
ElasticSearch基礎知識
簡介
ElasticSearch(以下簡稱ES)是一個基於Lucene的搜尋伺服器,它提供了一個分散式多使用者能力的全文搜尋引擎。基於RESTful web介面。要想深入瞭解 ES,需要先對 Lucene 有一個清晰的認識,那麼什麼是 Lucene 呢?
Lucene
普通資料庫的缺陷:
- 沒有高效的索引方式,查詢的速度在大量資料的情況下很慢
- 搜尋效果差,只能對使用者輸入的完整關鍵字進行首尾模糊匹配
- 使用者搜尋時如果錯輸,則查詢的結果可能差別很大
搜尋引擎
搜尋引擎是指根據一定的策略,運用特定的計算機程式從網際網路上搜集資訊,對資訊進行組織和處理後,為使用者提供檢索服務。將使用者檢索相關的資訊展示給使用者的系統。
分類:
垂直搜尋:通常也叫做細分,指專門針對某一類資訊進行搜尋
綜合搜尋:是指對眾多資訊進行綜合性的搜尋,如:百度、谷歌。。。
站內搜尋:對網站內部的資訊進行搜尋,對自己資料庫進行搜尋
軟體內部搜尋:如 word / idea 進行搜尋
倒排索引技術
倒排索引(反向索引)以詞條為索引,表中關鍵字對應的記錄項記錄了出現這個字或詞的所有文件,每一個表項記錄該文件的ID和關鍵字在該文件中出現的位置情況
全文檢索
計算機對文件的全部內容進行分詞,對每個詞建立一個索引,索引記錄單詞出現的位置和c
Lucene 是一個開源的全文檢索引擎工具包
安裝
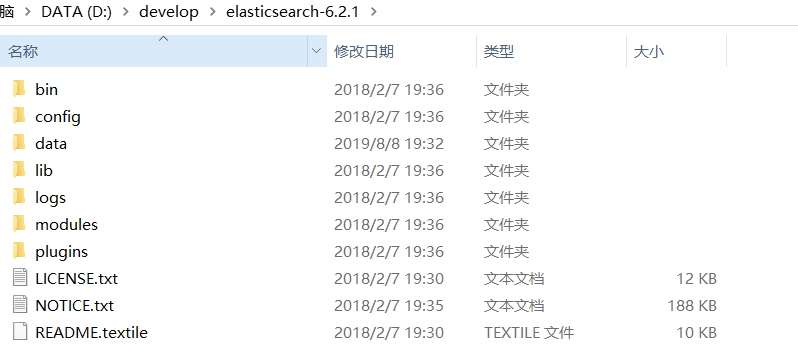
bin:指令碼目錄,包括:啟動、停止等可執行指令碼
config:配置檔案目錄
logs:日誌目錄
modules:模組目錄,包括了es的功能模組
plugins :外掛目錄,es支援外掛機制
配置檔案
三個配置檔案
elasticsearch.yml:用於配置Elasticsearch執行引數
jvm.options:用於配置Elasticsearch JVM設定
log4j2.properties:用於配置Elasticsearch日誌
es.yml
# 常用的配置項如下: # 配置elasticsearch的叢集名稱,預設是elasticsearch。建議修改成一個有意義的名稱。 