
MySQL主備模式的資料一致性解決方案
根據阿里交易型業務的特點,以及在雙十一這樣業內罕有的需求推動下,我們在官方的MySQL基礎上增加了非常多實用的功能、效能補丁。而在使用MySQL的過程中,資料一致性是繞不開的話題之一。本文主要從阿里巴巴“去IOE”的後時代講起,向大家簡單介紹下我們過去幾年在MySQL資料一致性上的努力和實踐,以及目前的解決方案。
一.MySQL單機的資料一致性
MySQL作為一個可插拔的資料庫系統,支援外掛式的儲存引擎,在設計上分為Server層和Storage Engine層。
在Server層,MySQL以events的形式記錄資料庫各種操作的Binlog二進位制日誌,其基本核心作用有:複製和備份。除此之外,我們結合多樣化的業務場景需求,基於Binlog的特性構建了強大的MySQL生態,如:DTS、單元化、異構系統之間實時同步等等,Binlog早已成為MySQL生態中不可缺少的模組。而在Storage Engine層,InnoDB作為比較通用的儲存引擎,其在高可用和高效能兩方面作了較好的平衡,早已經成為使用MySQL的首選(PS:官方從MySQL 5.5.5開始,將InnoDB作為了MySQL的預設儲存引擎 )。和大多數關係型資料庫一樣,InnoDB採用WAL技術,即InnoDB Redo Log記錄了對資料檔案的物理更改,並保證總是日誌先行,在持久化資料檔案前,保證之前的redo日誌已經寫到磁碟。Binlog和InnoDB Redo Log是否落盤將直接影響例項在異常宕機後資料能恢復到什麼程度。InnoDB提供了相應的引數來控制事務提交時,寫日誌的方式和策略,例如:
innodb_flush_method:控制innodb資料檔案、日誌檔案的開啟和刷寫的方式,建議取值:fsync、O_DIRECT。
innodb_flush_log_at_trx_commit:控制每次事務提交時,重做日誌的寫盤和落盤策略,可取值:0,1,2。
當innodb_flush_log_at_trx_commit=1時,每次事務提交,日誌寫到InnoDB Log Buffer後,會等待Log Buffer中的日誌寫到Innodb日誌檔案並重新整理到磁碟上才返回成功。
sync_binlog:控制每次事務提交時,Binlog日誌多久重新整理到磁碟上,可取值:0或者n(N為正整數)。
不同取值會影響MySQL的效能和異常crash後資料能恢復的程度。當sync_binlog=1 以上引數不同的取值分別影響著MySQL異常crash後資料能恢復的程度和寫入效能,實際使用過程中,需要結合業務的特性和實際需求,來設定合理的配置。比如:
MySQL單例項,Binlog關閉場景:
innodb_flush_log_at_trx_commit=1,innodb_doublewrite=ON時,能夠保證不論是MySQL Crash 還是OS Crash 或者是主機斷電重啟都不會丟失資料。
MySQL單例項,Binlog開啟場景:
預設innodb_support_xa=ON,開啟binlog後事務提交流程會變成兩階段提交,這裡的兩階段提交併不涉及分散式事務,mysql把它稱之為內部xa事務。
當innodb_flush_log_at_trx_commit=1,sync_binlog=1,innodb_doublewrite=ON,innodb_support_xa=ON時,同樣能夠保證不論是MySQL Crash 還是OS Crash 或者是主機斷電重啟都不會丟失資料。但是,當由於主機硬體故障等原因導致主機完全無法啟動時,則MySQL單例項面臨著單點故障導致資料丟失的風險,故MySQL單例項通常不適用於生產環境。
二.MySQL叢集的資料一致性
MySQL叢集通常指MySQL的主從複製架構。通常使用MySQL主從複製來解決MySQL的單點故障問題,其通過邏輯複製的方式把主庫的變更同步到從庫,主備之間無法保證嚴格一致的模式,於是,MySQL的主從複製帶來了主從“資料一致性”的問題。
MySQL的複製分為:非同步複製、半同步複製、全同步複製。
非同步複製
