
ElasticSearch學習19_搜尋引擎-倒排索引基礎知識
搜尋引擎的索引
1.單詞——文件矩陣
單詞-文件矩陣是表達兩者之間所具有的一種包含關係的概念模型,圖3-1展示了其含義。圖3-1的每列代表一個文件,每行代表一個單詞,打對勾的位置代表包含關係。

圖3-1 單詞-文件矩陣
從縱向即文件這個維度來看,每列代表文件包含了哪些單詞,比如文件1包含了詞彙1和詞彙4,而不包含其它單詞。從橫向即單詞這個維度來看,每行代表了哪些文件包含了某個單詞。比如對於詞彙1來說,文件1和文件4中出現過單詞1,而其它文件不包含詞彙1。矩陣中其它的行列也可作此種解讀。
搜尋引擎的索引其實就是實現“單詞-文件矩陣”的具體資料結構。可以有不同的方式來實現上述概念模型,比如“倒排索引”、“簽名檔案”、“字尾樹”等方式。但是各項實驗資料表明,“倒排索引”是實現單詞到文件對映關係的最佳實現方式,所以本章主要介紹“倒排索引”的技術細節。
2.倒排索引基本概念
文件(Document):一般搜尋引擎的處理物件是網際網路網頁,而文件這個概念要更寬泛些,代表以文字形式存在的儲存物件,相比網頁來說,涵蓋更多種形式,比如Word,PDF,html,XML等不同格式的檔案都可以稱之為文件。再比如一封郵件,一條簡訊,一條微博也可以稱之為文件。在本書後續內容,很多情況下會使用文件來表徵文字資訊。
文件集合(Document Collection):由若干文件構成的集合稱之為文件集合。比如海量的網際網路網頁或者說大量的電子郵件都是文件集合的具體例子。
文件編號(Document ID):在搜尋引擎內部,會將文件集合內每個文件賦予一個唯一的內部編號,以此編號來作為這個文件的唯一標識,這樣方便內部處理,每個文件的內部編號即稱之為“文件編號”,後文有時會用DocID來便捷地代表文件編號。
單詞編號(Word ID):與文件編號類似,搜尋引擎內部以唯一的編號來表徵某個單詞,單詞編號可以作為某個單詞的唯一表徵。
倒排索引(Inverted Index)
單詞詞典(Lexicon):搜尋引擎的通常索引單位是單詞,單詞詞典是由文件集合中出現過的所有單詞構成的字串集合,單詞詞典內每條索引項記載單詞本身的一些資訊以及指向“倒排列表”的指標。
倒排列表(PostingList):倒排列表記載了出現過某個單詞的所有文件的文件列表及單詞在該文件中出現的位置資訊,每條記錄稱為一個倒排項(Posting)。根據倒排列表,即可獲知哪些文件包含某個單詞。
倒排檔案(Inverted File):所有單詞的倒排列表往往順序地儲存在磁碟的某個檔案裡,這個檔案即被稱之為倒排檔案,倒排檔案是儲存倒排索引的物理檔案。
關於這些概念之間的關係,通過圖3-2可以比較清晰的看出來。

圖3-2 倒排索引基本概念示意圖
3.倒排索引簡單例項
倒排索引從邏輯結構和基本思路上來講非常簡單。下面我們通過具體例項來進行說明,使得讀者能夠對倒排索引有一個巨集觀而直接的感受。
假設文件集合包含五個文件,每個文件內容如圖3-3所示,在圖中最左端一欄是每個文件對應的文件編號。我們的任務就是對這個文件集合建立倒排索引。

