
機器學習在高德起點抓路中的應用實踐
導讀:高德地圖作為中國領先的出行領域解決方案提供商,導航是其核心使用者場景。路線規劃作為導航的前提,是根據起點、終點以及路徑策略設定,為使用者量身定製出行方案。
起點抓路,作為路線規劃的初始必備環節,其準確率對於路線規劃質量及使用者體驗至關重要。本文將介紹高德地圖針對起點抓路準確率的提升,尤其是在引入機器學習演算法模型方面所進行的一些探索與實踐。
什麼是起點抓路
首先,我們來簡單介紹一下什麼是起點抓路。起點抓路是指標對使用者發起的路線規劃請求,通過獲取到的使用者定位資訊,將其起點位置繫結至實際所在的道路。
從高德地圖App可以看到,使用者進行路線規劃時選擇起點的方式有以下三種:
1.手動選點(使用者在地圖上手動標註所處位置)。
2.POI選點(Point of Interest,興趣點,在地理資訊系統中可以是商鋪、小區、公交站等地理位置標註資訊)。

3.自動定位(通過GPS、基站或WiFi等方式自動定位所在位置)。

三種方式中,使用者手動選點及POI選點這兩種方式的位置資訊相對準確,起點抓路準確率相對較高。
而自動定位起點的方式,由於受GPS、基站、網路定位精度影響,定位座標易發生漂移,定位裝置抓取的位置與使用者實際所處道路可能相差幾米、幾十米甚至幾百米。如何在有限資訊下,將使用者準確定位到真實所在道路,就是我們所要解決的主要問題。
為什麼要引入機器學習
引入機器學習之前,起點抓路對候選道路的排序採用了人工規則。核心思路是:以距離為主要特徵,結合角度、速度等特徵,加權計算得分,進而影響排序,人工規則中所涉及到的權重及閾值等是經綜合實戰經驗人工拍定而成。
隨著高德地圖業務的不斷增長,規劃請求數量及場景的增多,人工規則的侷限性越來越明顯,具體表現在以下方面:
- 即使包含了眾多經驗在內,人工設定的閾值、權重仍不夠完善,易發生偏移或存在盲區是不可改變的事實。
- 策略維護方面,面對上游資料的更新,新特徵無法用最快速度加入到策略中。
- 人工規則拍定對經驗要求較高,對於人員的更迭,很難做出最敏捷的響應。
在大資料和人工智慧時代,利用資料的力量代替部分人力工作,實現流程的自動化,提高工作效率是必然趨勢。
