
PostgreSQL 視窗函式 ( Window Functions ) 如何使用?
阿新 • • 發佈:2019-07-17
一、為什麼要有視窗函式
我們直接用例子來說明,這裡有一張學生考試成績表testScore:
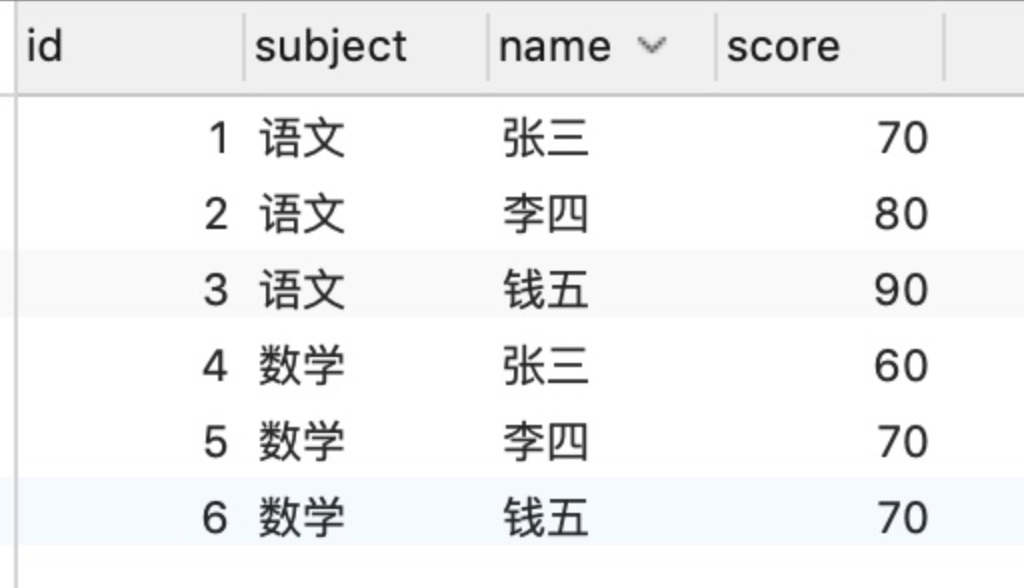
現在有個需求,需要查詢的時候多出一列subject_avg_score,為此科目所有人的平均成績,好跟每個人的成績做對比。
傳統方法肯定是用聚合,但是寫起來很麻煩也很累贅,這時候視窗函式就排上了用場。
因為視窗函式不會像聚合一樣將參與計算的行合併成一行輸出,而是將計算出來的結果帶回到了計算行上。
二、視窗函式的使用
1、聚合和視窗函式的區別
聚合:聚合函式(sum,min,avg……) + GROUP BY
視窗函式:聚合函式(sum,min,avg……) + OVER ( …… )
2、使用
還用上面的例子:
(1) 取每個不同科目的平均值subject_avg_score [這正是上面提到的需求]
這裡的 OVER 裡用到了 PARTITION BY
SELECT *,
avg("score") OVER (PARTITION BY "subject") as "subject_avg_score"
