
Lucene倒排索引簡述 之索引表
一、前言
倒排索引是全文檢索的根基,理解了倒排索引之後才能算是入門了全文檢索領域。倒排索引的的概念很簡單,也很好理解。但如你知道在全文檢索領域Lucene可謂是獨領風騷。所以你真的瞭解Lucene的倒排了嗎?Lucene是如何實現這個結構的呢?
倒排索引如此重要,深入理解索引結構顯然是非常有益的,對於理解Lucene的索引和搜尋流程都非常關鍵,進而可以參與自定義搜尋統計的計算函式擴充套件開發。
本文我們將對Lucene的倒排索引的實現原理和技術細節展開具體的研讀和剖析。
二、理論
在學術上,倒排索引結構非常簡明,非常好理解。如下
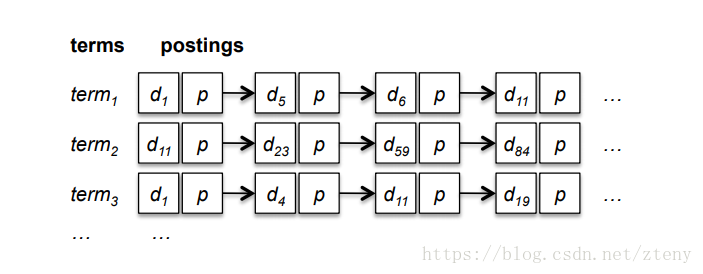
也許你已經很瞭解倒排索引了,下面這張圖你也已經看過很多次了。本文將從你熟悉的部分開始,一步步深入去扣這張圖的一個個細節。這裡有二部分內容對應分別稱之為:
- 索引,索引詞表。倒排索引並不需要掃描整個文件集,而是對文件進行預處理,識別出文檔集中每個詞。
- 倒排表,倒排表中的每一個條目也可以包含詞在文件中的位置資訊(如詞位置、句子、段落),這樣的結構有利於實現鄰近搜尋。詞頻和權重資訊,用於文件的相關性計算。
倒排索引由兩部分組成,所有獨立的詞列表稱為索引,詞對應的一系列表統稱為倒排表。
—— 來自《資訊檢索》
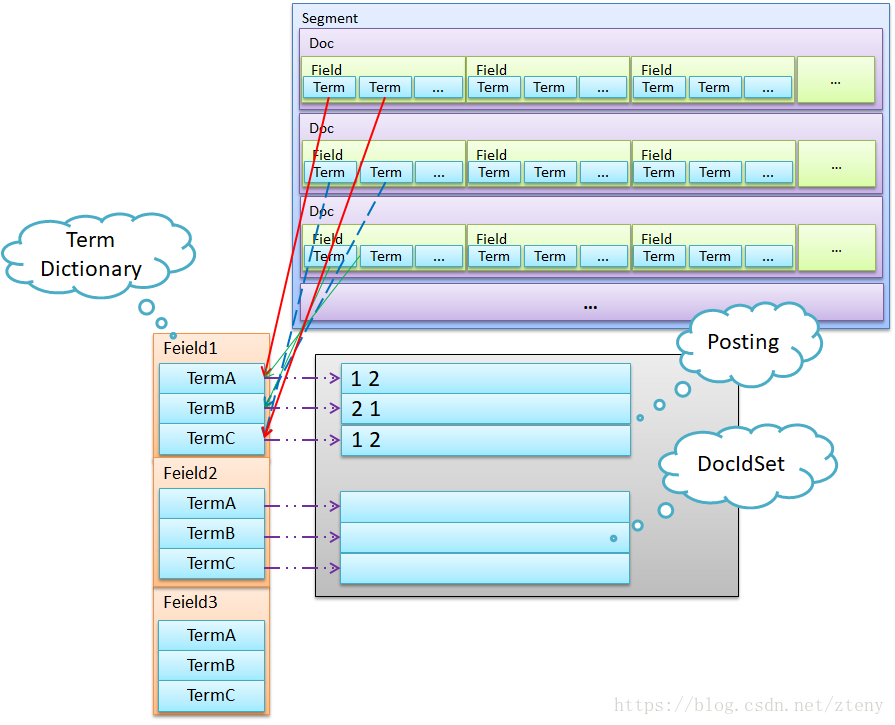
如圖,整個倒排索引分兩部分,左邊是Term Dictionary,我們就叫Dictionary吧;右邊是Postings List。
- 索引表,叫
Terms Dictionary,是由於一系列的Term組成的。 - 倒排表,稱
Postings List,即是由所有的Term對應的Postings組成的。
實際上Lucene所用的資訊資訊檢索方面的術語基本跟Information Retrieval(《資訊檢索》原版)保持一致。比如Term、Dictionary、Postings等。
首先,有必須解釋一下,每個Segment中的每個欄位(Field)都有這麼一個結構,且相互獨立。其次,她是不可變的,即是不能新增和更改。至於不可變的原因很多,簡單說有兩方面:一方面是更新對磁碟來說不夠友好;另一方面是寫效能的影響,同時還引發各種併發問題。
我們先這麼來想這個問題,如果用HashMap來實現這個結構,非常貼近這個結構了。這個結構應該是這樣的,Map<String, List<Integer>>
這就是一個hello world版的倒排索引的實現了。
三、Lucene的實現
全文搜尋引擎通常是需要儲存大量的文字,不僅是Postings可能會是非常巨大,同樣Dictionary的大小極可能也是非常龐大。因此上面說的實現方式是完全不可能的,真正的搜尋引擎的倒排索引實現都極其複雜,因為它直接影響了搜尋效能和功能。
實際上Lucene的索引實現也是幾經升級優化,每個版本都有或大或小的差異,這裡只看Lucene6.x/7.x的實現。
Lucene的實現非常高階,它的關鍵特性是能夠將整個排索引系列化儲存在磁碟上,同時它必須是能夠滿足快速讀寫的需求。Lucene為了極致的搜尋體驗,引用多種資料結構和演算法。倒排索引變得高效又複雜的同樣,給我們帶來一次研讀和剖析的機會。
四、Lucene索引檔案初印象
我們知道Lucene將索引檔案拆分為了多個檔案,這裡我們僅討論倒排索引部分。Lucene把用於儲存Term的索引檔案叫Terms Index,它的字尾是.tip;把Postings資訊分別儲存在.doc、.pay、.pox,分別記錄Postings的DocId資訊和Term的詞頻、Payload資訊、pox是記錄位置資訊。Terms Dictionary的檔案字尾稱為.tim,它是Term與Postings的關係紐帶,儲存了Term和其對應的Postings檔案指標。
總體來說,通過Terms Index(.tip)能夠快速地在Terms Dictionary(.tim)中找到你的想要的Term,以及它對應的Postings檔案指標。當然還有Term在Segment作用域上的統計資訊。
postings: 實際上Postings包含的東西並不僅僅是DocIDs(我們通常把這一個有序文件編號系列叫DocIDs),它還包括文件編號、以及詞頻、Term在文件中的位置資訊、還有Payload資料。
所以關於倒排索引至少涉及5個檔案,當然這裡不含括(Norms資訊和TermVector資訊)。
五、 什麼是Terms Index
下圖我們貼張來自網路的圖,我覺得這圖非常好。

