
使用Mxnet基於skip-gram模型實現word2vect
1. 需求
使用skip-gram模式實現word2vect,然後在jaychou_lyrics.txt資料集上應用
jaychou_lyrics.txt資料集收錄了周杰倫從第一張專輯
- 想要有直升機
想要和你飛到宇宙去
想要和你融化在一起
融化在宇宙裡
我每天每天每天在想想想想著你
這樣的甜蜜
讓我開始鄉相信命運
感謝地心引力
讓我碰到你
漂亮的讓我面紅的可愛女人
溫柔的讓我心疼的可愛女人
透明的讓我感動的可愛女人
壞壞的讓我瘋狂的可愛女人
2. 詞向量介紹
2.1 傳統方法的侷限性
我們知道,分詞後的資料是不能直接拿到模型裡去訓練的,我們需要把詞語轉換成詞向量才能進行模型的訓練,這樣一個詞可以有一個多維的詞向量組成。
傳統的方法是one-hot encoding,即用一個長向量來表示一個詞,向量的長度為詞典的大小,向量的分量只有一個1,其餘全為0,1的位置即對應改詞在詞典中的位置,如電腦表示為:[0 0 0 0 0 1 0 0 0 0 ],耳機表示為[0 0 0 0 0 0 0 1 0 ]這種方式如果採用稀疏儲存,表達簡潔,佔用空間少,但是這種方法也有幾個缺點,一是容易受維數災難的困擾,尤其是將其用於 Deep Learning的一些演算法時;二是不能很好地刻畫詞與詞之間的相似性,即任意兩個詞之間都是孤立的。光從這兩個向量中看不出兩個詞是否有關係,損失大部分資訊,導致結果會有較大偏差。
2.2 Word2Vec方法的優勢
在1968年Hinton又提出了Distributed REpresentation,可以解決One-hot encoding的缺點。其基本想法是直接用一個普通的向量表示一個詞,這種向量一般長成這個樣子:[0.792, −0.177, −0.107, 0.109, −0.542, ...],也就是普通的向量表示形式。維度以 50 維和 100 維比較常見。當然一個詞怎麼表示成這麼樣的一個向量需要通過訓練得到,訓練方法較多,word2vec是最常見的一種。需要注意的是,每個詞在不同的語料庫和不同的訓練方法下,得到的詞向量可能是不一樣的。詞向量一般維數不高,一般情況下指定100、500維就可以了,所以用起來維數災難的機會現對於one-hot representation表示就大大減少了。
由於是用向量表示,而且用較好的訓練演算法得到的詞向量的向量一般是有空間上的意義的,也就是說,將所有這些向量放在一起形成一個詞向量空間,而每一向量則為該空間中的一個點,在這個空間上的詞向量之間的距離度量也可以表示對應的兩個詞之間的“距離”。所謂兩個詞之間的“距離”,就是這兩個詞之間的語法,語義之間的相似性。
一個比較爽的應用方法是,得到詞向量後,假如對於某個詞A,想找出這個詞最相似的詞,在建立好詞向量後的情況,對計算機來說,只要拿這個詞的詞向量跟其他詞的詞向量一一計算歐式距離或者cos距離,得到距離最小的那個詞,就是它最相似的。
注:這裡偷了個懶,以上內容摘抄自部落格園博主Charlotte77,記得大佬曾對詞向量有過一段描述,寫的非常清楚,於是找來copy了下,在這裡感謝博主的分享
下面再簡單介紹下word2vect的兩種模型,skip-gram模型和cbow模型
2.3 CBOW模型
CBOW模型包含三層:輸入層、對映層、輸出層,其架構如下圖:
w(t)為輸入詞,在已知詞w(t)的前提下預測w(t)的上下文w(t-2)、w(t-1)、w(t+1)、w(t+2),條件概率為:\(p(w|context(w))\)。目標函式為:
\[\sum logp(w|context(w))\]
CBOW模型訓練其實就是根據某個詞前後若干個詞來預測該詞,這其實可以看出是多分類,最樸素的想法就是直接使用softmax來分別計算每個詞對應的歸一化的概率,但對於動輒十幾萬詞彙量的場景中使用softmax計算量太大,於是需要用一種二分類組合形式的hierarchical softmax,即輸出一顆二叉樹
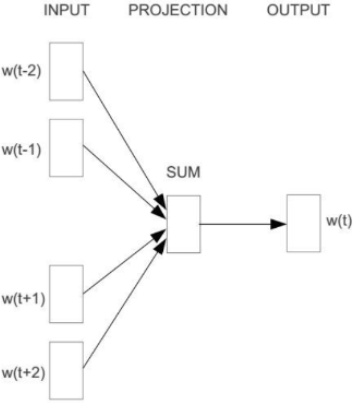
2.4 Skip-Gram模型
Skip-Gram模型包含三層:輸入層、對映層、輸出層,其架構如下圖:

w(t)為輸入詞,在已知詞w(t)的前提下預測w(t)的上下文w(t-2)、w(t-1)、w(t+1)、w(t+2),條件概率為:\(p(context(w)|w)\)。目標函式為:
\[\sum logp(context(w)|w)\]
Skip-Gram的基本思想是通過已知詞的前提下預測其上下文的詞,通過一個例子來說明,假設有個句子:
i love green eggs and ham
接下來,根據Skip-Gram演算法基本思想,把這個語句生成由系列(輸入,輸出)構成的資料集,當上下文視窗大小為1時,love的上下文為[i,green],green的上下文為[love,eggs],依次類推。上面的資料集可以轉換成:
datasets = [[love,i],[love,green],[green,love],[green,egges],...,[and,eggs],[and,ham]]
3. 實現思路
(1). 對資料集進行預處理,對資料集進行分詞處理、提取特徵詞、建議詞索引
(2). 二次取樣,降低高頻詞概率
(3). 提取中心詞和背景詞
(4). 負取樣
(5). 構建模型訓練資料
(6). 定義和訓練模型
4. 值得思考的關鍵點
(1). 中心詞和背景詞的提取方式
(2). 為什麼要進行負取樣,怎樣進行負取樣
(3). 當背景詞和負樣本詞視窗大小不固定時,該如何對資料進行建模
(4). 明確損失函式的計算方式
這裡就不作解答了,答案都在程式碼裡面
5. 具體實現過程
import random
import math
import zipfile
import jieba
import collections
import time
import mxnet as mn
from mxnet import nd,autograd,initializer
from mxnet.gluon import data as gdata
from mxnet.gluon import nn,trainer