cluster.name: YunShangXue # 節點名稱 node.name: masterNode # 網路地址,配置成 0.0.0.0 代表任意地址 network.host: 0.0.0.0: # HTTP埠號 http.port: 9200 # 叢集互動的埠號 transport.tcp.port: 9300 # 指定該節點是否有資格被選舉成為master結點,如果原來的master宕機會重新選舉新的master node.master: true # 是否是資料節點 node.data: true # 開發環境下叢集節點的地址和埠們 discovery.zen.ping.unicast.hosts: ["0.0.0.0:9300", "0.0.0.0:9301", "0.0.0.0:9302"] # 主結點數量的最少值 ,此值的公式為:(master_eligible_nodes / 2) + 1 ,比如:有3個符合要求的主結點,那麼這裡要設定為2。 discovery.zen.minimum_master_nodes: 1 # 鎖住ES使用的記憶體,避免記憶體與swap分割槽交換資料。 bootstrap.memory_lock: false # 單機允許的最大儲存結點數,通常單機啟動一個結點建議設定為1,開發環境如果單機啟動多個節點可設定大於1 node.max_local_storage_nodes: 1 # 索引檔案、日誌檔案路徑 path.data: D:\ElasticSearch\elasticsearch‐6.2.1\data path.logs: D:\ElasticSearch\elasticsearch‐6.2.1\logs # 允許跨域? http.cors.enabled: true http.cors.allow‐origin: /.*/ # 設定ES自動發現節點連線超時的時間,預設為3秒,如果網路延遲高可設定大些。 discovery.zen.ping.timeout: 3s
jvm.options
設定最小及最大的JVM堆記憶體大小:
在jvm.options中設定 -Xms和-Xmx:
- 兩個值設定為相等
- 將 Xmx 設定為不超過實體記憶體的一半。
log4j2.properties
日誌檔案設定,ES使用log4j,注意日誌級別的配置。生產環境下設定為 error
安裝 head 外掛
- 下載
git clone git://github.com/mobz/elasticsearch-head.git cd elasticsearch-head npm install npm run start open- 執行

Head操作ES
建立索引庫
ES的索引庫是一個邏輯概念,它包括了分詞列表及文件列表,同一個索引庫中儲存了相同型別的文件。它就相當於
MySQL中的表,或相當於Mongodb中的集合
