========================== Order_0000001 Pdt_05 25.8 Order_0000001 Pdt_01 222.8 ==============================part-r-0001========================== Order_0000002 Pdt_04 122.4 Order_0000002 Pdt_03 522.8 Order_0000002 Pdt_05 722.4 ==============================part-r-0002========================== Order_0000003 Pdt_01 33.8 Order_0000003 Pdt_01 222.8
三、建立maven專案
- 專案結構
- 程式碼展示
- HDFSUtil.java
package com.ittzg.hadoop.order; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.io.IOException; import java.net.URI; /** * @email: [email protected] * @author: ittzg * @date: 2019/7/6 16:31 */ public class HDFSUtil { Configuration configuration = new Configuration(); FileSystem fileSystem = null; /** * 每次執行新增有@Test註解的方法之前呼叫 */ @Before public void init(){ configuration.set("fs.defaultFs","hadoop-ip-101:9000"); try { fileSystem = FileSystem.get(new URI("hdfs://hadoop-ip-101:9000"),configuration,"hadoop"); } catch (Exception e) { throw new RuntimeException("獲取hdfs客戶端連線異常"); } } /** * 每次執行新增有@Test註解的方法之後呼叫 */ @After public void closeRes(){ if(fileSystem!=null){ try { fileSystem.close(); } catch (IOException e) { throw new RuntimeException("關閉hdfs客戶端連線異常"); } } } /** * 上傳檔案 */ @Test public void putFileToHDFS(){ try { fileSystem.copyFromLocalFile(new Path("F:\\big-data-github\\hadoop-parent\\hadoop-order\\src\\main\\resources\\file\\order.txt"),new Path("/user/hadoop/order/input/order.txt")); } catch (IOException e) { e.printStackTrace(); System.out.println(e.getMessage()); } } /** * 建立hdfs的目錄 * 支援多級目錄 */ @Test public void mkdirAtHDFS(){ try { boolean mkdirs = fileSystem.mkdirs(new Path("/user/hadoop/order/input")); System.out.println(mkdirs); } catch (IOException e) { e.printStackTrace(); } } }
- OrderBean.java
package com.ittzg.hadoop.order; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** * @email: [email protected] * @author: ittzg * @date: 2019/7/6 16:34 */ public class OrderBean implements WritableComparable<OrderBean> { private String orderId; private String proName; private Double price; public OrderBean() { } public OrderBean(String orderId, String proName, Double price) { this.orderId = orderId; this.proName = proName; this.price = price; } public String getOrderId() { return orderId; } public void setOrderId(String orderId) { this.orderId = orderId; } public String getProName() { return proName; } public void setProName(String proName) { this.proName = proName; } public Double getPrice() { return price; } public void setPrice(Double price) { this.price = price; } @Override public String toString() { return orderId + "\t" +proName + "\t" +price; } public void write(DataOutput out) throws IOException { out.writeUTF(this.orderId); out.writeUTF(this.proName); out.writeDouble(this.price); } public void readFields(DataInput in) throws IOException { this.orderId = in.readUTF(); this.proName = in.readUTF(); this.price = in.readDouble(); } public int compareTo(OrderBean orderBean) { int result = orderBean.orderId.compareTo(this.orderId); if(result == 0){ result = orderBean.price.compareTo(this.price); } return result; } }