from mxnet.gluon import loss as gloss5.1 讀資料文集,獲得資料集
# 讀資料文集,獲得資料集
def load_dataset(file):
dataset = []
with zipfile.ZipFile(file) as zf:
with zf.open(zf.namelist()[0]) as pf:
for line in pf.readlines():
line = line.decode('utf-8', 'ignore').strip()
dataset.append(line)
return datasetdatafile = '.\\datasets\\jaychou_lyrics.txt.zip'
dataset = load_dataset(datafile)
print(dataset[:3])['想要有直升機', '想要和你飛到宇宙去', '想要和你融化在一起']5.2 進行分詞處理
def check_contain_chinese(check_str):
'''
判斷郵件中的字元是否有中文
'''
for ch in check_str:
if u'\u4e00' <= ch <= u'\u9fff':
return True
return Falsedef proc_dataset_by_jieba(dataset):
sentences = []
for line in dataset:
sentence = []
seg_list = jieba.cut(line,cut_all= False)
for word in seg_list:
if not check_contain_chinese(word):
continue
sentence.append(word)
sentences.append(sentence)
return sentencessentences_by_jieba = proc_dataset_by_jieba(dataset)
print('ori words len:',sum([len(sentence) for sentence in sentences_by_jieba]))
print(sentences_by_jieba[:10])ori words len: 33825
[['想要', '有', '直升機'], ['想要', '和', '你', '飛到', '宇宙', '去'], ['想要', '和', '你', '融化', '在', '一起'], ['融化', '在', '宇宙', '裡'], ['我', '每天', '每天', '每天', '在', '想想', '想想', '著', '你'], ['這樣', '的', '甜蜜'], ['讓', '我', '開始', '鄉', '相信', '命運'], ['感謝', '地心引力'], ['讓', '我', '碰到', '你'], ['漂亮', '的', '讓', '我', '面紅', '的', '可愛', '女人']]5.3 建立詞索引
counter = collections.Counter([word for sentence in sentences_by_jieba for word in sentence])
cabulary_numbers_dict = dict(filter(lambda x:x[1] >= 5, counter.items())) # {詞:詞出現的次數}
index_to_word = [word for word,_ in cabulary_numbers_dict.items()] # 根據索引查詢詞
word_to_index = {word:index for index,word in enumerate(index_to_word)} # 根據詞得到索引
# 將原始資料集轉換為索引
sentences_to_index = []
for sentence in sentences_by_jieba:
sentence_to_index = []
for word in sentence:
if word in index_to_word:
sentence_to_index.append(word_to_index[word])
sentences_to_index.append(sentence_to_index)
print('sentences_to_index len:',len(sentences_to_index))
print('words len:',sum([len(sentence_index) for sentence_index in sentences_to_index]))sentences_to_index len: 5819
words len: 254295.4 二次抽樣
二次抽樣:文字資料中一般會出現一些高頻詞,通常來說,在一個背景視窗,一個詞和較低頻詞同時出現比和較高頻詞同時出現對訓練詞嵌入更有益,因此,訓練詞嵌入模型時可以對詞進行二次取樣,具體來說,資料集中每個被索引詞\(w_i\)將有一定的概率被丟棄,該丟棄的概率為\[P(w_i) = max(1- \sqrt{\frac{t}{f(w_i)}},0)\]
其中\(f(w_i)\)是資料集中詞\(w_i\)的個數與總次數的比,常數t是一個超引數,實驗中設為\(10^{-4}\),可見當\(f(w_i) > t\)時,才有可能在二次取樣中丟棄該詞\(w_i\),並且越高頻的詞被丟棄的概率越大
def throw_word(index):
temp = 1- math.sqrt(1e-4 / cabulary_numbers_dict[index_to_word[index]] * len(dataset_to_index))
return random.uniform(0,1) < temp
subsampled_sentences_index = [[word_index for word_index in sentence_index if not throw_word(word_index)]