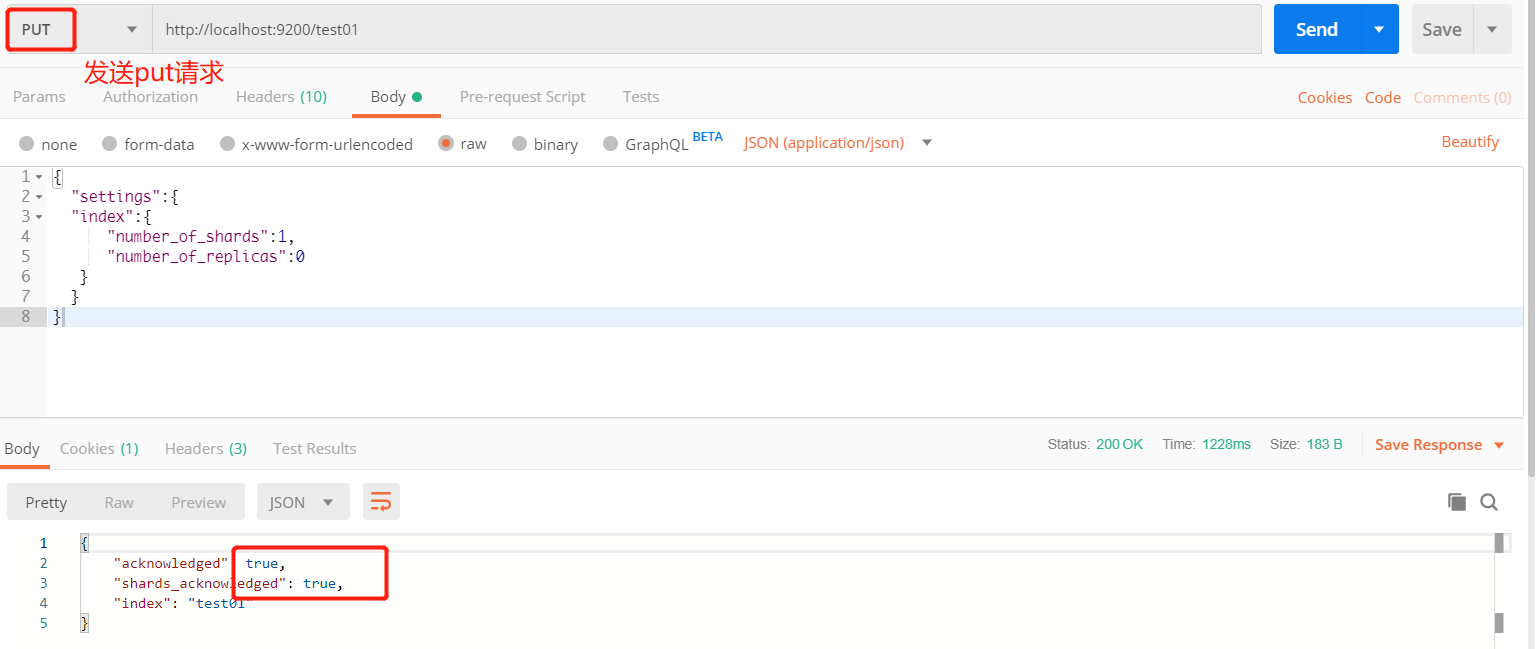
- 使用 RESTful 風格的方式來建立:使用 postman 傳送如下請求
put http://localhost:9200/索引庫名稱(相當於建立了MySQL中的表){
"settings":{
"index":{
"number_of_shards":1, // 分片數量
"number_of_replicas":0 // 副本數量
}
}
}
- 使用 Head 外掛直接建立
建立對映
概念說明
| MySQL | ES |
|---|---|
| 資料庫 | |
| 表 | 索引庫(6.0以後淡化了 Type 的概念,9.0將會取締) |
| 欄位 | 欄位 |
| 行記錄 | 文件 |
建立對映就是指定文件中包括的欄位
PUT http://localhost:9200/索引庫名稱/型別名稱/_mapping這裡我們使用的 ES 版本是 6.2.1 雖然已經弱化 Type 的概念,但是並沒有完全刪除,所以我們可以起一個沒有任何意義的名稱作為 Type
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text"
},
"studymodel": {
"type": "keyword"
}
}
}如果想查詢對映,將 put 請求切換成 get 請求即可
新增文件
請求格式:
POST http://localhost:9200/索引名/型別名/id值如果不指定 id 值 ES 會自動生成 ID
{
"name":"Bootstrap開發框架",
"description":"Bootstrap是由Twitter推出的一個前臺頁面開發框架,在行業之中使用較為廣泛。此開發框架包含了大量的CSS、JS程式程式碼,可以幫助開發者(尤其是不擅長頁面開發的程式人員)輕鬆的實現一個不受瀏覽器限制的精美介面效果。",
"studymodel":"201001"
}搜尋文件
根據ID查詢文件:
GET http://localhost:9200/ysx_course/doc/gf7ic2wBmvkgEzxNIJl0查詢全部文件
GET http://localhost:9200/ysx_course/doc/_search根據 name 欄位查詢。查詢的結果匹配度越高越靠前
GET http://localhost:9200/ysx_course/doc/_search?q=name:XXX