圖3-3 文件集合
中文和英文等語言不同,單詞之間沒有明確分隔符號,所以首先要用分詞系統將文件自動切分成單詞序列。這樣每個文件就轉換為由單詞序列構成的資料流,為了系統後續處理方便,需要對每個不同的單詞賦予唯一的單詞編號,同時記錄下哪些文件包含這個單詞,在如此處理結束後,我們可以得到最簡單的倒排索引(參考圖3-4)。在圖3-4中,“單詞ID”一欄記錄了每個單詞的單詞編號,第二欄是對應的單詞,第三欄即每個單詞對應的倒排列表。比如單詞“谷歌”,其單詞編號為1,倒排列表為{1,2,3,4,5},說明文件集合中每個文件都包含了這個單詞。
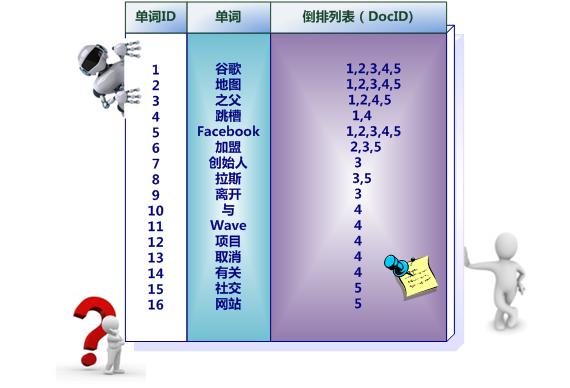
圖3-4 簡單的倒排索引
之所以說圖3-4所示倒排索引是最簡單的,是因為這個索引系統只記載了哪些文件包含某個單詞,而事實上,索引系統還可以記錄除此之外的更多資訊。圖3-5是一個相對複雜些的倒排索引,與圖3-4的基本索引系統比,在單詞對應的倒排列表中不僅記錄了文件編號,還記載了單詞頻率資訊(TF),即這個單詞在某個文件中的出現次數,之所以要記錄這個資訊,是因為詞頻資訊在搜尋結果排序時,計算查詢和文件相似度是很重要的一個計算因子,所以將其記錄在倒排列表中,以方便後續排序時進行分值計算。在圖3-5的例子裡,單詞“創始人”的單詞編號為7,對應的倒排列表內容為:(3:1),其中的3代表文件編號為3的文件包含這個單詞,數字1代表詞頻資訊,即這個單詞在3號文件中只出現過1次,其它單詞對應的倒排列表所代表含義與此相同。