因此,基於起點抓路人工規則的現狀及問題,我們引入了機器學習模型,自動學習特徵與抓路結果之間的關係。一方面,擁有大量規劃及實走資料,對於機器學習模型的訓練資料獲取,高德有天然優勢;另一方面,機器學習模型有更強的表達力,能夠學習到特徵之間的複雜關係,提高抓路準確率。
如何實現機器學習化
迴歸機器學習本身,下面來介紹我們如何建立起點抓路機器學習模型。一般來講,運用機器學習方法解決實際問題分為以下幾個方面:
- 目標問題的定義
- 資料獲取與特徵工程
- 模型選擇
- 模型訓練及效果評估
1.目標問題定義
在引入機器學習模型之前,需要將待解決問題進行數學抽象。
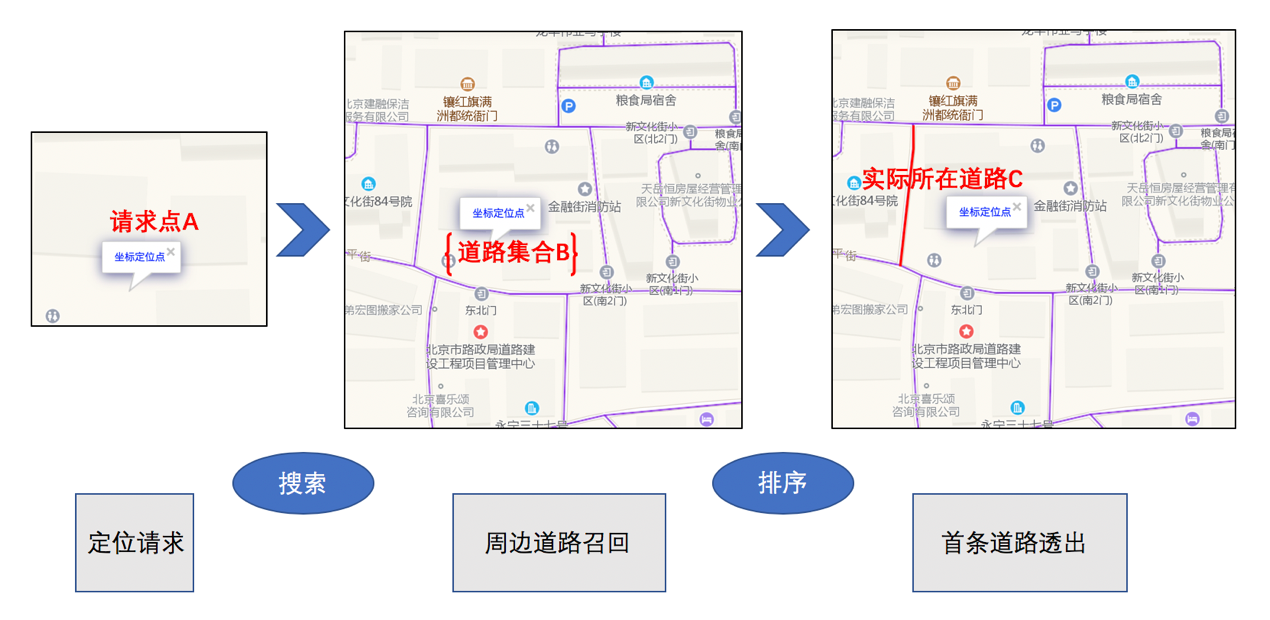
分析起點抓路問題,如上圖所示,我們可以看到當用戶在A點發起路線規劃請求時,其定位位置A所對應的周邊道路是一個獨立的集合B,而使用者所在的實際道路是這個集合中的唯一一個元素C。
這樣,起點抓路問題轉化為在定位點周邊道路集合中選出一條最有可能是使用者實際所在的道路。
整個過程類似搜尋排序,因此,我們在制定建模方案時也採用了搜尋排序的方式。
- 提取使用者路線規劃請求中的定位資訊A。
- 對定位點周邊一定範圍內的道路進行召回,組成備選集合B。
- 對備選道路進行排序,最終排在首條的備選道路為模型輸出結果,即使用者實際所在道路C。
最終,我們將起點抓路定義為一個有監督的搜尋排序問題。明確了需要達到的目標,我們開始考慮資料獲取及特徵工程問題。
2.資料獲取與特徵工程
業界常言,資料和特徵決定了機器學習的上限,而模型和演算法只是逼近這個上限。可見對於專案最終效果,資料和特徵至關重要。
訓練起點抓路機器學習模型,我們需要從原始資料中獲取兩類資料:
- 真值資料,即使用者傳送路線規劃請求時實際所處道路資訊。
機器學習應用於起點抓路專案,第一個問題就是真值資料的獲取。使用者在某個位置A發起路線規劃請求,由於定位精度限制,我們無法確認其實際所在位置,但如果使用者在發起規劃請求附近有實走資訊,可以將實走資訊匹配到路網生成一條運動軌跡,通過這條軌跡我們就可以獲取到請求定位點所處的實際道路。
我們針對高德地圖的導航請求資料進行相關挖掘,將使用者實走與路線規劃資訊相結合,得到了請求與真值一一對映的資料集。