http://localhost:9200/ysx_course/doc/_search?q=name:Spring查詢到的結果
{
"took": 3, // 本次操作花費的時間/ms
"timed_out": false, // 請求是否超時
"_shards": {
"total": 1, // 查詢到的結果數
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1, // 符合條件的文件總數
"max_score": 0.9530774, // 文件匹配得分,這裡為最高分
"hits": [ // 匹配度較高的前N個文件
{
"_index": "ysx_course",
"_type": "doc",
"_id": "gf7ic2wBmvkgEzxNIJl0",
"_score": 0.9530774, // 每個文件都有一個匹配度得分,按照降序排列
"_source": { // 顯示了文件的原始內容
"name": "Spring",
"description": "...",
"studymodel": "201001"
}
}
]
}
}IK 分詞器
因為 ES 是老外開發的,對中文的支援非常雞肋,例如:傳送請求測試原始分詞效果
POST localhost:9200/_analyze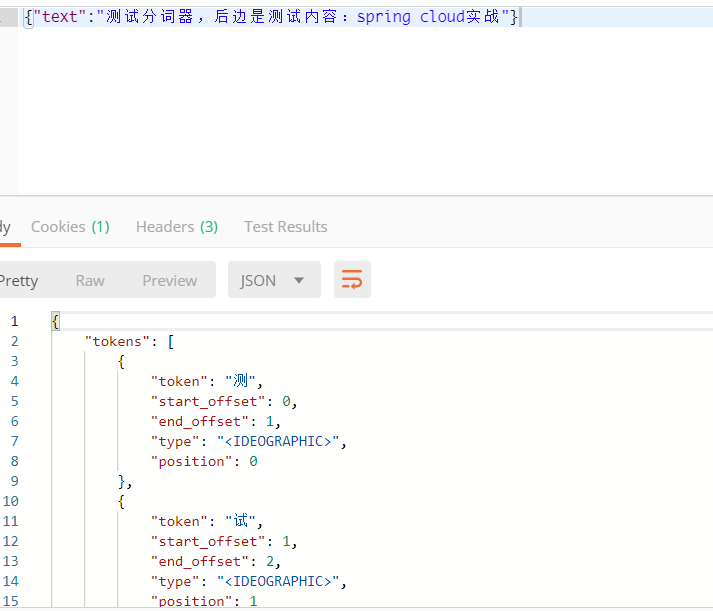
可以發現,ES 原始分詞器將每個中文字都認為是一個詞,這完全不符合我們的要求,因此我們需要安裝中文分詞器
下載IK
GITHUB 地址:https://github.com/medcl/elasticsearch-analysis-ik
安裝
解壓,並將解壓的檔案拷貝到ES安裝目錄的plugins下的ik目錄下
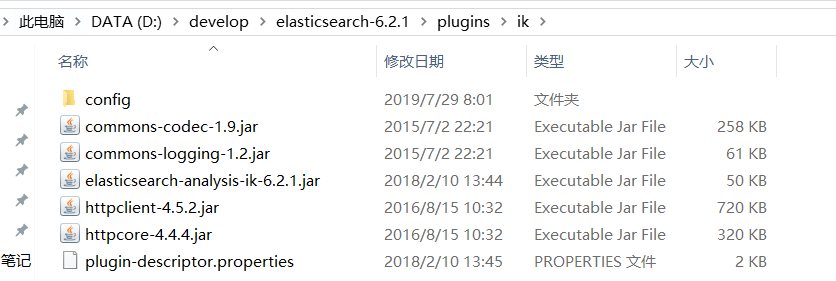
重啟ES測試
重新發送 HTTP 請求
POST localhost:9200/_analyze在 JSON 資料中新增引數:
{"text":"中華人民共和國人民大會堂","analyzer":"ik_max_word"}對於 analyzer 屬性,是 ik 的分詞模式。有兩種取值:
- ik_max_word : 細粒度分詞,如上面的文件會被分為: 中華人民共和國、中華、人民、共和國、華人...
- ik_smart : 粗粒度分詞,中華人民共和國、人民大會堂。
自定義詞庫
對於一些我們網站自己用到的/非常見詞條。我們就需要進行自定義詞庫了,怎麼實現呢?