for sentence_index in sentences_to_index]
print('subsampled_words len:',sum([len(sentence_index) for sentence_index in subsampled_sentences_index]))subsampled_words len: 7187經過二次抽樣後,我們發現從原始詞彙數33825--->25429---->7187
5.5 提取中心詞和背景詞
注意:下面在提取背景詞時採用的是非固定窗長
def get_centers_and_contexts(sentences,max_window_size):
centers,contexts= [], []
for sentence in sentences:
if len(sentence) < 2: # 每個句子至少要有兩個詞才能組成一對'中心詞-背景詞'
continue
centers += sentence
for center_index in range(len(sentence)):
window_size = random.randint(1,max_window_size)
indexs = list(range(max(0,center_index- window_size),min(len(sentence),center_index + window_size + 1)))
indexs.remove(center_index) # 將中心詞排除在背景詞之外
contexts.append([sentence[index] for index in indexs])
return centers,contextsall_centers,all_contexts = get_centers_and_contexts(subsampled_sentences_index,2)
print('中心詞個數:',len(all_centers))
print('中心詞對應的上下文列表數:',len(all_contexts))中心詞個數: 5110
中心詞對應的上下文列表數: 51105.6 負取樣
使用負取樣來進行近似訓練,對於一對中心詞和背景詞,我們隨機取樣K個噪音詞,根據word2vect論文的建議,噪音詞采樣概率\(P(w)\)設為w詞頻與總詞頻之比的0.75次方
def get_negatives(all_contexts, sampling_weights,k):
all_negatives = []
neg_candidates = []
population = list(range(len(sampling_weights)))
i = 0
for contexts in all_contexts:
negatives = []
while(len(negatives) < len(contexts) * k):
if i == len(neg_candidates):
neg_candidates = random.choices(population, sampling_weights, k=int(1e5))
i = 0
neg = neg_candidates[i]
i = i + 1
if neg not in set(contexts):
negatives.append(neg)
all_negatives.append(negatives)
return all_negativessampling_weights = [cabulary_numbers_dict[word]**0.75 for word in index_to_word]
all_negatives = get_negatives(all_contexts,sampling_weights,5)
print('中心詞對應的負樣本列表數:',len(all_negatives))中心詞對應的負樣本列表數: 51105.7 構造資料集
前面我們已經得到了中心詞列表、與中心詞對應的上下文列表和與中心詞對應的負樣本列表,接下來構建資料集,即模型訓練資料
資料集格式:

def build_batch_data(data):
'''
data資料由三部分組成:center,context,negative
'''
maxlen = max(len(context) + len(negative) for _,context,negative in data)
centers = []
context_negatives = []
masks = []
labels = []
for center,context,negative in data:
curlen = len(context) + len(negative)
centers.append(center)
context_negatives.append(context + negative + [0]*(maxlen - curlen))
masks.append([1]*curlen + [0]*(maxlen - curlen))
labels.append([1]*len(context) + [0]*(maxlen-len(context)))
return (nd.array(centers).reshape((-1,1)),
nd.array(context_negatives),
nd.array(masks),
nd.array(labels))batch_size = 512
dataset = gdata.ArrayDataset(all_centers,all_contexts,all_negatives)
data_iter = gdata.DataLoader(dataset, batch_size, shuffle=True, batchify_fn=build_batch_data)for batch in data_iter:
for name,data in zip(['centers','context_negatives','masks','labels'],batch):