- 特徵資料
在起點抓路模型中,我們提取了三大類特徵用於構建樣本集,分別是定位點相關特徵、道路自身特徵以及定位點與道路之間的組合特徵。
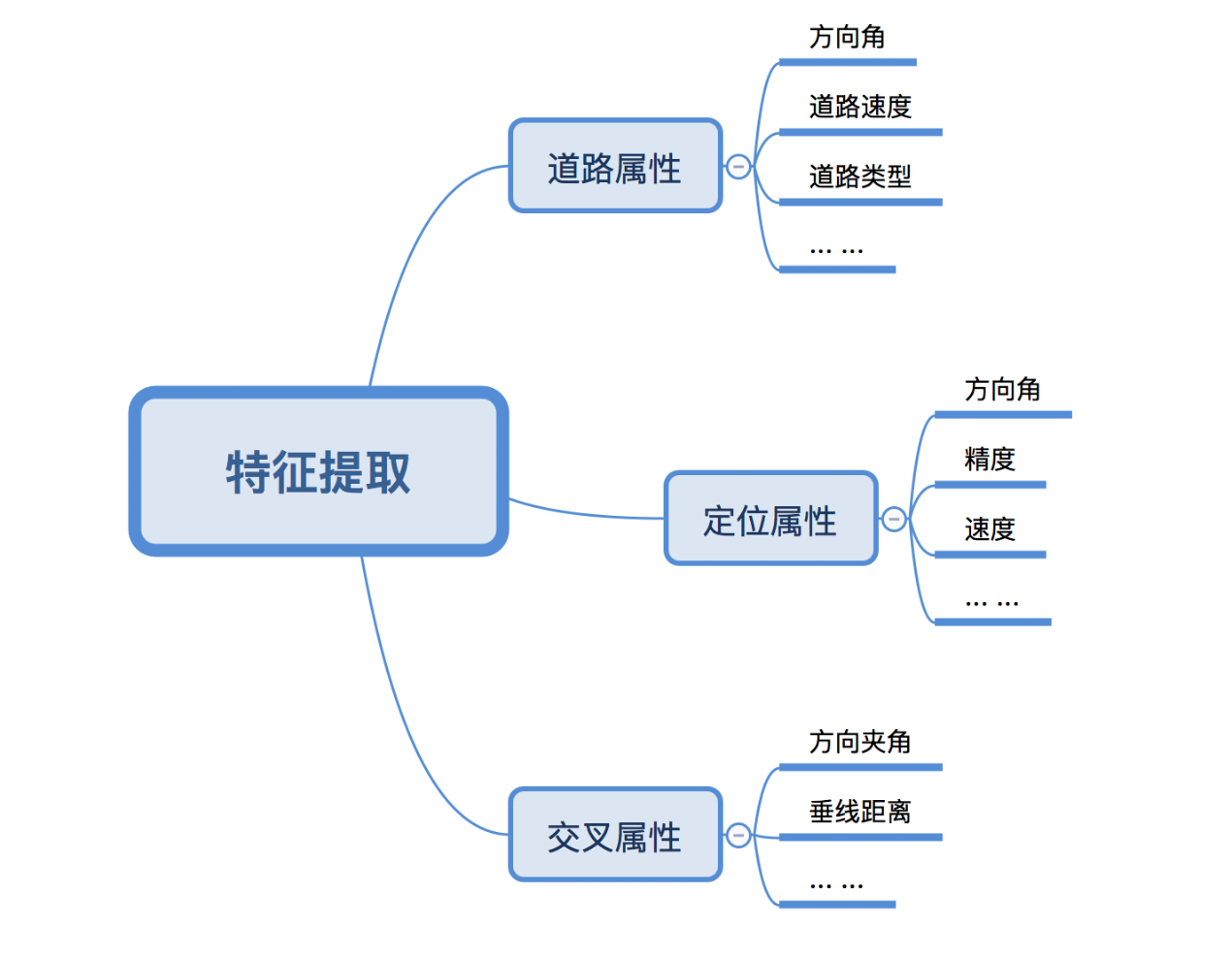
特徵處理是特徵工程的核心部分,不同專案在進行特徵預處理時會有不同,需要根據實際業務場景進行特殊化處理,往往依賴於專業領域經驗。起點抓路專案中,我們針對定位特徵進行了樣本去重、異常值處理、錯誤值修正及對映等資料清洗工作。
3.模型選擇
在目標問題定義中,我們將起點抓路剖析為搜尋排序問題,而機器學習的ranking技術,主要包括point-wise、pair-wise、list-wise三大類。
根據起點抓路業務特點,我們採用了list-wise,其learning to rank框架具有以下特徵:
- 輸入資訊是同一路線規劃請求對應的所有道路構成的多特徵向量(即一個query)。
- 輸出資訊是對應請求(即同一query)特徵向量的打分序列。
- 對於打分函式,我們採用了樹模型。
我們選擇NDCG(Normalized Discounted Cumulative Gain 歸一化累積折算資訊增益值)作為模型評價指標,NDCG是一種綜合考慮模型排序結果和真實序列之間關係的指標,也是常用的衡量排序結果的指標。
4.模型訓練及效果評估
我們抽取了一定時間段內的請求資訊,按照步驟2中描述的方式獲取到對應真值及特徵資料,打標構建了樣本集,將其劃分為訓練集與測試集,訓練模型並檢視結果是否符合預期。
評估模型效果,我們將測試集的請求分別用人工規則及機器學習模型進行抓路,並分別與真值進行對比,統計準確率。
對比結果,針對隨機抽取的請求,模型與人工規則抓路結果差異率為10%,這10%的差異群體中,模型抓路準確率比人工規則提升40%,效果顯著。
寫在最後
以上我們介紹了大資料和機器學習在起點抓路方面的一些應用,專案的成功上線也驗證了機器學習在提升準確率、優化流程等方面可以發揮重要作用。
未來,我們希望能夠將現有模型場景繼續細化,尋找新的收益點,從資料和模型兩個角度共同探索,持續優化機器學習抓路效果。

關注高德技術,找到更多出行技術領域專業內容