
命名實體如何進行概念消歧?
1 引言
命名實體概念消歧是命名實體消歧(英語:Named Entity Disambiguation)的一個重要研究子領域(命名實體概念可見本文3.1章)。什麼叫概念消歧了?在這裡舉一個簡單例子進行說明,一個命名實體“天龍八部”,它有許多個不同的含義,其中有電視劇類的含義,電視劇含義有好幾個,如“1997黃日華版電視劇”、“1982年TVB版本電視劇”、“2003年內地胡軍版電視劇”、“”2013年內地版電視劇“等;其中有漫畫類的含義,漫畫含義有好幾個,如“騰訊動漫的漫畫”、“黃玉郎改編的漫畫”。雖然電視劇類的含義有好幾個,但這些含義都是同一個概念,它們都屬於“電視劇”這個概念。

圖1 不同的含義的天龍八部
因此命名實體概念消歧的任務是識別一段文字中給定的命名實體到底屬於哪一個概念。例如有下面3個文字。
| 文字 | 含義 | 概念 | |
|---|---|---|---|
| A | 港版天龍八部還是經典啊,黃日華才演出蕭峰的氣質 | 97黃日華版電視劇 | 電視劇 |
| B | 我是張紀中的鐵桿粉絲,我當然喜歡天龍八部啦 | 03內地胡軍版電視劇 | 電視劇 |
| C | 我喜歡香港漫畫,如《天子傳奇》《天龍八部》 | 黃玉郎改編的漫畫 | 漫畫 |
文字A中天龍八部是“1997黃日華版電視劇”,文字B中天龍八部是“2003年內地胡軍版電視劇”,文字C中的天龍八部是“黃玉郎改編的漫畫”。雖然文字A和文字B中的天龍八部不是同一個意思,但文字A和文字B中的天龍八部都是同一個概念類別,都是“電視劇“的天龍八部。那麼概念消歧做的任務就是將文字A和文字B中的天龍八部都劃分到“電視劇”這一概念中,將文字C中的天龍八部劃分到“漫畫”這一概念中。
接下來本文簡單介紹如何對命名實體進行概念消歧。
2 概念消歧流程
2.1 實體全體含義的獲取
本文以天龍八部百度百科為資料來源進行說明,首先要獲取天龍八部這個實體所有含義的“描述”文字和“屬性”表格,如下為天龍八部其中一個含義——1997黃日華版電視劇的“描述”文字和“屬性”表格。
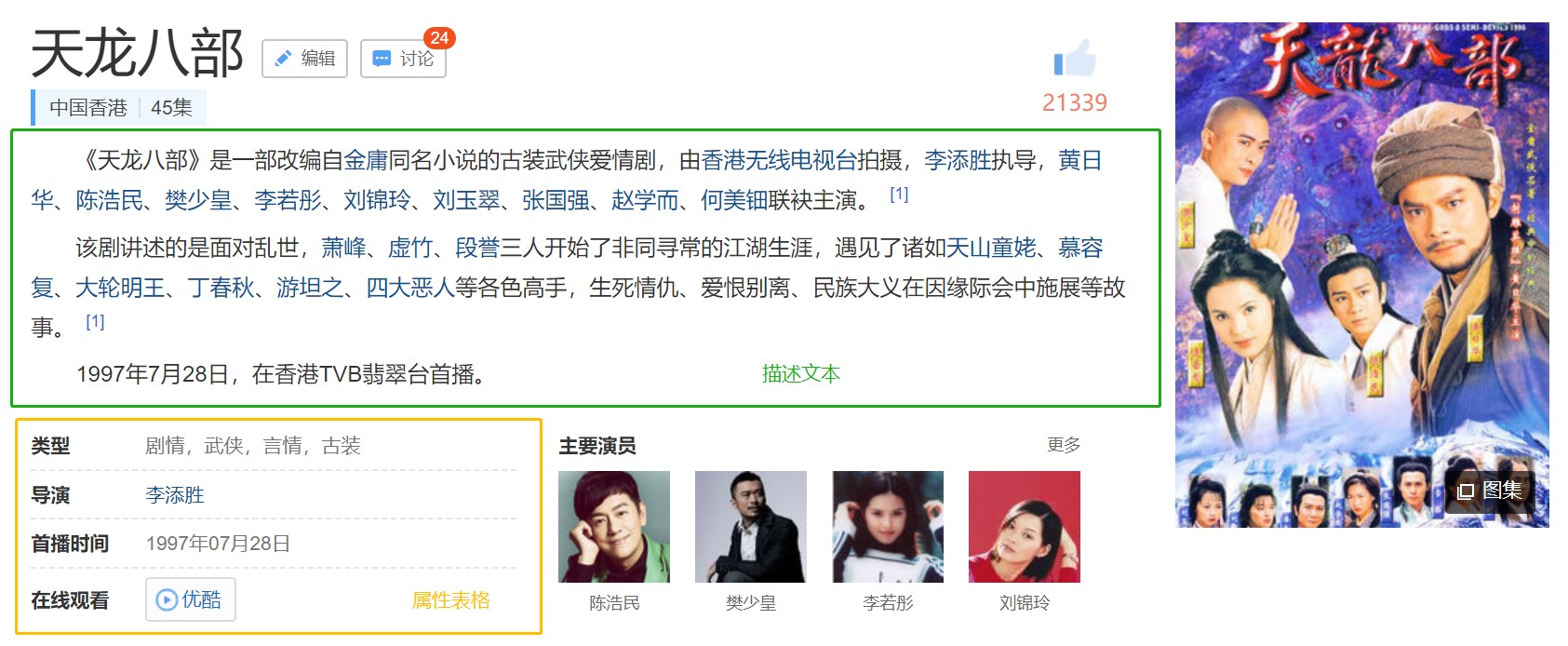
圖2 需要爬取1997黃日華版電視劇的內容
2.2 文字分詞構建關鍵詞片語
得到每一個含義的“描述”文字和“屬性”表格後,利用jieba分詞工具對描述本文“《天龍八部》是一部改編自金庸同名小的古裝愛情劇,由香港無線電視臺……”進行分詞處理,得到一些列詞語構成的list1。然後從“屬性”表格中提取“劇情,武俠,言情,古裝”和“李添勝”等屬性詞,這些屬性詞又構成list2。接著合併list1和list2,就可以得到“1997黃日華版電視劇“含義的關鍵詞片語。
對天龍八部每一個含義都進行如下處理,我們可得到如下所示的表格
| 含義 | 關鍵詞片語 |
|---|---|
| 97黃日華版電視劇 | ["1997", "李添勝", "天龍八部", "黃日華", "樊少皇", "張國強", "陳浩民", "李若彤", "劉錦玲", "趙學而", "何美鈿", "28", "陳國樑", "香港", "金庸", "武俠", "古裝", "劉玉翠", "蕭峰", "慕容復"] |
| 03內地胡軍版電視劇 | ["電視劇", "2003", "古裝", "于敏", "劉亦菲", "鞠覺亮", "周曉文", "趙箭", "林志穎", "12", "11", "22", "金鷹獎", "天龍八部", "高虎", "胡軍", "劉濤", "陳好", "張紀中", "優秀作品"] |