- OrderDrive.java
package com.ittzg.hadoop.order;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @email: [email protected]
* @author: ittzg
* @date: 2019/7/6 16:31
*/
public class OrderDrive {
public static class OrderMapper extends Mapper<LongWritable,Text,OrderBean,NullWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
System.out.println(line);
String[] split = line.split("\t");
OrderBean orderBean = new OrderBean(split[0], split[1], Double.parseDouble(split[2]));
context.write(orderBean,NullWritable.get());
}
}
public static class OrderReduce extends Reducer<OrderBean,NullWritable,OrderBean,NullWritable> {
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
public static void main(String[] args) throws Exception{
// 設定輸入輸出路徑
String input = "hdfs://hadoop-ip-101:9000/user/hadoop/order/input";
String output = "hdfs://hadoop-ip-101:9000/user/hadoop/order/output";
Configuration conf = new Configuration();
conf.set("mapreduce.app-submission.cross-platform","true");
Job job = Job.getInstance(conf);
//
job.setJar("F:\\big-data-github\\hadoop-parent\\hadoop-order\\target\\hadoop-order-1.0-SNAPSHOT.jar");
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReduce.class);
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop-ip-101:9000"),conf,"hadoop");
Path outPath = new Path(output);
if(fs.exists(outPath)){
fs.delete(outPath,true);
}
// 設定分割槽
job.setPartitionerClass(OrderPatitioner.class);
// 設定reduceTask個數
job.setNumReduceTasks(3);
FileInputFormat.addInputPath(job,new Path(input));
FileOutputFormat.setOutputPath(job,outPath);
boolean bool = job.waitForCompletion(true);
System.exit(bool?0:1);
}
}
- OrderPatitioner.java
package com.ittzg.hadoop.order;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
import java.util.HashMap;
import java.util.Map;
/**
* @email: [email protected]
* @author: ittzg
* @date: 2019/7/6 16:31
*/
public class OrderPatitioner extends Partitioner<OrderBean,NullWritable> {
volatile int count = -1; // 方便計算分割槽數,實現動態計算
volatile Map<String,Integer> map= new HashMap<String,Integer>();
public int getPartition(OrderBean orderBean, NullWritable nullWritable, int numPartitions) {
if(map.containsKey(orderBean.getOrderId())){
return map.get(orderBean.getOrderId());
}else{
count ++;
map.put(orderBean.getOrderId(),count);
return count;
}
}
}
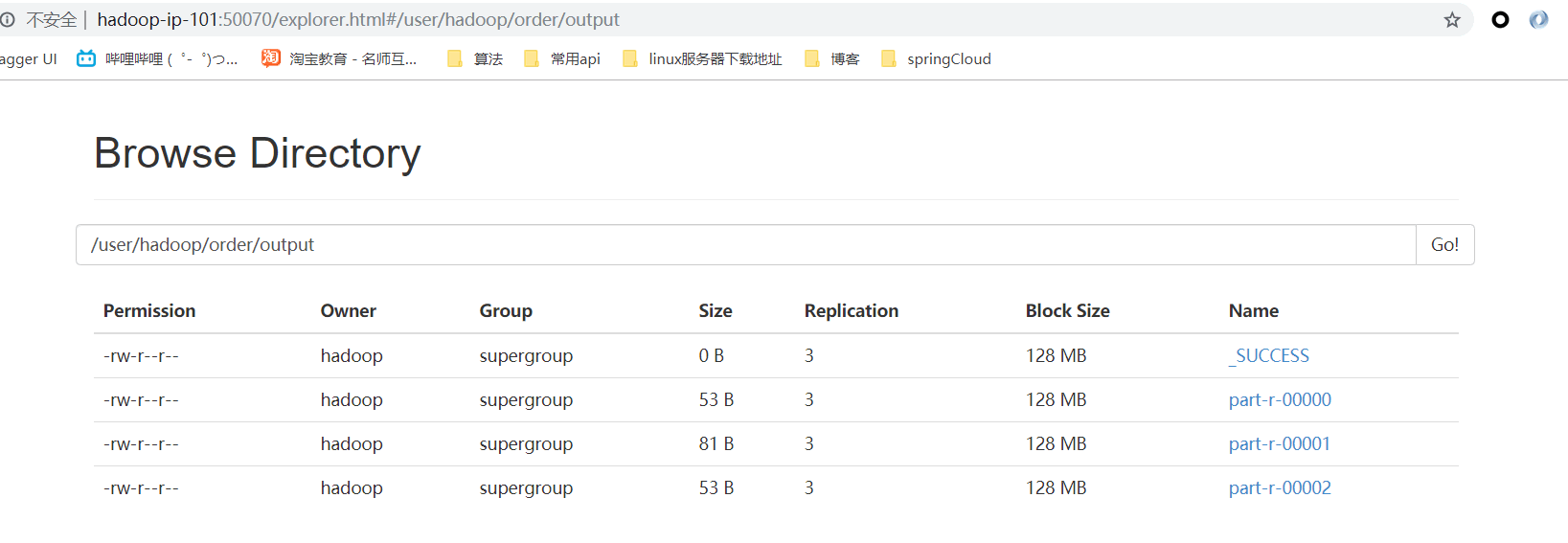
四、執行結果
- 網頁瀏覽
- 檔案內容下載瀏覽
相關推薦
大資料案例(四)——MapReduce將檔案按照訂單號分成若干個小檔案
一、需求:將檔案按照訂單號分成若干個小檔案 二、資料準備 資料準備 Order_0000001 Pdt_01 222.8 Order_0000002 Pdt_05 722.4 Order_0000001 Pdt_05 25.8 Order_0000003 Pdt_01 222.8 Order_
大資料案例(七)——MapReduce之map端表合併(Distributedcache)