- 開啟 ik 資料夾下 config 目錄,IKAnalyzer.cfg.xml 檔案。可以清楚的看出這個檔案中可以配置自定義詞庫。這裡我們在同級目錄下建立 my.dic 檔案
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 擴充套件配置</comment>
<!--使用者可以在這裡配置自己的擴充套件字典 -->
<entry key="ext_dict">my.dic</entry>
<!--使用者可以在這裡配置自己的擴充套件停止詞字典-->
<entry key="ext_stopwords"></entry>
<!--使用者可以在這裡配置遠端擴充套件字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--使用者可以在這裡配置遠端擴充套件停止詞字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
- 在 my.dic 檔案中,每一行輸入一個詞條,並且儲存成 無BOM UTF-8 格式檔案。
- 重啟 ES,進行測試
對映維護
說明
ES 支援對映的新增,但不支援已有欄位的更新,如果非要進行更新,就需要刪除索引庫然後建立新的索引庫。。。
常用對映型別
字串: text
analyzer:屬性指定分詞器,下邊指定name的欄位型別為text,使用ik分詞器的ik_max_word分詞模式
"name": {
"type": "text",
"analyzer":"ik_max_word"
}上邊指定了analyzer是指在索引和搜尋都使用ik_max_word,如果單獨想定義搜尋時使用的分詞器則可以通過
search_analyzer屬性.對於ik分詞器建議是索引時使用 ik_max_word 將搜尋內容進行細粒度分詞,搜尋時使用 ik_smart 提高搜尋精確性。最終的 JSON 資料如下:
"name": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
}index:該屬性指定是否索引。預設是 true ,但是對於一些不用於搜尋的欄位,如圖片 url ,就可以設定為 false
store:是否在source之外儲存,每個文件索引後會在 ES中儲存一份原始文件,存放在"_source"中,一般情況下不需要設定store為true,因為在_source中已經有一份原始文件了
字串: keyword
keyword 定義的欄位表示關鍵字搜尋,是進行整體的搜尋,在建立keyword時索引是不進行分詞的,比如:郵編、身份證號、手機號等。keyword 欄位通常用於過濾、排序、聚合等
日期: date
日期型別不用設定分詞器。通常日期型別的欄位用於排序。
format:通過format設定日期格式
{
"properties": {
"timestamp": {
"type": "date",
"format": "yyyy‐MM‐dd HH:mm:ss||yyyy‐MM‐dd" // 日期格式化
}
}
}數值型別
ES 支援的數值型別有這麼多:

在建立數值型別欄位時,有以下幾點建議:
- 儘量選擇範圍小的型別,以提高搜尋效率
- 對於浮點數,儘量使用比例因子。例如金錢,設定比例因子為100,則 23.45 元會儲存為 2345 分。如果輸入的是 23.456 ES就會將它 * 100 然後四捨五入,儲存成 2346 .使用比例因子的好處是整型比浮點型更易壓縮,節省磁碟空間
"price": {
"type": "scaled_float",
"scaling_factor": 100
},- 如果比例因子不適合,則從下表中選擇合適的型別
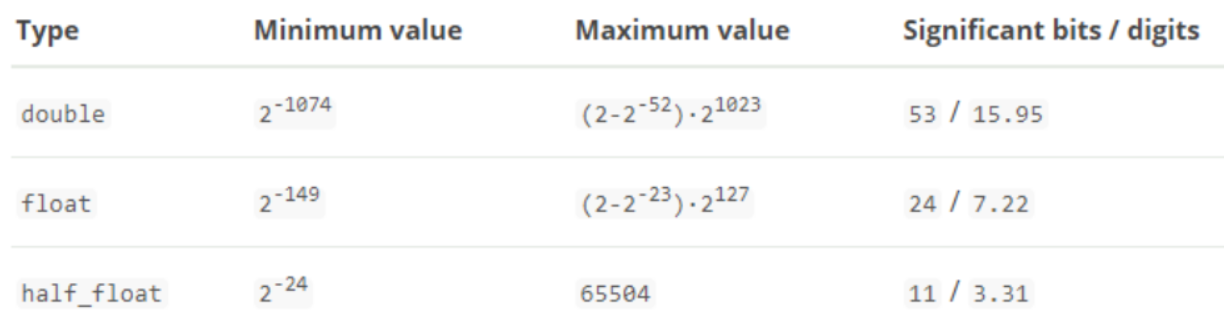
相關推薦
elasticsearch基礎知識以及建立索引
一、基礎概念:
1、索引:
索引(index)是elasticsearch的一個邏輯儲存,可以理解為關係型資料庫中的資料庫,es可以把索引資料存放到一臺伺服器上,也可以sharding後存到多臺伺服器上,每個索引有一個或多個分片,每個分片可以有多個副本。
2、索引型別(in
ElasticSearch基礎知識
簡介
ElasticSearch(以下簡稱ES)是一個基於Lucene的搜尋伺服器,它提供了一個分散式多使用者能力的全文搜尋引擎。基於RESTful web介面。要想深入瞭解 ES,需要先對 Lucene 有一個清晰的認識,那麼什麼是 Lucene 呢?