FROM "testScore" 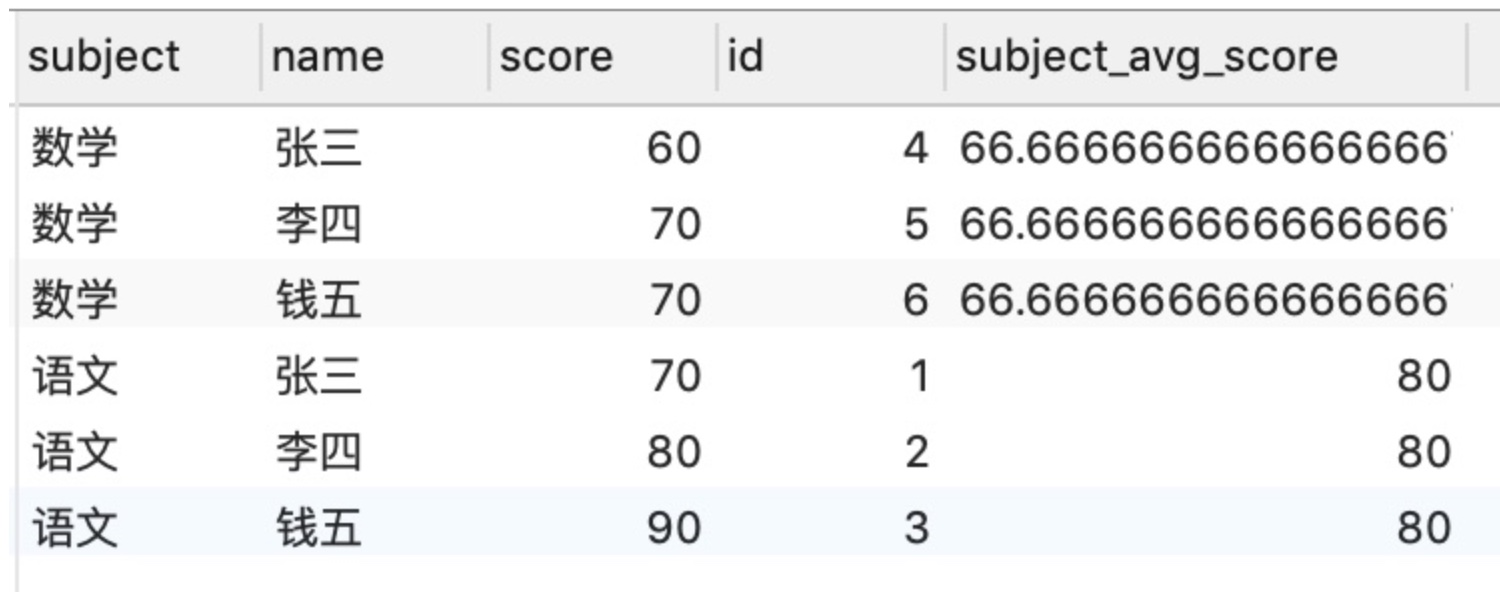
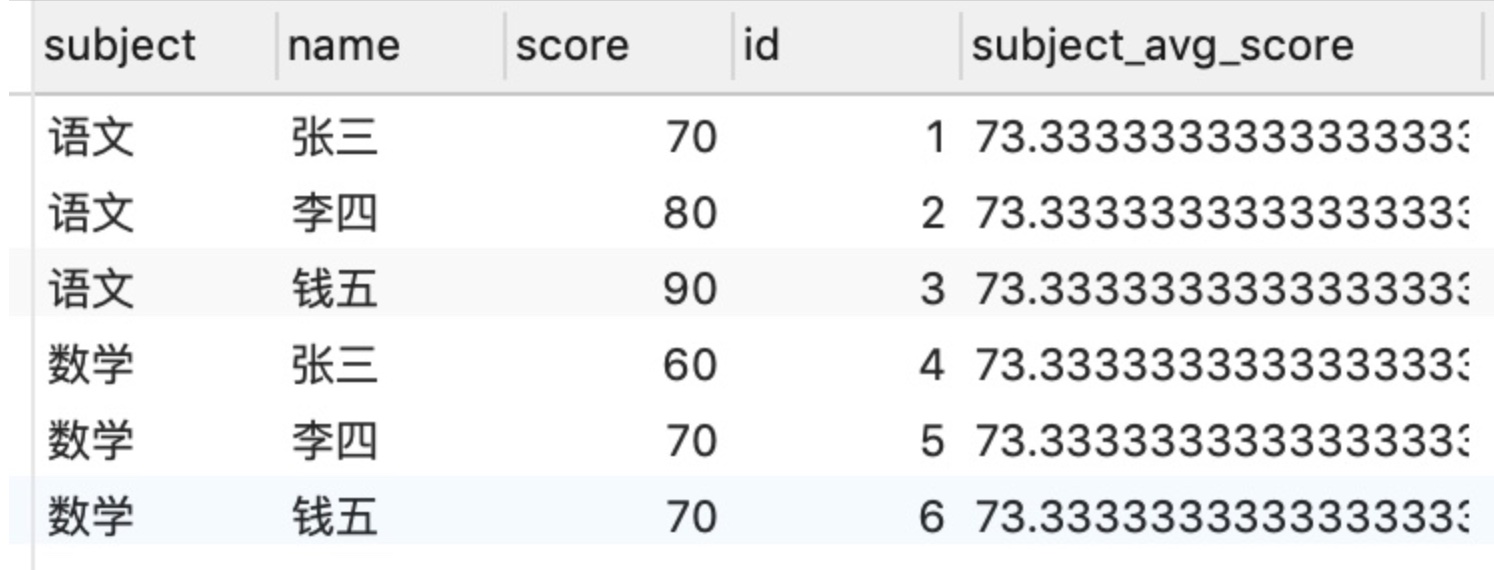
(2) 取所有成績的平均值subject_avg_score
這裡的 OVER 裡為空
SELECT *, avg("score") OVER () as "subject_avg_score" FROM "testScore"
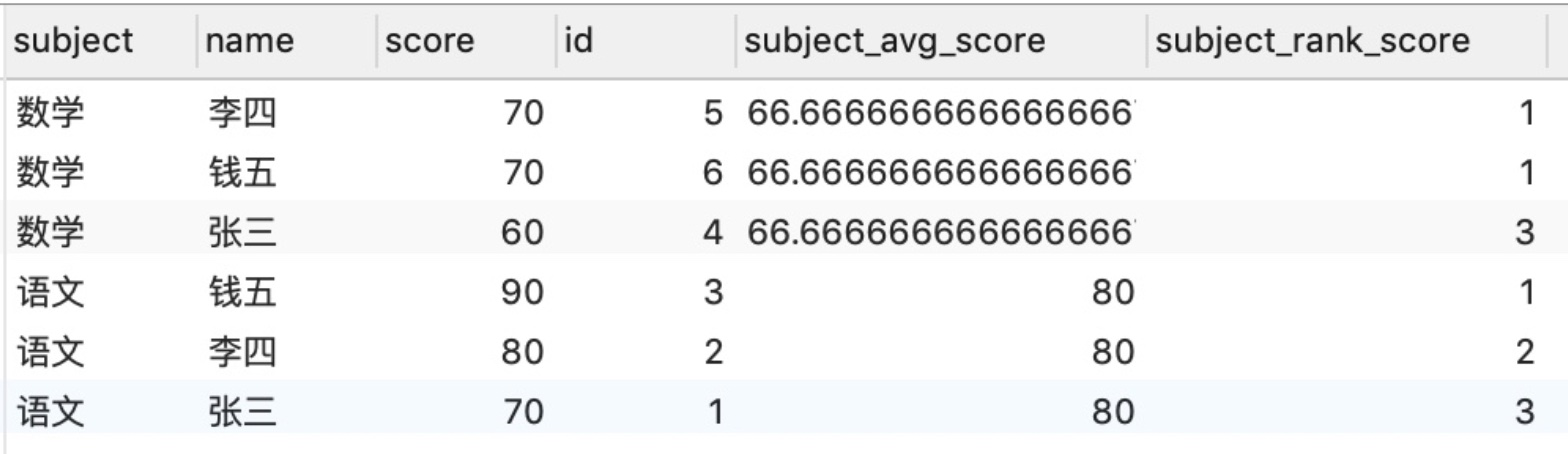
(3) 取此人該科目成績班上排第幾名subject_rank_score
這裡的 OVER 裡用到了 PARTITION BY + ORDER BY
ORDER BY 只能用在一些特殊的聚合函式裡,比如這裡的 rank()
SELECT *, avg("score") OVER (PARTITION BY "subject") as "subject_avg_score", rank() OVER (PARTITION BY "subject" ORDER BY "score" DESC) as "subject_rank_score" FROM "testScore"
拓展知識:rank()、dense_rank()、row_number() 區別
