
海量結構化資料儲存技術揭祕:Tablestore儲存和索引引擎詳解
前言
表格儲存Tablestore是阿里雲自研的面向海量結構化資料儲存的Serverless NoSQL多模型資料庫。Tablestore在阿里雲官網上有各種文件介紹,也釋出了很多場景案例文章,這些文章收錄在這個合集中
《表格儲存Tablestore權威指南》。值得一提的是,Tablestore可以支撐海量的資料規模,也提供了多種索引來支援豐富的查詢模式,同時作為一個多模型資料庫,提供了多種模型的抽象和特有介面。本文主要對Tablestore的儲存和索引引擎進行介紹和解讀,讓大家對Tablestore引擎層的原理和能力,索引的作用和使用方式等有一個認識。
基本架構
Tablestore是一款雲上的Serverless的分散式NoSQL多模型資料庫,提供了豐富的功能。假設使用者可以採用各種開源元件搭建一套類似服務,可以說是成本非常高昂,而使用Tablestore僅需在控制檯上建立一個例項即可享受全部功能,而且是完全按量計費,可以說是0門檻。
整體架構如下圖所示,本文不展開敘述每個模組的功能。
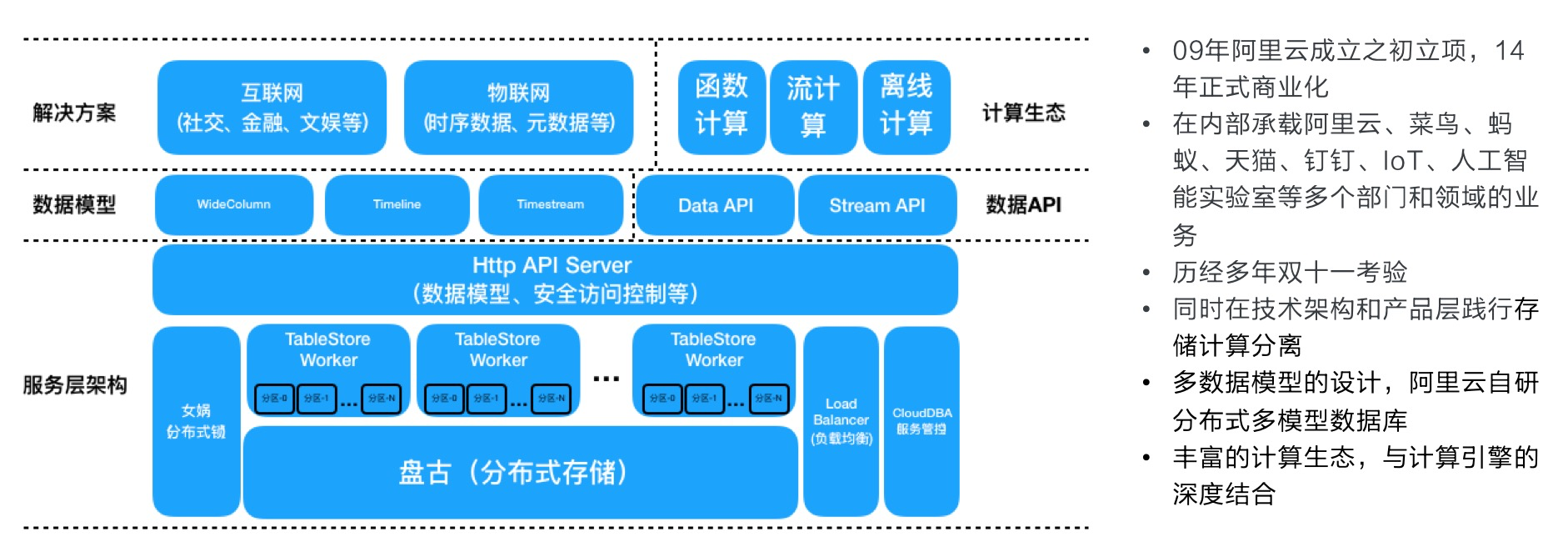
在服務端引擎層中,存在兩個引擎:儲存引擎和索引引擎。這兩個引擎的資料結構和原理不同,為了方便讀者理解,本文將這兩個引擎稱為表引擎(Table)和多元索引引擎(Searchindex)。整體來說,引擎層是基於LSM架構和共享儲存(盤古),支援自動的Sharding和儲存計算分離。
表引擎
表引擎的整體架構類似於Google的BigTable,在開源領域的實現有HBase等。
資料模型可以定義為寬行模型,如下圖所示。其中不同的分割槽可以載入到不同的機器上,實現水平擴充套件:

首先說明一下為什麼Tablestore的主鍵可以包含多個主鍵列,而像HBase只有一個RowKey。這裡有幾點:
- 多列主鍵列按照順序共同構成一個主鍵,類似MySQL的聯合主鍵。如果使用過HBase,可以把這裡的多列主鍵列,拼接起來看作一個RowKey,每一列其實都只是整體主鍵的一部分。
- 第一列主鍵列是分割槽鍵,使用分割槽鍵的範圍進行分區劃分,保證了分割槽鍵相同的行,一定在同一個分割槽(Partition)上。一些功能依賴這一特性,比如分割槽內事務(Transection),本地二級索引(LocalIndex, 待發布),分割槽內自增列等。
- 業務上常需要多個欄位來構成主鍵,如果只支援一個主鍵列,業務需要進行拼接,多列主鍵列避免了業務層做主鍵拼接和拆解。