print(name,'shape:',data.shape)
breakcenters shape: (512, 1)
context_negatives shape: (512, 24)
masks shape: (512, 24)
labels shape: (512, 24)5.8 定義和訓練模型
def skip_gram(center,context_and_negative, embed_c,embed_cn):
c = embed_c(center)
cn = embed_cn(context_and_negative)
return nd.batch_dot(c,cn.swapaxes(1,2))embed_size = 100 # 嵌入層大小
net = nn.Sequential()
net.add(nn.Embedding(input_dim = len(index_to_word), output_dim=embed_size), # 中心詞嵌入層
nn.Embedding(input_dim = len(index_to_word), output_dim=embed_size)) # 背景詞和負樣本嵌入層
loss = gloss.SigmoidBinaryCrossEntropyLoss()def train(net,learnint_rate,epochs,ctx=mn.gpu()):
net.initialize(init=initializer.Xavier(),ctx=ctx,force_reinit=True)
trainer_op = trainer.Trainer(net.collect_params(),'adam', {'learning_rate':learnint_rate})
for epoch in range(epochs):
start,loss_sum,n = time.time(),0.0, 0
for batch in data_iter:
center,context_negative, mask, label = [data.as_in_context(ctx) for data in batch]
with autograd.record():
pred = skip_gram(center,context_negative,net[0],net[1])
loss_val = (loss(pred.reshape(label.shape),label,mask) * mask.shape[1] / mask.sum(axis=1))
loss_val.backward()
trainer_op.step(batch_size)
loss_sum += loss_val.sum().asscalar()
n += loss_val.size
print('epoch:%d,loss:%.2f,time %.2f' %(epoch+1, loss_sum / n,time.time() - start))train(net,0.01,20)epoch:1,loss:0.69,time 0.33
epoch:2,loss:0.64,time 0.27
epoch:3,loss:0.52,time 0.25
epoch:4,loss:0.38,time 0.23
epoch:5,loss:0.30,time 0.22
epoch:6,loss:0.23,time 0.22
epoch:7,loss:0.17,time 0.23
epoch:8,loss:0.12,time 0.22
epoch:9,loss:0.09,time 0.22
epoch:10,loss:0.07,time 0.23
epoch:11,loss:0.06,time 0.22
epoch:12,loss:0.05,time 0.23
epoch:13,loss:0.04,time 0.23
epoch:14,loss:0.04,time 0.22
epoch:15,loss:0.03,time 0.22
epoch:16,loss:0.03,time 0.22
epoch:17,loss:0.03,time 0.22
epoch:18,loss:0.03,time 0.22
epoch:19,loss:0.03,time 0.22
epoch:20,loss:0.02,time 0.275.9 詞向量視覺化
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
num_points = 200
# TSNE提供了一種有效的降維方式,讓我們對高於2維資料的聚類結果以二維的方式展示出來
tsne = TSNE(perplexity=30,n_components=2,init='pca',n_iter=5000)
embeddings = net[0].weight.data().asnumpy()
two_d_embeddings = tsne.fit_transform(embeddings[0:num_points,:])import matplotlib
#解決中文顯示亂碼的問題
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
def plot(embeddings,labels):
plt.figure(figsize=(16,20))
for i,label in enumerate(labels):
x,y = embeddings[i,:]
plt.scatter(x,y)
plt.annotate(label,(x,y),xytext=(5,2),textcoords='offset points',ha='right',va='bottom')
plt.show()
words = [index_to_word[i] for i in range(num_points)]
plot(two_d_embeddings,words)
從上圖,你能唱出幾句周董的歌?,程式碼和資料集均已上傳到git