| 82版香港電視劇 | ["虛竹", "1982", "天龍八部", "神劍", "黃日華", "黃杏秀", "之六脈", "蕭笙", "樑家仁", "湯鎮業", "陳玉蓮", "石修", "TVB", "03", "22", "傳奇", "武俠", "中國香港", "香港", "喬峰"] |
| 黃玉郎改編的漫畫 | ["武林", "喬峰", "幫主", "黃玉郎", "天龍八部", "威名", "丐幫", "虛竹", "段家", "英雄輩出", "大宋", "他族", "大幫", "北喬峰", "之妻", "康敏", "墮地", "段譽", "胡紹權", "風雲際會"] |
| 騰訊動漫的漫畫 | ["漫畫作品", "天龍八部", "連載", "騰訊", "動漫", "鳳凰", "娛樂", "創作"] |
| …… | …… |
2.3 概念抽取和歸併
上提及的“電視劇”、“漫畫”這些概念不是憑空而來的,它是通過下述演算法而得:
(1)含義標題分詞和詞性標註
使用jieba分詞工具對含義標題 “1997年黃日華版電視劇”進行分詞和詞性標處理。我們可得到這樣一個數組[['1997', 'm'], ['年', 'm'], ['黃日華', 'nz'], ['版', 'n'], ['電視劇', 'n']],第i個元素是一個由分詞和對用詞性組成的陣列。
(2)獲取概念候選詞
只選取上一步中獲取的名詞詞語,那麼我們可以得到['黃日華', '版', '電視劇']
(3)確定候選詞
通常含義標題最後一個名詞往往是能代表此含義具體概念類別的詞語,由上一步我們可知最後一個名詞是“電視劇“,恰好符合標題對應概念。因此可得到如下列表
| 含義 | 關鍵詞片語 | 概念 |
|---|---|---|
| 97黃日華版電視劇 | ["1997", "李添勝", "天龍八部", "黃日華", "樊少皇", "張國強", "陳浩民", "李若彤", "劉錦玲", "趙學而", "何美鈿", "28", "陳國樑", "香港", "金庸", "武俠", "古裝", "劉玉翠", "蕭峰", "慕容復"] | 電視劇 |
| 03內地胡軍版電視劇 | ["電視劇", "2003", "古裝", "于敏", "劉亦菲", "鞠覺亮", "周曉文", "趙箭", "林志穎", "12", "11", "22", "金鷹獎", "天龍八部", "高虎", "胡軍", "劉濤", "陳好", "張紀中", "優秀作品"] | 電視劇 |
| 82版香港電視劇 | ["虛竹", "1982", "天龍八部", "神劍", "黃日華", "黃杏秀", "之六脈", "蕭笙", "樑家仁", "湯鎮業", "陳玉蓮", "石修", "TVB", "03", "22", "傳奇", "武俠", "中國香港", "香港", "喬峰"] | 電視劇 |
| 黃玉郎改編的漫畫 | ["武林", "喬峰", "幫主", "黃玉郎", "天龍八部", "威名", "丐幫", "虛竹", "段家", "英雄輩出", "大宋", "他族", "大幫", "北喬峰", "之妻", "康敏", "墮地", "段譽", "胡紹權", "風雲際會"] | 漫畫 |