即是圖中.tip部分,Terms Index實際上一個或者多個FST組成的,Segment上每個欄位都有自己的一個FST(FSTIndex)記錄在.tip上。所以圖中FSTIndex的個數即是Segment擁有欄位的個數。另外圖中為了方便我們理解把FST畫成Trie結構,然後其葉子節點又指向了tim的Block的,這實際上是用一種叫Burst-Trie的資料結構。
1. Burst-Trie
.tip看起來是像一棵Trie,所以整張圖表現出來就是論文上的Burst-Trie結構了。上面一棵Trie,Trie的葉子節點是Container(即是Lucene中的Block)。非常簡單這就是Paper上描述的Burst-Trie的結構,然而Lucene的實現上跟這個還是有一些差異。

來自Burst-Trie論文上的一張圖
Burst-Trie,具體能可以拜讀一下論文的原文,這裡只做簡單描述。Burst-Trie可以認為是Trie的一種變種,它主要是將字尾進行了壓縮,降低了Trie的高度,從而獲取更好查詢效能。

由於我們還沒有開始介紹FST,然後先把Lucene工程上的實現理解成上圖結構。
Burst-Trie在Lucene應用在那裡呢?
顯然,Lucene是採用Burst-Trie的思想,但在實現上並不是特別一致。甚至可以說出入還比較大,Lucene的Burst-Trie拆成兩部分。如果一定把它們對應起來的話,我認為Burst-Trie的AccessTree的實現是FST,在.tip裡;Container的實現是Block,在.tim裡。Burst-Trie論文上提到Container是開放性結構,可能是Binary-Tree,也可以是List。Lucene的block是陣列,準確的說,就是把一系列的Block系列化寫到檔案上。這裡好像並沒有特殊的處理。
2. FST
在Lucene,Terms Dictionary被儲存在.tim檔案上。當一個Segment的文件數量越來越多的同時Dictionary的詞彙也會越來越多,那查詢效率必然也會慢慢變低。如果有一個很好的結構也為Dictionary建構一個索引,將Dictionary的索引進一步壓縮,這就是後來的Terms Index(.tii)。這是在早期的版本中使用的,到Lucene4.0做一次重構和升級,同時改名為.tip。