- 許多使用者第一次看到多列主鍵列時,常會有誤解,認為主鍵的範圍查詢(GetRange介面)可以針對每一列單獨進行,實際上這裡的主鍵範圍指的是整體主鍵的範圍,而非單獨某一列的範圍。
這個模型具有這樣的一些優勢:
- 完全水平擴充套件,因此可支撐的讀寫併發和資料規模幾乎無上限。Tablestore線上也有一些業務在幾千萬級的tps/qps,以及10PB級的儲存量。可以說一般業務達不到這樣的上限,實際的上限僅取決於叢集目前的機器資源,當業務資料量大量上漲時,只要增加機器資源即可。同時,基於共享儲存的架構也很方便的實現了動態負載均衡,不需要資料庫層進行副本資料複製。
- 提供了表模型,相比純粹的KeyValue資料庫而言,具有列和多版本的概念,可以單獨對某列進行讀寫。表模型也是一種比較通用的模型,可以方便與其他系統進行資料模型對映。
- 表模型中,按照主鍵有序儲存,而非Hash對映,因此支援主鍵的範圍掃描。類似於HashMap與SortedMap的區別,這個模型中為SortedMap。
- Schema Free, 即每行可以有不同的屬性列,資料列個數也不限制。這很適合儲存半結構化的資料,同時業務在執行過程中,也可以進行任意的屬性列變更。
- 支援資料自動過期和多版本。每列都可以儲存多個版本的值,每個值會有一個版本號,同時也是一個時間戳,如果設定了資料自動過期,就會按照這個時間戳來判斷資料是否過期,後臺對過期資料自動清理。
這個模型也有一些劣勢:
-
資料查詢依賴主鍵。可以把這個資料模型理解為SortedMap,大家知道,在SortedMap上只能做點查和順/逆序掃描,比如以下查詢方式:
- 主鍵點查:通過已知主鍵,精確讀取表上的一行。
- 主鍵範圍查:按照順序從開始主鍵(StartPrimaryKey)掃描到結束主鍵(EndPrimaryKey),或者逆序掃描。即對Table進行順序或逆序遍歷,支援指定起始位置和結束位置。
- 主鍵字首範圍查:其實等價於主鍵範圍查,這裡只是說明,主鍵字首的一個範圍,其實可以轉換成主鍵的一個範圍,在表上進行順序掃描即可。
-
針對屬性列的查詢需要使用Filter,Filter模式在過濾大量資料時效率不高,甚至變成全表掃描。通常來說,資料查詢的效率與底層掃描的資料量正相關,而底層掃描的資料量取決於資料分佈和結構。資料預設僅按照主鍵有序儲存,那麼要按照某一屬性列查詢,符合條件的資料必然分佈於全表的範圍內,需要掃描後篩選。全表資料越多,掃描的資料量也就越大,效率也就越低。
那麼在實際業務中,主鍵查詢常常不能滿足需求,而使用Filter在資料規模大的情況下效率很低,怎麼解決這一問題呢?
