
談談lucene倒排索引的儲存方式(二)
阿新 • • 發佈:2019-07-11
在談談lucene倒排索引的儲存方式(一)中只說明瞭倒排索引位置相關資訊的儲存,並沒有詳細說明如果需要對位置資訊進行隨機訪問,那麼它的索引該如何設計。lucene採用的是多級跳躍連結串列的方式,先說說跳躍連結串列基本思想(其實在前面文中也提過),假設給定一堆排過序的數字,並且資料量很大以至於在記憶體中放不下,如果要快速隨機訪問其中的某個數值,一種方法是對這些數字每隔一定的條數如1000條就記錄相應的數值以及對應的檔案指標,然後把這些數值以及對應的檔案指標載入到記憶體中採用二分查詢法找到欲查詢數值所在資料塊的起始地址,然後將1000條記錄依次遍歷比較或者載入到記憶體中採用二分查詢都可以,這些數值和檔案指標又叫一級跳躍表。
如果說一級跳躍表的資料量依然很大,那麼又要在此基礎上再建立一層跳躍表,依此類推就會有多級跳躍表了。值得一提的是級數並不是越多越好,因為層級越多,查詢的次數也越多,lucene預設最大層級為10。
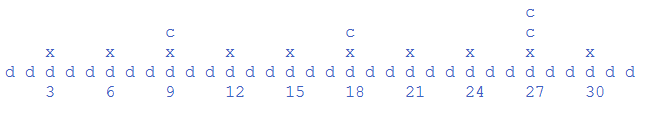
上圖是lucene官方給出的示圖(一個詞代表的倒排位置索引),d代表文件,x代表每隔128個文件進行壓縮的檔案指標也是第一層級的索引記錄了相應的文件ID和所在檔案的指標,c分別為第二層級和第三層級。這樣感覺在程式碼實現上較複雜的索引結構確在lucene實現的時候顯得非常討巧,因為總的層級可以預先算出來,然後可以邊寫邊計算出文件所在層級。有興趣滴還