FST:Finite-State-Transducer,結構上是圖。我們知道把一堆字串放一起並左對齊,把它們的同共字首進行壓縮就會變成Burst-Trie。如果把字尾變成一個一個節點,那麼它就是Trie結構了。如果將字尾也進行壓縮的話,那你就能發現他更變成一張圖結構了。
那麼我們易知FST是壓縮字典樹字尾的圖結構,她擁有Trie高效搜尋能力,同時還非常小。這樣的話我們的搜尋時,能把整個FST載入到記憶體。
那實際上FST的結構實際相當複雜,這裡我們簡單的理解為一個高效的K-V結構,而且空間佔用率更高。也就是FST能提供類似Map的功能,這裡可以先這麼理解,實際上它別的重大功能。
反正,此時你只需要知道FST是一種非常厲害的資料結構就可以了。甚至為了能夠更好的理解它在倒排索引結構和Burst-Trie結構上功能,你把它錯誤當成是Trie都沒有問題的呢。這裡我們先不做太詳細的介紹了,有機會單獨拎出來講。
此外,我還想多說一句Lucene到底把什麼東西放在FST裡了呢? 關於FST裡面裝了什麼東西,如果你已經瞭解FST在Lucene中充當的角色和作用的話,我想你應該會誤以為是拿Dictionary中所有Term來構建FST的。即是通過FST是可以找具體的Term的位置,或者通過FST可以切切的知道Terms是否存在。
然而,事實並非如此。 FST即不能知道某個Term在Dictionary(.tim)檔案上具體的位置,也不能僅通過FST就能切切的知道Term是否真實存在。它只能告訴你,查詢的Term可能在某個或者幾個Block上,到底有沒有、存不存在FST並不完全知情,還需要通過讀取Block的內容才能確定。因為FST是通過Dictionary的每個Block的字首構成,所以通過FST只可以直接找到這個Block在.tim檔案上具體的File Pointer,並無法直接找到Terms。
- FST是欄位級別的,在Segment上每個欄位有且僅有一張FST圖。
- FST最終只能指向一個Block的起始位置,並不能指向具體的一個Term。
下面會詳細的介紹Dictionary的檔案結構,這裡先提一下。每個Block都有字首的,Block的每個Term實際不記錄共同字首的。只有通過Block的共同的字首,這是整個Block的所有Term共有的,所以每個Term僅需要記錄字尾可以通過計算得到,這可以減少在Block內查詢Term時的字串比較的長度。這也是Burst-Trie主要思想。
簡單理解的話,你可以把她當成一個高階的BloomFilter,我們BloomFilter是有一定的錯誤率的;同時BloomFilter是通過HashCode實現的,只能用她來測試是否存在,並無法快速定位。在FST中,並無錯誤率且能快速定位。但是BloomFilter有更高的效能。
說了這麼一大半天,Terms Index到底帶來哪些實質性的功能呢? Terms Index是Dictionary的索引,它採用 了FST結構。上面已經提及了,FST提供兩個基本功能分別是:
- 快速試錯,即是在FST上找不到可以直接跳出不需要遍歷整個Dictionary。類似於BloomFilter的作用。
- 快速定位Block的位置,通過FST是可以直接計算出Block的在檔案中位置(offset,FP)。實現了HashMap的功能。
相當於Terms Index也擁有了上述兩大能力。
上面已經介紹了FST的一種功能,此外,FST還有別的功能,因為FST也是Automaton,自動狀態機。這是正則表示式的一種實現方式,所以FST能提供正則表示式的能力。通過FST能夠極大的提高近似查詢的效能,包括萬用字元查詢、SpanQuery、PrefixQuery等,甚至是近期社群現在做的正則表示式查詢。
六、什麼是Terms Dictionary
前面我們已經介紹了Terms Dictionary的索引,Terms Index。已經頻頻提到的Terms Dictionary到底是個什麼東西呢?是的,Terms Dictionary是Segment的字典,索引表。它能夠讓你知道你的查詢的這個Term的統計資訊,如tf-idf中df(doc_freq)和Total Term Frequence(Term在整個Segment出現頻率);還能讓你知道Postings的元資料,這裡是指Term的docids、tf以及offset等資訊在Postings各個檔案的檔案指標FP。
Block並不記錄這個Block的起始和結束的範圍,所以當FST最終指向多個Block時,就會退化線性搜尋。那什麼時候會出現FST最終指向多個Block呢?最簡單的一種情況是,你超過48個的Term,且出現首字母相同的term的個數不超過25個。這種情況下由於沒有每個Block都沒有共同字首,所以構建出來的FST只有一個結束節點記錄每個Block的檔案定址的偏移增量。
Lucene規定,每個Block的大小在25-48範圍內。
說這麼多,還是覺得太抽象了,先來看一下.tim檔案結構示意圖。