上面提到,資料查詢的效率與底層掃描的資料量正相關,而Filter模式慢在符合條件的資料太分散,必須掃描大量的資料並從中篩選。那麼解決這一問題也就有兩種思路:
- 讓符合條件的資料不再分散分佈:使用全域性二級索引,將某列或某幾列作為二級索引的主鍵。相當於通過資料冗餘,直接把符合條件的資料預先排在一起,查詢時直接精確定位和掃描,效率極高。
- **加快篩選的速度: **使用多元索引,多元索引底層提供了倒排索引,BKD-Tree等資料結構。以上面查詢某屬性列值為例,我們給這一列建立多元索引後,就會給這一列的值建立倒排索引,倒排索引實際上記錄了某個值對應的所有主鍵的集合,即Value -> List, 那麼要查詢屬性列為某個Value的所有記錄時,直接通過倒排索引獲取所有符合條件的主鍵,進行讀取即可。本質上是加快了從海量資料中篩選資料的效率。
全域性二級索引
全域性二級索引採用的仍然是表引擎,給主表建立了全域性二級索引後,相當於多了一張索引表。這張索引表相當於給主表提供了另外一種排序的方式,即針對查詢條件預先設計了一種資料分佈,來加快資料查詢的效率。索引的使用方式與主表類似,主要的查詢方式仍然是上面講的主鍵點查,主鍵範圍查,主鍵字首範圍查。常見的關係型資料庫的二級索引也是類似的原理。
列舉一個最簡單的例子,比如我們有一張表儲存檔案的MD5和SHA1值,表結構如下:
| FilePath(主鍵列) | MD5(屬性列) | SHA1(屬性列) |
|---|---|---|
| oss://abc/files/1.txt | 0cc175b9c0f1b6a831c399e269772661 | 86f7e437faa5a7fce15d1ddcb9eaeaea377667b8 |
| oss://abc/files/2.txt | 92eb5ffee6ae2fec3ad71c777531578f | e9d71f5ee7c92d6dc9e92ffdad17b8bd49418f98 |
| oss://abc/files/3.txt | 4a8a08f09d37b73795649038408b5f33 | 84a516841ba77a5b4648de2cd0dfcb30ea46dbb4 |
通過這張表,我們可以查詢檔案對應的MD5和SHA1值,但是通過MD5或SHA1反查檔名卻不容易。我們可以給這張表建立兩張全域性二級索引表,表結構分別為:
索引1:
| MD5(主鍵列1) | FilePath(主鍵列2) |
|---|---|
| 0cc175b9c0f1b6a831c399e269772661 | oss://abc/files/1.txt |
| 4a8a08f09d37b73795649038408b5f33 | oss://abc/files/3.txt |
| 92eb5ffee6ae2fec3ad71c777531578f | oss://abc/files/2.txt |
