
大資料案例(九)——自定義Outputformat
一、概述
要在一個mapreduce程式中根據資料的不同輸出兩類結果到不同目錄,這類靈活的輸出需求可以通過自定義outputformat來實現。
- 自定義outputformat,
- 改寫recordwriter,具體改寫輸出資料的方法write()
二、案例需求
- 需求:過濾輸入的log日誌中是否包含baidu
- (1)包含atguigu的網站輸出到j:/url/baidu_url.txt
- (2)不包含atguigu的網站輸出到j:/url/other_url.txt
- 輸入資料
=================log.txt==================== https://www.baidu.com http://news.baidu.com https://map.baidu.com http://www.google.com http://cn.bing.com http://www.sohu.com http://www.sina.com https://github.com https://my.oschina.net
- 輸出結果
=================baidu_url.txt====================
http://news.baidu.com
https://map.baidu.com
https://www.baidu.com
=================other_url.txt====================
http://cn.bing.com
http://www.google.com
http://www.sina.com
http://www.sohu.com
https://github.com
https://my.oschina.net
三、建立maven專案
- 專案結構
- 程式碼實現
- HDFSUtil.java
package com.ittzg.hadoop.outputformat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.io.IOException; import java.net.URI; /** * @email: [email protected] * @author: ittzg * @date: 2019/7/7 22:54 */ public class HDFSUtil { Configuration configuration = new Configuration(); FileSystem fileSystem = null; /** * 每次執行新增有@Test註解的方法之前呼叫 */ @Before public void init(){ configuration.set("fs.defaultFs","hadoop-ip-101:9000"); try { fileSystem = FileSystem.get(new URI("hdfs://hadoop-ip-101:9000"),configuration,"hadoop"); } catch (Exception e) { throw new RuntimeException("獲取hdfs客戶端連線異常"); } } /** * 每次執行新增有@Test註解的方法之後呼叫 */ @After public void closeRes(){ if(fileSystem!=null){ try { fileSystem.close(); } catch (IOException e) { throw new RuntimeException("關閉hdfs客戶端連線異常"); } } } /** * 上傳檔案 */ @Test public void putFileToHDFS(){ try { fileSystem.copyFromLocalFile(new Path("F:\\big-data-github\\hadoop-parent\\hadoop-outputformat\\src\\main\\resources\\file\\log.txt"),new Path("/user/hadoop/outputformat/input/log.txt")); } catch (IOException e) { e.printStackTrace(); System.out.println(e.getMessage()); } } /** * 建立hdfs的目錄 * 支援多級目錄 */ @Test public void mkdirAtHDFS(){ try { boolean mkdirs = fileSystem.mkdirs(new Path("/user/hadoop/outputformat/input")); System.out.println(mkdirs); } catch (IOException e) { e.printStackTrace(); } } } - MyRecordWriter.java
package com.ittzg.hadoop.outputformat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import java.io.IOException; /** * @email: [email protected] * @author: ittzg * @date: 2019/7/7 22:57 */ public class MyRecordWriter extends RecordWriter<Text, NullWritable> { private FSDataOutputStream baiduOut = null; private FSDataOutputStream otherOut = null; public MyRecordWriter(TaskAttemptContext job) { Configuration configuration = job.getConfiguration(); try { FileSystem fileSystem = FileSystem.get(configuration); //建立兩個輸入流 Path baiduPath = new Path("j:/url/baidu_url.txt"); Path otherPath = new Path("j:/url/other_url.txt"); baiduOut = fileSystem.create(baiduPath); otherOut = fileSystem.create(otherPath); } catch (IOException e) { e.printStackTrace(); } } public void write(Text key, NullWritable value) throws IOException, InterruptedException { if(key.toString().contains("baidu")){ baiduOut.write(key.toString().getBytes()); }else{ otherOut.write(key.toString().getBytes()); } } public void close(TaskAttemptContext context) throws IOException, InterruptedException { if(baiduOut != null){ baiduOut.close(); } if(otherOut != null){ otherOut.close(); } } } - MyFileOutputFormat.java
