
BERT程式碼實現及解讀
阿新 • • 發佈:2019-08-02
注意力機制系列可以參考前面的一文:
Transformer Block
BERT中的點積注意力模型
公式:
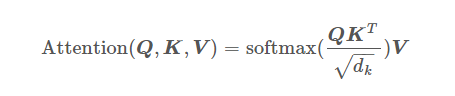
程式碼:
class Attention(nn.Module): """ Scaled Dot Product Attention """ def forward(self, query, key, value, mask=None, dropout=None): scores = torch.matmul(query, key.transpose(-2, -1)) \ / math.sqrt(query.size(-1)) if mask is not None: scores = scores.masked_fill(mask == 0, -1e9) # softmax得到概率得分p_atten, p_attn = F.softmax(scores, dim=-1) # 如果有 dropout 就隨機 dropout 比例引數 if dropout is not None: p_attn = dropout(p_attn) return torch.matmul(p_attn, value), p_attn
在 self attention的計算過程中, 通常使用min batch來計算, 也就是一次計算多個句子,多句話得長度並不一致,因此,我們需要按照最大得長度對短句子進行補全,也就是padding零,但這樣做得話,softmax計算就會被影響,$e^0=1$也就是有值,這樣就會影響結果,這並不是我們希望看到得,因此在計算得時候我們需要把他們mask起來,填充一個負無窮(-1e9這樣得數值),這樣計算就可以為0了,等於把計算遮擋住。
多頭自注意力模型
公式:
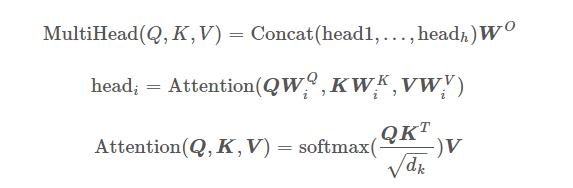
Attention Mask
程式碼:
class MultiHeadedAttention(nn.Module): """ Take in model size and number of heads. """ def __init__(self, h, d_model, dropout=0.1): # h 表示模型個數 super().__init__() assert d_model % h == 0 # d_k 表示 key長度,d_model表示模型輸出維度,需保證為h得正數倍 self.d_k = d_model // h self.h = h self.linear_layers = nn.ModuleList([nn.Linear(d_model, d_model) for _ in range(3)]) self.output_linear = nn.Linear(d_model, d_model) self.attention = Attention() self.dropout = nn.Dropout(p=dropout) def forward(self, query, key, value, mask=None): batch_size = query.size(0) # 1) Do all the linear projections in batch from d_model => h x d_k query, key, value = [l(x).view(batch_size, -1, self.h, self.d_k).transpose(1, 2) for l, x in zip(self.linear_layers, (query, key, value))] # 2) Apply attention on all the projected vectors in batch. x, attn = self.attention(query, key, value, mask=mask, dropout=self.dropout) # 3) "Concat" using a view and apply a final linear. x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.h * self.d_k) return self.output_linear(x)
Position-wise FFN
Position-wise FFN 是一個雙層得神經網路,在論文中採用ReLU做啟用層:
公式:

注:在 google github中的BERT的程式碼實現中用Gaussian Error Linear Unit代替了RelU作為啟用函式
程式碼:
class PositionwiseFeedForward(nn.Module): def __init__(self, d_model, d_ff, dropout=0.1): super(PositionwiseFeedForward, self).__init__() self.w_1 = nn.Linear(d_model, d_ff) self.w_2 = nn.Linear(d_ff, d_model) self.dropout = nn.Dropout(dropout) self.activation = GELU() def forward(self, x): return self.w_2(self.dropout(self.activation(self.w_1(x)))) class GELU(nn.Module): """ Gaussian Error Linear Unit. This is a smoother version of the RELU. Original paper: https://arxiv.org/abs/1606.08415 """ def forward(self, x): return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
Layer Normalization
LayerNorm實際就是對隱含層做層歸一化,即對某一層的所有神經元的輸入進行歸一化(沿著通道channel方向),使得其加快訓練速度:

層歸一化公式:
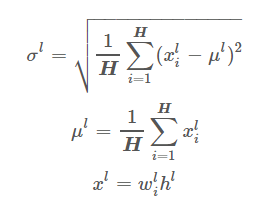
$l$表示第L層,H 是指每層的隱藏單元數(hidden unit),$\mu$表示平均值,$\sigma$表示方差, $\alpha$表示表徵向量,$w$表示矩陣權重。
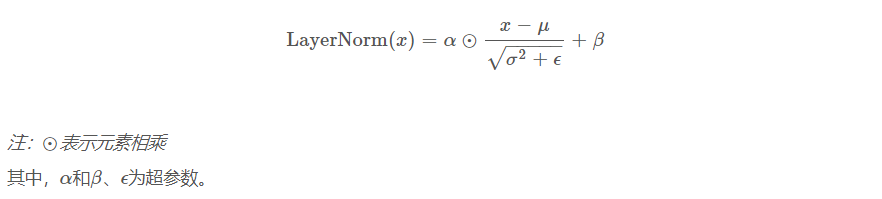
程式碼:
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
# mean(-1) 表示 mean(len(x)), 這裡的-1就是最後一個維度,也就是最裡面一層的維度
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
殘差連線
殘差連線就是圖中Add+Norm層。每經過一個模組的運算, 都要把運算之前的值和運算之後的值相加, 從而得到殘差連線,殘差可以使梯度直接走捷徑反傳到最初始層。
殘差連線公式:
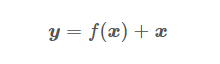
X 表示輸入的變數,實際就是跨層相加。
程式碼:
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
# Add and Norm
return x + self.dropout(sublayer(self.norm(x)))
Transform Block

程式碼:
class TransformerBlock(nn.Module):
"""
Bidirectional Encoder = Transformer (self-attention)
Transformer = MultiHead_Attention + Feed_Forward with sublayer connection
"""
def __init__(self, hidden, attn_heads, feed_forward_hidden, dropout):
"""
:param hidden: hidden size of transformer
:param attn_heads: head sizes of multi-head attention
:param feed_forward_hidden: feed_forward_hidden, usually 4*hidden_size
:param dropout: dropout rate
"""
super().__init__()
# 多頭注意力模型
self.attention = MultiHeadedAttention(h=attn_heads, d_model=hidden)
# PFFN
self.feed_forward = PositionwiseFeedForward(d_model=hidden, d_ff=feed_forward_hidden, dropout=dropout)
# 輸入層
self.input_sublayer = SublayerConnection(size=hidden, dropout=dropout)
# 輸出層
self.output_sublayer = SublayerConnection(size=hidden, dropout=dropout)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x, mask):
x = self.input_sublayer(x, lambda _x: self.attention.forward(_x, _x, _x, mask=mask))
x = self.output_sublayer(x, self.feed_forward)
return self.dropout(x)
Embedding嵌入層
Embedding採用三種相加的形式表示:

程式碼:
class BERTEmbedding(nn.Module):
"""
BERT Embedding which is consisted with under features
1. TokenEmbedding : normal embedding matrix
2. PositionalEmbedding : adding positional information using sin, cos
3. SegmentEmbedding : adding sentence segment info, (sent_A:1, sent_B:2)
sum of all these features are output of BERTEmbedding
"""
def __init__(self, vocab_size, embed_size, dropout=0.1):
"""
:param vocab_size: total vocab size
:param embed_size: embedding size of token embedding
:param dropout: dropout rate
"""
super().__init__()
self.token = TokenEmbedding(vocab_size=vocab_size, embed_size=embed_size)
self.position = PositionalEmbedding(d_model=self.token.embedding_dim)
self.segment = SegmentEmbedding(embed_size=self.token.embedding_dim)
self.dropout = nn.Dropout(p=dropout)
self.embed_size = embed_size
def forward(self, sequence, segment_label):
x = self.token(sequence) + self.position(sequence) + self.segment(segment_label)
return self.dropout(x)
位置編碼(Positional Embedding)
位置嵌入的維度為 [