索引2:
| SHA1(主鍵列1) | FilePath(主鍵列2) |
|---|---|
| 84a516841ba77a5b4648de2cd0dfcb30ea46dbb4 | oss://abc/files/3.txt |
| 86f7e437faa5a7fce15d1ddcb9eaeaea377667b8 | oss://abc/files/1.txt |
| e9d71f5ee7c92d6dc9e92ffdad17b8bd49418f98 | oss://abc/files/2.txt |
為了確保主鍵的唯一性,全域性二級索引中,會將原主鍵的主鍵列也放到主鍵列中,比如上面的FilePath列。有了上面兩張索引表,就可以通過主鍵字首範圍查的方式裡精確定位某個MD5/SHA1對應的檔名了。
多元索引引擎
多元索引引擎相比於表引擎,底層增加了倒排索引,多維空間索引等,支援多條件組合查詢、模糊查詢、地理空間查詢,以及全文索引等,還提供一些統計聚合能力(統計聚合功能待發布)。因為功能較單純的二級索引更加豐富,而且一個索引就可以滿足多種維度的查詢,因此命名為多元索引。
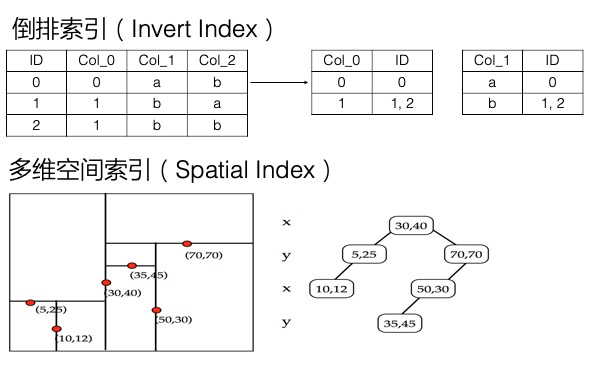
上面在講解決Filter模式查詢慢的問題時,提到倒排索引加快了資料篩選的速度,因為記錄了某列的Value到符合條件的行的對映,Value -> List 。實際上,倒排索引這一方式,不僅可以解決單列值的檢索問題,也可以解決多條件組合查詢的問題。
我們舉一個訂單場景的例子,比如下表為一個訂單記錄:
| 訂單號 | 訂單(md5)(主鍵) | 消費者編號 | 消費者姓名 | 售貨員編號 | 售貨員姓名 | 產品編號 | 產品名 | 產品品牌 | 產品型別 | 下單時間 | 支付時間 | 支付狀態 | 產品單價 | 數量 | 總價錢 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| o0000000000 | c49f5fd5aba33159accae0d3ecd749a7 | c0019 | 消陳九 | s0020 | 售楚十 | p0003004 | vivo x21 | vivo | 手機 | 2018-07-17 21:00:00 | 否 | 2498.99 | 2 | 4997.98 |
上面一共16個欄位,我們希望按照任意多個欄位組合查詢,比如查詢某一售貨員、某一產品型別、單價在xx元之上的所有記錄。可以想到,這樣的排列組合會有非常多種,因此我們不太可能預先將任何一種查詢條件的資料放到一起,來加快查詢的效率,這需要建立很多的全域性二級索引。而如果採用Filter模型,又很可能需要掃描全表,效率不高。折中的方式是,可以先對某個欄位建立二級索引,縮小資料範圍,再對其中資料進行Filter。那麼有沒有更好的方式呢?