rank() 最適合用來做排名的功能,它是若兩人並列第一,那第三個人就排名第三
dense_rank() 跟 rank() 的區別是,若兩人並列第一,那第三個人緊隨其後排名第二
row_number() 則單純是序號,所以不會出現多個人並列的情況。
(4) 提取 OVER 變數
如果在 sql 裡寫了很多重複的 OVER(),可以提取成一個 window 變數,簡化程式碼。
SELECT *,
avg("score") OVER window_frame as "subject_avg_score",
avg("score") OVER window_frame as "subject_avg_score_2",
avg("score") OVER window_frame as "subject_avg_score_3"
FROM "testScore"
window window_frame as (PARTITION BY "subject")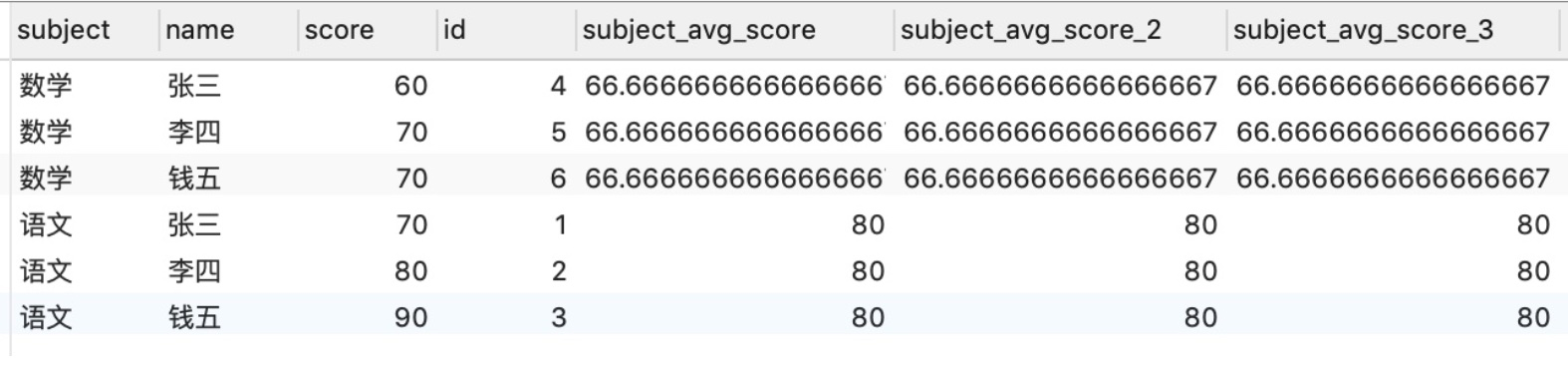
參考資料
官方文件:http://www.postgres.cn/docs/9.3/tutorial-window.html
Postgresql視窗函式(一)
Postgresql視窗函式(二