Lucene
普通資料庫的缺陷:
沒有高效的索引方式
Elasticsearch中document的基礎知識
元數據 不同 一個 返回 document elastics nbsp test 唯一標識 寫在前面的話:讀書破萬卷,編碼如有神--------------------------------------------------------------------
參考內容
Elasticsearch學習筆記(四)—基礎知識
1 幾個定義
1.1 index
索引(名詞) 一個索引類似於傳統關係資料庫中的一個 資料庫 ,是一個儲存關係型文件的地方。 索引 (index) 的複數詞為 indices 或 indexes 。
ElasticSearch學習19_搜尋引擎-倒排索引基礎知識
搜尋引擎的索引
1.單詞——文件矩陣
單詞-文件矩陣是表達兩者之間所具有的一種包含關係的概念模型,圖3-1展示了其含義。圖3-1的每列代表一個文件,每行代表一個單詞,打對勾的位置代表包含關係。
Elasticsearch入門篇——基礎知識
開發十年,就只剩下這套架構體系了!
>>>
Spring 基礎知識 - 依賴註入
ans factory control 自己 int pac java str actor 所謂的依賴註入是指容器負責創建對象和維護對象間的依賴關系,而不是通過對象本身負責自己的創建和解決自己的依賴。
依賴註入主要目的是為了解耦,體現了一種“組合”的理念。
無論是xml配置
Java基礎知識二次學習--第八章 流
cti 註意 spa 基礎 2個 cnblogs images 方向 視頻 第八章 流
時間:2017年4月28日11:03:07~2017年4月28日11:41:54
章節:08章_01節
視頻長度:21:15
內容:IO初步
心得:
所有的流在java.io包裏面
UVM系統驗證基礎知識0(Questasim搭建第一個UVM環境)
art otto quest 運行 microsoft href lin html clas
版權聲明:本文為Times_poem原創文章,轉載請告知原博主。特別聲明:本文在原文基礎上做了簡單修改以適應文中舉例在questasim下的運行,敬請原博主諒解。
需求說明:
javascript基礎知識整理(不定時更新)
nsh firefox 可用 splice mage true size -1 對數
1.js中真與假的定義:
真:true,非零數字,非空字符串,非空對象
假:false,數字零,空字符串,空對象(null),undefined
2.使用for循環對json進
C#基礎知識-函數的定義和調用(五)
返回 {0} string 訪問修飾符 容器 列表 rdquo 所有 func 函數也可以稱為方法,可以很方便的把一些行為封裝到函數裏面,當調用這一函數時會把函數塊裏面的代碼按照順序執行,方法可以有多種形式,有無參數,有無返回值等。
1. 函數的定義
函數定
C#基礎知識-流程控制的應用(四)
相關 ats 循環 nbsp 使用 logs 嘗試 exc 設置斷點 流程控制我們在編程中運用到的地方非常的多,在上篇中僅僅只是簡單的介紹每一種的使用,並沒有運用到實例中,很難去理解它真正的作用。下面我們將實際的運用流程控制的代碼寫一些實例相關的程序,加深對流程控制的理解,
java基礎知識應用--雙色球開獎號碼
雙色球開獎 java基礎 開獎號碼 public 雙色球是中國福利彩票的玩法,雙色球分為紅色球號碼區和藍色球號碼區,紅色球號碼區由1-33共33個號碼組成,藍色球號碼區由1-16共16個號碼組成,開獎號碼由6個不重復的紅色球號碼和1個藍色球號碼共7個數組成。 首先要設置三個數組來分別保存
redis的一些分散的基礎知識
redis基礎知識 ant風格 redis簡單命令 中午的時候學了redis一些基礎操作,簡單記錄一下,方便記憶1、redis是一種基於內存也可以持久化的 key - value分布式數據具,默認設置數據庫的數量為 16 個。如圖示,redis.conf配置文件中寫到,默認的數據庫的 db
網絡相關基礎知識
html tro 綜合布線 裝修公司 轉化 blog scn www 不同 1. Q:強電跟弱電怎麽區分?