package com.ittzg.hadoop.outputformat; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * @email: [email protected] * @author: ittzg * @date: 2019/7/7 22:55 */ public class MyFileOutputFormat extends FileOutputFormat<Text,NullWritable> { public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException { return new MyRecordWriter(job); } } - MyFileOutputFormatDriver.java
package com.ittzg.hadoop.outputformat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.BytesWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat; import java.io.IOException; import java.net.URI; /** * @email: [email protected] * @author: ittzg * @date: 2019/7/7 23:08 */ public class MyFileOutputFormatDriver { static class MyMapper extends Mapper<LongWritable,Text,Text,NullWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { context.write(value,NullWritable.get()); } } static class MyReduce extends Reducer<Text,NullWritable,Text,NullWritable> { Text urlFormat = new Text(); @Override protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { urlFormat.set(key.toString()+"\t\n"); context.write(urlFormat,NullWritable.get()); } } public static void main(String[] args) throws Exception { String input = "hdfs://hadoop-ip-101:9000/user/hadoop/outputformat/input"; String output = "hdfs://hadoop-ip-101:9000/user/hadoop/outputformat/output"; Configuration conf = new Configuration(); conf.set("mapreduce.app-submission.cross-platform","true"); Job job = Job.getInstance(conf); job.setJarByClass(MyFileOutputFormatDriver.class); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReduce.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); FileSystem fs = FileSystem.get(new URI("hdfs://hadoop-ip-101:9000"),conf,"hadoop"); Path outPath = new Path(output); if(fs.exists(outPath)){ fs.delete(outPath,true); } // 將自定義的輸出格式元件設定到job中 job.setOutputFormatClass(MyFileOutputFormat.class); FileInputFormat.setInputPaths(job, new Path(input)); // 雖然我們自定義了outputformat,但是因為我們的outputformat繼承自fileoutputformat // 而fileoutputformat要輸出一個_SUCCESS檔案,所以,在這還得指定一個輸出目錄 FileOutputFormat.setOutputPath(job, outPath); boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
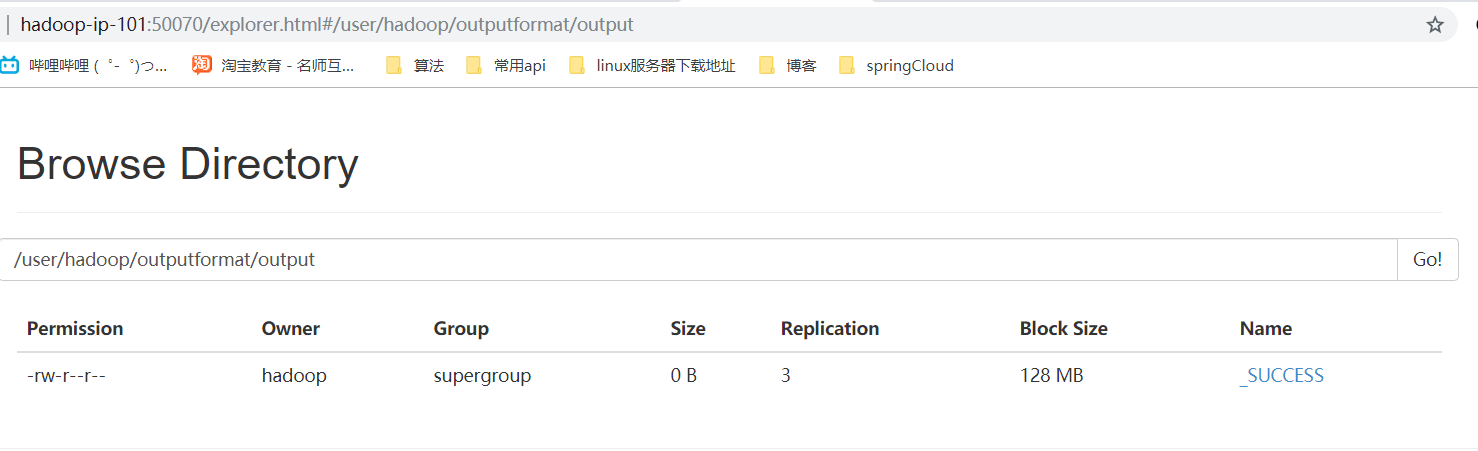
四、執行結果
- 網頁瀏覽及本地檔案瀏覽
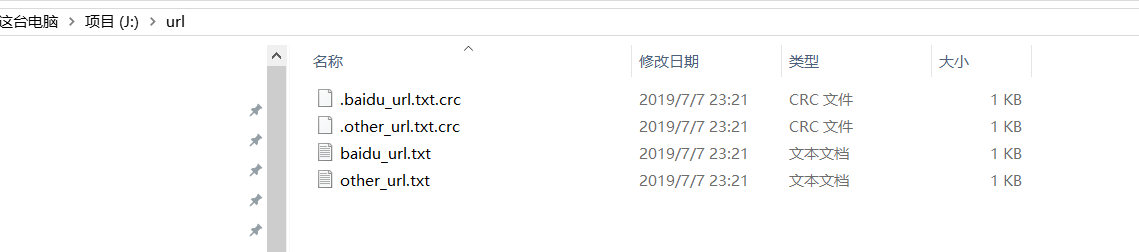
- 檔案內容下載瀏覽

相關推薦
大資料案例(九)——自定義Outputformat
一、概述 要在一個mapreduce程式中根據資料的不同輸出兩類結果到不同目錄,這類靈活的輸出需求可以通過自定義outputformat來實現。 自定義outputformat, 改寫recordwriter,具體改寫輸出資料的方法write() 二、案例需求 需求:過濾輸入的log日誌中是否包含ba
MySQL(九)自定義函式
1.建立自定義函式 語法格式: create function function_name([引數][型別]) returns type [characteristics…] 函式體 returns type :指定返回值的資料型別 characteristi