一、前期準備 由於本案例是在案例六的基礎上做的優化,所以需求及資料輸入輸出請參考案例六;初次之外需要拷貝pd.txt檔案在本地電腦J盤的根目錄下以做參考 本案例只需要上傳order.txt到HDFS上即可-"/user/hadoop/order_productv2/input" 二
大資料入門(9)mapreduce計算wordcount的程式編寫
1、外部寫好的程式打Java jar 包,匯入jar sftp> put e:/wc.jar 2、建立文字進行計算 vi words.log hadoop fs -mkdir /wc hadoop fs -mkdir /wc/srcData/ 3、執行jar hadoop ja
大資料入門(四)hdfs的shell語法
1、測試hdfs檔案上傳和下載(HDFS shell) 1.0檢視幫助 hadoop fs -help <cmd> 1.1上傳 hadoop fs -put <linux上檔案> <hdfs上的路徑
大資料專案(四)————使用者畫像
1、使用者畫像概述 用來勾畫使用者(使用者背景、特徵、性格標籤、行為場景等)和聯絡使用者需求與產品設計的,旨在通過從海量使用者行為資料中煉銀挖金,儘可能全面細緻的抽出一個使用者的資訊全貌,從而幫助解決如何把資料轉為商業價值的問題。 1.1 使用者畫像資料來源
應聘——大資料研發(1)-MapReduce程式設計
MapReduce 本文參見《MapReduce Design Pattern》文中[例項程式碼] 第一章:設計模式 Reader 將輸入資料轉換成key-value的形式,通常Key為資料塊存放的地址,Value為資料。 Map 自定義
大資料案例(九)——自定義Outputformat
一、概述 要在一個mapreduce程式中根據資料的不同輸出兩類結果到不同目錄,這類靈活的輸出需求可以通過自定義outputformat來實現。 自定義outputformat, 改寫recordwriter,具體改寫輸出資料的方法write() 二、案例需求 需求:過濾輸入的log日誌中是否包含ba
大資料之電話日誌分析callLog案例(四)
一、修改kafka資料在主題中的貯存時間,預設是7天 ------------------------------------------------- [kafka/conf/server.properties] log.retention.hours=1 二、使用hive進行聚
大資料之(3)Hadoop環境MapReduce程式驗證及hdfs常用命令
一、MapReduce驗證 本地建立一個test.txt檔案 vim test.txt 輸入一些英文句子如下: Beijing is the capital of China I love Beijing I love China 上傳test.txt
sed正則經典案例(四)
sed正則經典案例sed正則經典案例(四)###修改日期格式,已知文件內容如下:原始數據:文件date.txt21/May/2017:09:29:24 +0800 22/May/2017:09:30:26 +0800 23/May/2017:09:31:56 +0800 24/May/2017:09:34:1
shell腳本案例(四)利用 free 命令精確監控RAM的使用率
mem Linux shell shell 腳本 linux 運維 arppinging 需求:利用free命令精確監控RAM的使用率具備知識:grep,free,awk,bc 腳本如下 [root@arppining scripts]# cat mem.sh #!/bin/bash
服務器編程心得(四)—— 如何將socket設置為非阻塞模式
led -h bsp wait per 設置 inux sign 也有 1. windows平臺上無論利用socket()函數還是WSASocket()函數創建的socket都是阻塞模式的: SOCKET WSAAPI socket( _In_ int af,
大資料基礎(1)zookeeper原始碼解析
五 原始碼解析 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING;}zookeeper伺服器狀態:剛啟動LOOKING,follower是FOLLOWING,leader是LEADING,observer是
大資料導論(4)——OLTP與OLAP、資料庫與資料倉庫
公司內部的資料自下而上流動,同時完成資料到資訊、知識、洞察的轉化過程。 而企業內部資料,從日常OLTP流程中產生,實時儲存進不同的資料庫中。同時定期被提取、經格式轉化、清洗和載入(ETL),以統一的格式儲存進資料倉庫,以供決策者進行OLAP處理,並將處理結果視覺化。 OLTP & OLAP 企業
大資料選擇題(二)
1.which among the following command is used to copy a directory from one node to another in HDFS? 1.rcp 2.distcp √
hadoop 大資料實戰(2)mongodb安裝
mongodb-win32-x86_64-2008plus-ssl-4.0.3.zip 1、下載地址: https://www.mongodb.com/download-center 2、配置 1.建立路徑,C:\mongodb 2.在C:\mongodb下減壓下載的zip檔案,然後在C
大資料入門(4)hdfs的shell語法
1、測試hdfs檔案上傳和下載(HDFS shell) 1.0檢視幫助 hadoop fs -help <cmd> 1.1上傳 &n
大資料入門(3)配置hadoop
1、上傳hadoop-2.4.1.tar.gz 2、解壓檔案到指定目錄(目錄:admin/app) mkdir app tar -zxvf hadoop-2.4.1.tar.gz -C /app 刪
大資料入門(2)安裝linux的jdk
1、上傳檔案到linux alt+p 進入ftp傳檔案 sftp> put E:\soft\jdk-7u71-linux-x64.tar.gz 2、建立資料夾解壓檔案(root使用者許可權) mkdir /usr/java tar -zxvf jdk-7u71-
大資料入門(1)準備linux環境
1、安裝vmware 2、新建虛擬機器 file - new virtual machine install disc image file(iso) 選擇映象檔案 選擇虛擬機器安裝路徑,方便以後copy 3、設定虛擬機器ip