A1:強電和弱電是俗稱了,工程上強電一般指的是建築電力安裝,照明、插座、配電房,根據各國的標準不同,基本上施工的都是110V或220的電力設備、管線安裝。
弱電是指消
c語言-樹的基礎知識(一)
相交 ges 最大 .cn nbsp 分享 blog com lin 第一、樹的定義: 1.有且只有一個稱為根的節點 2.有若幹個互不相交的子樹,這些子樹本身也是一顆樹
第二、專業術語:
樹的深度:從根節點到最低層,節點的層數 ,稱之為樹的深度。
最完整的Elasticsearch 基礎教程
epo -o 小寫 名稱 搜索結果 博客 需要 必須 搜索api 基礎概念
Elasticsearch有幾個核心概念。從一開始理解這些概念會對整個學習過程有莫大的幫助。 接近實時(NRT) Elasticsearch是一個接近實時的搜索平臺。這意
前端基礎知識總結
pla 部分 一個 知識 法則 總結 情況 元素 保存 一、html中alt和title的區別
1.alt是圖片的屬性值,當圖片無法加載的時候,會用alt屬性的值來替換圖片。
2.而title是圖片的標題,當鼠標移動到圖片上時,會顯示圖片的名稱。
[email
Redux學習筆記-基礎知識
事件處理 學習筆記 情況 分發 .org 新的 分數 class 特點 p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 18.0px "Helvetica Neue"; color: #404040 }
p.p2 { margin
jQuery筆記——基礎知識
就會 col cti 獲得 通過 重要 我們 class mic jQuery是一個JavaScript庫,它通過封裝原生的JavaScript函數得到一整套定義好的方法。在jQuery程序中,不管是頁面元素的選擇、內置的功能函數,都是美元符號“$”
elasticsearch基礎知識以及建立索引
一、基礎概念: 1、索引: 索引(index)是elasticsearch的一個邏輯儲存,可以理解為關係型資料庫中的資料庫,es可以把索引資料存放到一臺伺服器上,也可以sharding後存到多臺伺服器上,每個索引有一個或多個分片,每個分片可以有多個副本。 2、索引型別(in
ElasticSearch基礎知識
簡介 ElasticSearch(以下簡稱ES)是一個基於Lucene的搜尋伺服器,它提供了一個分散式多使用者能力的全文搜尋引擎。基於RESTful web介面。要想深入瞭解 ES,需要先對 Lucene 有一個清晰的認識,那麼什麼是 Lucene 呢? Lucene 普通資料庫的缺陷: 沒有高效的索引方式
Elasticsearch中document的基礎知識
元數據 不同 一個 返回 document elastics nbsp test 唯一標識 寫在前面的話:讀書破萬卷,編碼如有神-------------------------------------------------------------------- 參考內容
Elasticsearch學習筆記(四)—基礎知識
1 幾個定義 1.1 index 索引(名詞) 一個索引類似於傳統關係資料庫中的一個 資料庫 ,是一個儲存關係型文件的地方。 索引 (index) 的複數詞為 indices 或 indexes 。
ElasticSearch學習19_搜尋引擎-倒排索引基礎知識
搜尋引擎的索引 1.單詞——文件矩陣 單詞-文件矩陣是表達兩者之間所具有的一種包含關係的概念模型,圖3-1展示了其含義。圖3-1的每列代表一個文件,每行代表一個單詞,打對勾的位置代表包含關係。
Elasticsearch入門篇——基礎知識
開發十年,就只剩下這套架構體系了! >>>
Spring 基礎知識 - 依賴註入
ans factory control 自己 int pac java str actor 所謂的依賴註入是指容器負責創建對象和維護對象間的依賴關系,而不是通過對象本身負責自己的創建和解決自己的依賴。 依賴註入主要目的是為了解耦,體現了一種“組合”的理念。 無論是xml配置
Java基礎知識二次學習--第八章 流
cti 註意 spa 基礎 2個 cnblogs images 方向 視頻 第八章 流 時間:2017年4月28日11:03:07~2017年4月28日11:41:54 章節:08章_01節 視頻長度:21:15 內容:IO初步 心得: 所有的流在java.io包裏面