Linux之大資料技術(九):修改ip地址
大資料技術之修改ip地址 5.2.3 修改IP地址 1)修改IP地址 [[email protected] 桌面]#vim /etc/sysconfig/network-scripts/ifcfg-eth0 以下標紅的項必須修改,有值的按照下面的值修
SpringMVC系列(九)自定義檢視、重定向、轉發
一、自定義檢視 1. 自定義一個檢視HelloView.java,使用@Component註解交給Spring IOC容器處理 1 package com.study.springmvc.views; 2 3 import java.util.Date; 4 i
大資料案例(四)——MapReduce將檔案按照訂單號分成若干個小檔案
一、需求:將檔案按照訂單號分成若干個小檔案 二、資料準備 資料準備 Order_0000001 Pdt_01 222.8 Order_0000002 Pdt_05 722.4 Order_0000001 Pdt_05 25.8 Order_0000003 Pdt_01 222.8 Order_
大資料案例(七)——MapReduce之map端表合併(Distributedcache)
一、前期準備 由於本案例是在案例六的基礎上做的優化,所以需求及資料輸入輸出請參考案例六;初次之外需要拷貝pd.txt檔案在本地電腦J盤的根目錄下以做參考 本案例只需要上傳order.txt到HDFS上即可-"/user/hadoop/order_productv2/input" 二
大資料入門(11)mr自定義分組和切片劃分
public class AreaPartitioner<KEY, VALUE> extends Partitioner<KEY, VALUE>{ private static HashMap<String,Integer> areaMa
Centos6.10下Open-falcon學習記錄(一)——自定義資料採集、歷史查詢、程序監控
記錄了學習過程,官方文件地址http://book.open-falcon.org/zh_0_2/usage/getting-started.html 另外還看了Open-falcon作者的寫的設計理念的文,見open-falcon編寫的整個腦洞歷程 1 自定義資料採集 自定義的資料要求
PHP (Yii2) 自定義業務異常類(可支援返回任意自己想要的型別資料)
public function beforeAction($action) { return parent::beforeAction($action); } public function runAction($id, $params = []) {
關於資料序列化(4)自定義序列化的實現,支援常用集合框架
下面的示例很好的揭示瞭如何實現自定義序列化的方法。 支援byte, byte[], boolean, boolean[], int, int[], long, long[] ,double ,double[], String, String[], 以及Enum, List,Map兩種包
PyTorch學習之路(level2)——自定義資料讀取
在上一篇部落格PyTorch學習之路(level1)——訓練一個影象分類模型中介紹瞭如何用PyTorch訓練一個影象分類模型,建議先看懂那篇部落格後再看這篇部落格。在那份程式碼中,採用torchvision.datasets.ImageFolder這個介面來讀取
(12)自定義資料流(實戰Docker事件推送的REST API)——響應式Spring的道法術器
2.2 自定義資料流 這一小節介紹如何通過定義相應的事件(onNext、onError和onComplete) 建立一個 Flux 或 Mono。Reactor提供了generate、create、push和handle等方法,所有這些方法都使用 si
AngularJs學習筆記(4)——自定義指令
ref 告訴 ack 生命周期 .com bsp ctrl 參數變量 ng- 對指令的第一印象:它是一個自定義標簽! 先來看一個簡單的指令: <!doctype html> <html ng-app="myApp"> <head>
微信公眾平臺開發教程(五)自定義菜單
打開鏈接 delete toolbar 推送 優化 pcl reader 接口查詢 robot 應大家強烈要求,將自定義菜單功能課程提前。 一、概述: 如果只有輸入框,可能太簡單,感覺像命令行。自定義菜單,給我們提供了很大的靈活性,更符合用戶的操作習慣。在一個小小的微信對話
JS基礎(五)自定義函數
調用函數 pre 基礎 clas 自定義 語句 ... 全局 blog 作用:是為了讓重復使用的語句,方便進行調用。 定義格式: function 自定義函數名 (參數1, 參數2,...) { 執行的語句 } 函數的封裝:把語句放到函數中去的過程。 參數:通過
WPF自定義控件(四)の自定義控件
自己 setvalue prop 一個 自己的 支持 property get element 在實際工作中,WPF提供的控件並不能完全滿足不同的設計需求。這時,需要我們設計自定義控件。 這裏LZ總結一些自己的思路,特性如下: Coupling UITemplate Be
Django 表單(中下)- 自定義鉤子進行數據驗證
form hook 在前面的例子裏面 http://beanxyz.blog.51cto.com/5570417/1963702,已經演示了form可以自動地對正則進行合法的判斷,如果不合法,會直接顯示錯誤信息。但是這個功能並不完善,比如說一個數據可能正則判斷合法了,但是不符合唯一性的判斷,那麽怎麽處
(4)自定義數據結構初探
lang 結構 十分 類型 是把 數據 庫類 結束 基本 從最基本的層面理解,數據結構是把一組相關的數據元素組織起來然後使用她們的策略和方法。 C++運行用戶以類的形式自定義數據類型,而庫類型是語言自身定義的,類在C++中十分重要!盡管sales_item很簡單,但要想給出
(三)自定義Realm
ssi 定義 try time public getname tid vax getc 引入依賴 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/
weex 項目開發(五)自定義 過濾函數 和 混合 及 自定義 Header 組件
定義 blog weex top ber slice ear notice earch 1.自定義 過濾函數 src / filters / index.js /** * 自定義 過濾函數 */ export function host (url) { if (