| 騰訊動漫的漫畫 | ["漫畫作品", "天龍八部", "連載", "騰訊", "動漫", "鳳凰", "娛樂", "創作"] | 漫畫 |
| …… | …… | …… |
得到上述列表後易知,無論是“97黃日華版電視劇”,還是“03內地胡軍版電視劇”,或者是“82版香港電視劇”它們都屬於“電視劇”概念,它們都可以聚類成為“電視劇”這個概念類別。同理” 黃玉郎改編的漫畫”和”騰訊動漫的漫畫”也可以聚類成為“漫畫”這個概念類別。因此對屬於同一個概念的含義可以進行歸併操作,即” 97黃日華版電視劇”、“03內地胡軍版電視劇”和” 82版香港電視劇”可以,可得如下的概念歸併後的

圖3 概念歸併後的片語
2.4 概念消歧
文字概念消歧分為兩個步驟,第一步獲得含義的文字向量,第二步是計算文字向量間餘弦相似度來判斷目標文字中命名實體屬於哪個概念 (餘弦相似度概念見術語解釋)。
首先介紹第一步獲得概念文字向量和目標文字向量。“電視劇”概念對應的關鍵詞片語為["1997", "李添勝", "天龍八部", "黃日華", "樊少皇", "張國強", "陳浩民", "李若彤",……],假設"1997"對應的詞向量為w1, "李添勝"對應的詞向量為w2, "天龍八部"對應的詞向量為w3,……。那麼我們可以定義“97黃日華版電視劇”的概念文字向量T1 =(w1+w2+…wn)/n。對目標文字“港版天龍八部還是經典啊,黃日華才演出蕭峰的氣質”先進行jieba分詞處理得到關鍵詞,然後按上述步驟處理可獲得目標文字向量。
通過餘弦相似度計算你會發現目標文字向量和”電視劇”概念向量文字餘弦相似度最大,所以目標文字中的概念應該對應“電視劇”這個概念。本文使用某開源的中文詞向量進行文字到向量數值的對映,此開源的中文詞向量的維度為200維度,包含幾乎所有的中文詞語和流行術語。
3 術語解釋
3.1 命名實體
命名實體(英語:Named Entity),主要包括人名、地名、機構名、專有名詞等,以及時間、數量、貨幣、比例數值等文字。指的是可以用專有名詞(名稱)標識的事物,一個命名實體一般代表唯一一個具體事物個體,包括人名、地名等。例如人名“愛因斯坦”、“牛頓”,地名“北京、“紐約”,機構名“好未來”,“清華大學”等都算一個命名實體。對命名實體的處理是NLP(英語Natural Language Processing,自然語言處理)領域一個重要的研究方向。
3.2 詞向量
詞向量(Word embedding),又叫Word嵌入式自然語言處理(NLP)中的一組語言建模和特徵學習技術的統稱,其中來自詞彙表的單詞或短語被對映到實數的向量。 從概念上講,它涉及從每個單詞一維的空間到具有更低維度的連續向量空間的數學嵌入。
3.3 餘弦相似度
餘弦相似度通過測量兩個向量內積空間的夾角的餘弦值來度量它們之間的相似性。0度角的餘弦值是1,而其他任何角度的餘弦值都不大於1。用向量空間中兩個向量夾角的餘弦值作為衡量兩個個體間差異的大小的度量,也就是衡量兩個向量在方向上的差別。
結束語
當然在詞類歸併計算的時候還存在概念重複的情況,例如天龍八部詞條中出現“1977年香港電視劇”、“2013年大陸影視劇”這時候按本文方法找到兩個“不同”的概念,即“電視劇“和”影視劇“,顯然這樣資料出現冗餘。當然這個文字也是有解決方案的,可以通過概念相似度計算、或者關鍵詞聚類來進一步優化得到的概念資料,使得我們得到的概念資料中不出現上述的問題。最後希望本文能幫助到廣大的NLPer在文字處理