UVM系統驗證基礎知識0(Questasim搭建第一個UVM環境)
art otto quest 運行 microsoft href lin html clas 版權聲明:本文為Times_poem原創文章,轉載請告知原博主。特別聲明:本文在原文基礎上做了簡單修改以適應文中舉例在questasim下的運行,敬請原博主諒解。 需求說明:
javascript基礎知識整理(不定時更新)
nsh firefox 可用 splice mage true size -1 對數 1.js中真與假的定義: 真:true,非零數字,非空字符串,非空對象 假:false,數字零,空字符串,空對象(null),undefined 2.使用for循環對json進
C#基礎知識-函數的定義和調用(五)
返回 {0} string 訪問修飾符 容器 列表 rdquo 所有 func 函數也可以稱為方法,可以很方便的把一些行為封裝到函數裏面,當調用這一函數時會把函數塊裏面的代碼按照順序執行,方法可以有多種形式,有無參數,有無返回值等。 1. 函數的定義 函數定
C#基礎知識-流程控制的應用(四)
相關 ats 循環 nbsp 使用 logs 嘗試 exc 設置斷點 流程控制我們在編程中運用到的地方非常的多,在上篇中僅僅只是簡單的介紹每一種的使用,並沒有運用到實例中,很難去理解它真正的作用。下面我們將實際的運用流程控制的代碼寫一些實例相關的程序,加深對流程控制的理解,
java基礎知識應用--雙色球開獎號碼
雙色球開獎 java基礎 開獎號碼 public 雙色球是中國福利彩票的玩法,雙色球分為紅色球號碼區和藍色球號碼區,紅色球號碼區由1-33共33個號碼組成,藍色球號碼區由1-16共16個號碼組成,開獎號碼由6個不重復的紅色球號碼和1個藍色球號碼共7個數組成。 首先要設置三個數組來分別保存
redis的一些分散的基礎知識
redis基礎知識 ant風格 redis簡單命令 中午的時候學了redis一些基礎操作,簡單記錄一下,方便記憶1、redis是一種基於內存也可以持久化的 key - value分布式數據具,默認設置數據庫的數量為 16 個。如圖示,redis.conf配置文件中寫到,默認的數據庫的 db
網絡相關基礎知識
html tro 綜合布線 裝修公司 轉化 blog scn www 不同 1. Q:強電跟弱電怎麽區分? A1:強電和弱電是俗稱了,工程上強電一般指的是建築電力安裝,照明、插座、配電房,根據各國的標準不同,基本上施工的都是110V或220的電力設備、管線安裝。 弱電是指消
c語言-樹的基礎知識(一)
相交 ges 最大 .cn nbsp 分享 blog com lin 第一、樹的定義: 1.有且只有一個稱為根的節點 2.有若幹個互不相交的子樹,這些子樹本身也是一顆樹 第二、專業術語: 樹的深度:從根節點到最低層,節點的層數 ,稱之為樹的深度。
最完整的Elasticsearch 基礎教程
epo -o 小寫 名稱 搜索結果 博客 需要 必須 搜索api 基礎概念 Elasticsearch有幾個核心概念。從一開始理解這些概念會對整個學習過程有莫大的幫助。 接近實時(NRT) Elasticsearch是一個接近實時的搜索平臺。這意
前端基礎知識總結
pla 部分 一個 知識 法則 總結 情況 元素 保存 一、html中alt和title的區別 1.alt是圖片的屬性值,當圖片無法加載的時候,會用alt屬性的值來替換圖片。 2.而title是圖片的標題,當鼠標移動到圖片上時,會顯示圖片的名稱。 [email
Redux學習筆記-基礎知識
事件處理 學習筆記 情況 分發 .org 新的 分數 class 特點 p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 18.0px "Helvetica Neue"; color: #404040 } p.p2 { margin
jQuery筆記——基礎知識
就會 col cti 獲得 通過 重要 我們 class mic jQuery是一個JavaScript庫,它通過封裝原生的JavaScript函數得到一整套定義好的方法。在jQuery程序中,不管是頁面元素的選擇、內置的功能函數,都是美元符號“$”