主要是大兩部分資訊,1. 是Block資訊,包含所有Term的詳情;2. 是Field的自有屬性和統計資訊。接下來我們將展開來介紹這兩部分內容。
1. Block資訊 – NodeBlock
在整個.tim檔案上,我覺得比較複雜、需要拎出來講的只有NodeBlock。即是Block是什麼東西,又是怎麼被構建的呢?實際上這兩部分程式碼我讀得起來是感覺挺晦澀的,每次讀都有會不同的疑問,所以在閱讀的過程中一直在自問為什麼,是什麼東西。我覺得這也是一種閱讀程式碼比較的方式方法吧。
我們前面所有說的Block即是NodeBlock的一個Entry。
由上圖可以知道,Block中有兩種OuterNode和InnerNode。這裡我想引用程式碼上兩個類名來輔助我們接下來的剖析:PendingTerm/PendingBlock,我們暫且把它們叫作待寫的Term和子Block的指標吧。
NodeBlock從構建邏輯上來講是它是樹型結構,所以它由葉子節點和非葉子節點兩種節點組成。葉子節點就叫OutterNode,非葉子節點就叫InnerNode。一個Block可能含有一堆的Term(PendingTerm)和PendingBlock(當它是非葉子節點時),實際上PendingBlock也是不可能出現在葉子節點上的。如果是PendingBlock,那麼這個Entry只記錄兩個資訊:字尾(這個Block的共同字尾)以及子Block的檔案指標,此時就不必再記上所說的統計資訊和postings資訊了。

如圖所示,一個Block記錄的資訊非常多,首先它會告訴你這個Block的型別和Entry的條數,然後依次寫入這個Block擁有的所有Entry。

這裡每個Entry含有後綴、統計資訊(對應為前面據說的權重,它含有ttf和df)、Postings的位置資訊(這就是反覆提及postings相關的檔案指標,postings是拆分多檔案儲存的)。
關於Postings更多細節,放到下個節來討論。
2. Field資訊 – FieldMetadata
相對來說FieldMetadata組織結構就相對簡單很多了,就是純粹線性寫入便是了。但是Field資訊記錄的內容實際上也是挺多的,包括欄位本身的屬性,如欄位編號、Terms的個數、最大和最小的Terms;此外還記錄了Segment級別的一些統計資訊,包括tdf、擁有該欄位的文件總數(如果文件沒有這欄位,或者欄位為空就不計了)。
- RootCode實際上指向該欄位第一個Block的檔案指標。
- LongsSize這個名字有點隱晦,它是說該欄位的欄位儲存哪些Postings資訊。因為我們是可以指定Postings儲存或者不儲存諸如位置資訊和Payload資訊的,存與不存將被表現在這裡了。
從搜尋流程上,Lucene先讀到FieldMetadata的資訊,然後判斷Query上Terms是否落在這裡欄位的MinTerm和MaxTerm之間。如果不在的話,完全不需要去讀NodeBlock的。MinTerm和MaxTerm可以有效的避免讀取不必要的.tip。
七、結束語
到這裡關於倒排索引結構中第一部分當就全部讀完了吧,更多有意思的小細節可以去扣的。由於篇幅的原因,就到這裡了吧。
總結一下,我們先從Information Retrieve開始瞭解學術上倒排索引結構,接著我們又對Luecne實現進行深入剖析。Lucene對索引詞表也做了索引(叫Terms Index,檔案字尾是.tip),索引詞表的索引採用Finite-State Transducer這種資料結構。由於這種結構佔用空間極小,所以它完成可以被載入到記憶體加速Terms Dictionary的查詢過程。
然後又看Terms Dictionary,Terms Dictionary以Terms Index共同構成與Burst-Trie類似的資料結構,Terms Dictionary含兩部分資訊。1. NodeBlock記錄Dictionary的所有Terms;2. FieldMetadata儲存了FieldInfos資訊和Segment的統計資訊。
關於倒排索引還有Postings List,這部分內容將留到下篇《Lucene倒排索引簡述 之倒排表》來介紹。