多元索引可以很好的解決這一問題,而且只需要建立一個多元索引,將所有可能查詢的列加入到這個多元索引中即可,加入的順序也沒有要求。多元索引中的每一列預設都會建立倒排,倒排就記錄了Value到List的對映。針對多列的多個條件,在每列的倒排表中找到對應的List,這個稱為一個倒排鏈,而篩選符合多個條件的資料即為計算多個倒排鏈的交併集,這裡底層有著大量的優化,可以高效的實現這一操作。因此多元索引在處理多條件組合查詢方面效率很高。
此外,多元索引還支援全文索引、模糊查詢、地理空間查詢等,以地理空間查詢為例,多元索引通過底層的BKD-Tree結構,支援高效的查詢一個地理多邊形內的點,也支援按照地理位置排序、聚合統計等。
索引選擇
不是一定需要索引
- 如果基於主鍵和主鍵範圍查詢的功能已經可以滿足業務需求,那麼不需要建立索引。
- 如果對某個範圍內進行篩選,範圍內資料量不大或者查詢頻率不高,可以使用Filter,不需要建立索引。
- 如果是某種複雜查詢,執行頻率較低,對延遲不敏感,可以考慮通過DLA(資料湖分析)服務訪問Tablestore,使用SQL進行查詢。
全域性二級索引還是多元索引
- 一個全域性二級索引是一個索引表,類似於主表,其提供了另一種資料分佈方式,或者認為是另一種主鍵排序方式。一個索引對應一種查詢條件,預先將符合查詢條件的資料排列在一起,查詢效率很高。索引表可支撐的資料規模與主表相同,另一方面,全域性二級索引的主鍵設計也同樣需要考慮雜湊問題。
- 一個多元索引是一系列資料結構的組合,其中的每一列都支援建立倒排索引等結構,查詢時可以按照其中任意一列進行排序。一個多元索引可以支援多種查詢條件,不需要對不同查詢條件建立多個多元索引。相比全域性二級索引,也支援多條件組合查詢、模糊查詢、全文索引、地理位置查詢等。多元索引本質上是通過各種資料結構加快了資料的篩選過程,功能非常豐富,但在資料按照某種固定順序讀取這種場景上,效率不如全域性二級索引。多元索引的查詢效率與倒排鏈長度等因素相關,即查詢效能與整個表的全量資料規模有關,在資料規模達到百億行以上時,建議使用RoutingKey對資料進行分片,查詢時也通過指定RoutingKey查詢來減少查詢涉及到的資料量。簡而言之,查詢靈活度和資料規模不可兼得。
關於使用多元索引還是全域性二級索引,也有另外一篇文章描述:《Tablestore索引功能詳解》。
除了全域性二級索引之外,後續還會推出本地二級索引(LocalIndex),推出後再進行詳細介紹。
常見組合方案
豐富的查詢功能當然是業務都希望具備的,但是在資料規模很大的情況下,靈活的查詢意味著成本。比如萬億行資料的規模,對於表引擎來說,因為水平擴充套件能力很強,成本也很低,問題不大,但是建立多元索引,費用就會非常高昂。全域性二級索引成本較低,但是隻適合固定維度的查詢。
常見的超大規模資料,都帶有一些時間屬性,比如大量裝置產生的資料(監控資料),或者人產生的資料(訊息、行為資料等),這類資料非常適合採用Tablestore儲存。對這類資料建立索引,會有一些組合方案:
-
對元資料表建立多元索引,全量資料表不建立索引或採用全域性二級索引。
- 元資料表可以是產生資料的主體表,比如裝置資訊表,使用者資訊表等。在時序模型中,產生資料的主體也可以認為是一個時間線,這條線會不斷的產生新的點。
- Tablestore的時序資料模型(Timestream)採用的也是類似的方式,對時序資料中的時間線建立一張表,專門用來記錄時間線的元資料,每個時間線一行。時間線表建立多元索引,用來做時間線檢索,而全量資料則不建立索引。在檢索到時間線後,對某個時間線下的資料進行範圍掃描,來讀取這個時間線的資料。
-
熱資料建立多元索引,老資料不建立索引或者採用全域性二級索引:
- 很多情況下僅需要對非常熱的資料進行多種維度查詢,對冷資料採取固定維度查詢即可。因此冷熱分離可以給業務提供更高的價效比。
- 目前多元索引還不支援TTL(後續會支援),需要業務層區分熱資料和冷資料。
總結
本文對Tablestore的儲存和索引引擎進行了介紹和解讀,並在如何選擇和應用索引方面給了一些參考,目的是加深大家對Tablestore的認識和理解,更好的應用Tablestore來解決業務需求。
本文作者:亦徵
本文為雲棲社群原創內容,未經