圖3-5 帶有單詞頻率資訊的倒排索引
實用的倒排索引還可以記載更多的資訊,圖3-6所示索引系統除了記錄文件編號和單詞頻率資訊外,額外記載了兩類資訊,即每個單詞對應的“文件頻率資訊”(對應圖3-6的第三欄)以及在倒排列表中記錄單詞在某個文件出現的位置資訊。
 圖3-6 帶有單詞頻率、文件頻率和出現位置資訊的倒排索引
圖3-6 帶有單詞頻率、文件頻率和出現位置資訊的倒排索引
“文件頻率資訊”代表了在文件集合中有多少個文件包含某個單詞,之所以要記錄這個資訊,其原因與單詞頻率資訊一樣,這個資訊在搜尋結果排序計算中是非常重要的一個因子。而單詞在某個文件中出現的位置資訊並非索引系統一定要記錄的,在實際的索引系統裡可以包含,也可以選擇不包含這個資訊,之所以如此,因為這個資訊對於搜尋系統來說並非必需的,位置資訊只有在支援“短語查詢”的時候才能夠派上用場。
以單詞“拉斯”為例,其單詞編號為8,文件頻率為2,代表整個文件集合中有兩個文件包含這個單詞,對應的倒排列表為:{(3;1;<4>),(5;1;<4>)},其含義為在文件3和文件5出現過這個單詞,單詞頻率都為1,單詞“拉斯”在兩個文件中的出現位置都是4,即文件中第四個單詞是“拉斯”。
圖3-6所示倒排索引已經是一個非常完備的索引系統,實際搜尋系統的索引結構基本如此,區別無非是採取哪些具體的資料結構來實現上述邏輯結構。
有了這個索引系統,搜尋引擎可以很方便地響應使用者的查詢,比如使用者輸入查詢詞“Facebook”,搜尋系統查詢倒排索引,從中可以讀出包含這個單詞的文件,這些文件就是提供給使用者的搜尋結果,而利用單詞頻率資訊、文件頻率資訊即可以對這些候選搜尋結果進行排序,計算文件和查詢的相似性,按照相似性得分由高到低排序輸出,此即為搜尋系統的部分內部流程,具體實現方案本書第五章會做詳細描述。
4. 單詞詞典
單詞詞典是倒排索引中非常重要的組成部分,它用來維護文件集合中出現過的所有單詞的相關資訊,同時用來記載某個單詞對應的倒排列表在倒排檔案中的位置資訊。在支援搜尋時,根據使用者的查詢詞,去單詞詞典裡查詢,就能夠獲得相應的倒排列表,並以此作為後續排序的基礎。
對於一個規模很大的文件集合來說,可能包含幾十萬甚至上百萬的不同單詞,能否快速定位某個單詞,這直接影響搜尋時的響應速度,所以需要高效的資料結構來對單詞詞典進行構建和查詢,常用的資料結構包括雜湊加連結串列結構和樹形詞典結構。
4.1 雜湊加連結串列
圖1-7是這種詞典結構的示意圖。這種詞典結構主要由兩個部分構成:
主體部分是雜湊表,每個雜湊表項儲存一個指標,指標指向衝突連結串列,在衝突連結串列裡,相同雜湊值的單詞形成連結串列結構。之所以會有衝突連結串列,是因為兩個不同單詞獲得相同的雜湊值,如果是這樣,在雜湊方法裡被稱做是一次衝突,可以將相同雜湊值的單詞儲存在連結串列裡,以供後續查詢。

圖1-7 雜湊加連結串列詞典結構
在建立索引的過程中,詞典結構也會相應地被構建出來。比如在解析一個新文件的時候,對於某個在文件中出現的單詞T,首先利用雜湊函式獲得其雜湊值,之後根據雜湊值對應的雜湊表項讀取其中儲存的指標,就找到了對應的衝突連結串列。如果衝突連結串列裡已經存在這個單詞,說明單詞在之前解析的文件裡已經出現過。如果在衝突連結串列裡沒有發現這個單詞,說明該單詞是首次碰到,則將其加入衝突連結串列裡。通過這種方式,當文件集合內所有文件解析完畢時,相應的詞典結構也就建立起來了。
在響應使用者查詢請求時,其過程與建立詞典類似,不同點在於即使詞典裡沒出現過某個單詞,也不會新增到詞典內。以圖1-7為例,假設使用者輸入的查詢請求為單詞3,對這個單詞進行雜湊,定位到雜湊表內的2號槽,從其保留的指標可以獲得衝突連結串列,依次將單詞3和衝突連結串列內的單詞比較,發現單詞3在衝突連結串列內,於是找到這個單詞,之後可以讀出這個單詞對應的倒排列表來進行後續的工作,如果沒有找到這個單詞,說明文件集合內沒有任何文件包含單詞,則搜尋結果為空。
4.2 樹形結構
B樹(或者B+樹)是另外一種高效查詢結構,圖1-8是一個 B樹結構示意圖。B樹與雜湊方式查詢不同,需要字典項能夠按照大小排序(數字或者字元序),而雜湊方式則無須資料滿足此項要求。
B樹形成了層級查詢結構,中間節點用於指出一定順序範圍的詞典專案儲存在哪個子樹中,起到根據詞典項比較大小進行導航的作用,最底層的葉子節點儲存單詞的地址資訊,根據這個地址就可以提取出單詞字串。

圖1-8 B樹查詢結構
參考文獻:
《這就是搜尋引擎:核心技術詳解》第三章
原文來自:http://blog.csdn.net/hguisu/article/details/7962350