主庫在執行完客戶端提交的事務後會立即將結果返給給客戶端,並不關心從庫是否已經接收並處理,這樣就會有一個問題,主如果crash掉了,此時主上已經提交的事務可能並沒有傳到從庫上,如果此時,強行將從提升為主,可能導致“資料不一致”。早期MySQL僅僅支援非同步複製。
半同步複製
MySQL在5.5中引入了半同步複製,主庫在應答客戶端提交的事務前需要保證至少一個從庫接收並寫到relay log中,半同步複製通過rpl_semi_sync_master_wait_point引數來控制master在哪個環節接收 slave ack,master 接收到 ack 後返回狀態給客戶端,此引數一共有兩個選項 AFTER_SYNC & AFTER_COMMIT。
配置為WAIT_AFTER_COMMIT
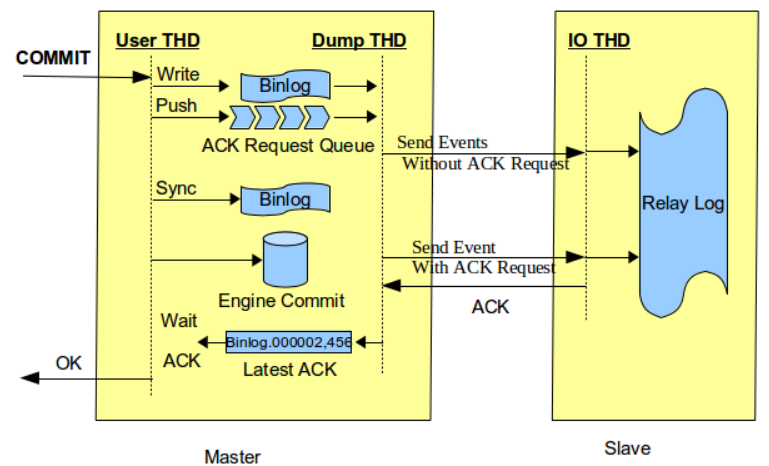
rpl_semi_sync_master_wait_point為WAIT_AFTER_COMMIT時,commitTrx的呼叫在engine層commit之後,如上圖所示。即在等待Slave ACK時候,雖然沒有返回當前客戶端,但事務已經提交,其他客戶端會讀取到已提交事務。如果Slave端還沒有讀到該事務的events,同時主庫發生了crash,然後切換到備庫。那麼之前讀到的事務就不見了,出現了資料不一致的問題,如下圖所示。圖片引自Loss-less Semi-Synchronous Replication on MySQL 5.7.2。
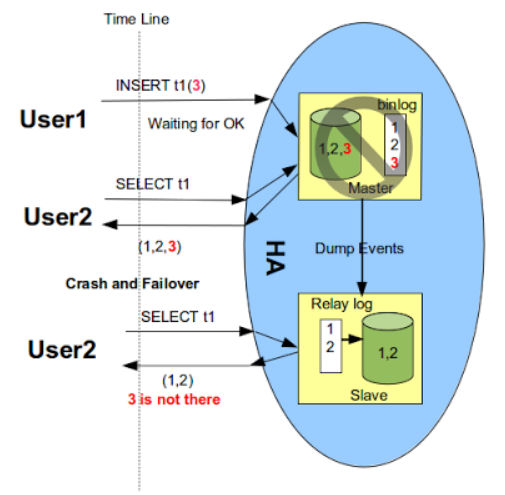
如果主庫永遠啟動不了,那麼實際上在主庫已經成功提交的事務,在從庫上是找不到的,也就是資料丟失了。
PS:早在11年前後,阿里巴巴資料庫就創新實現了在engine層commit之前等待Slave ACK的方式來解決此問題。
配置為WAIT_AFTER_SYNC
MySQL官方針對上述問題,在5.7.2引入了Loss-less Semi-Synchronous,在呼叫binlog sync之後,engine層commit之前等待Slave ACK。這樣只有在確認Slave收到事務events後,事務才會提交。如下圖所示,圖片引自Loss-less Semi-Synchronous Replication on MySQL 5.7.2 :

在after_sync模式下解決了after_commit模式帶來的資料不一致的問題,因為主庫沒有提交事務。但也會有個問題,當主庫在binlog flush並且binlog同步到了備庫之後,binlog sync之前發生了abort,那麼很明顯這個事務在主庫上是未提交成功的(由於abort之前binlog未sync完成,主庫恢復後事務會被回滾掉),但由於從庫已經收到了這些Binlog,並且執行成功,相當於在從庫上多出了資料,從而可能造成“資料不一致”。
此外,MySQL半同步複製架構中,主庫在等待備庫ack時候,如果超時會退化為非同步後,也可能導致“資料不一致”。
三.MySQL主備的“資料一致性”方案
下面簡單介紹下阿里巴巴早期在MySQL資料一致性問題的一些思考和實踐。
1.單元化架構下的“資料一致性”
背景:受機架位限制,單機房或地域總會出現容量瓶頸,業務發展受限;以及跨地域容災的需求,阿里巴巴在早期通過單元化的方案來解決。
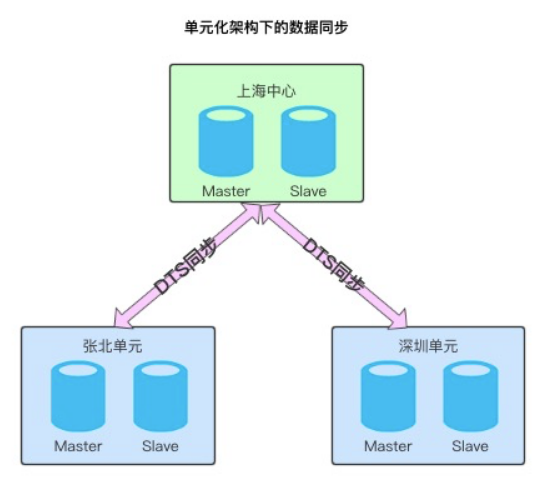
由上圖看到中心和各單元之間通過DTS進行實時資料同步,為了保證中心和單元的資料一致性,我們早期搭建了資料校驗和訂正平臺。主要包括:TCP(terminal compare platform)全量資料校驗訂正平臺(支援表級,庫級,例項級,叢集級別的資料校驗)和AMG(Alibaba Magic Glass)實時的增量資料校驗訂正平臺。
TCP和AMG早已成為阿里巴巴資料庫生態中的核心元件,被廣泛用於眾多場景中保障資料一致性,如:主從複製、單元化同步、邏輯遷移、資料庫拆分、字符集升級等。
2.ADHA的回滾和回補
ADHA(Alibaba Database High Availability)是阿里巴巴集團資料庫高可用體系。ADHA的回滾回補功能幫助我們在發生切換過程中儘量保證資料質量,將老主庫還沒傳到老備庫的資料回滾掉rollback,將回滾掉的資料回補到新主庫中replay。
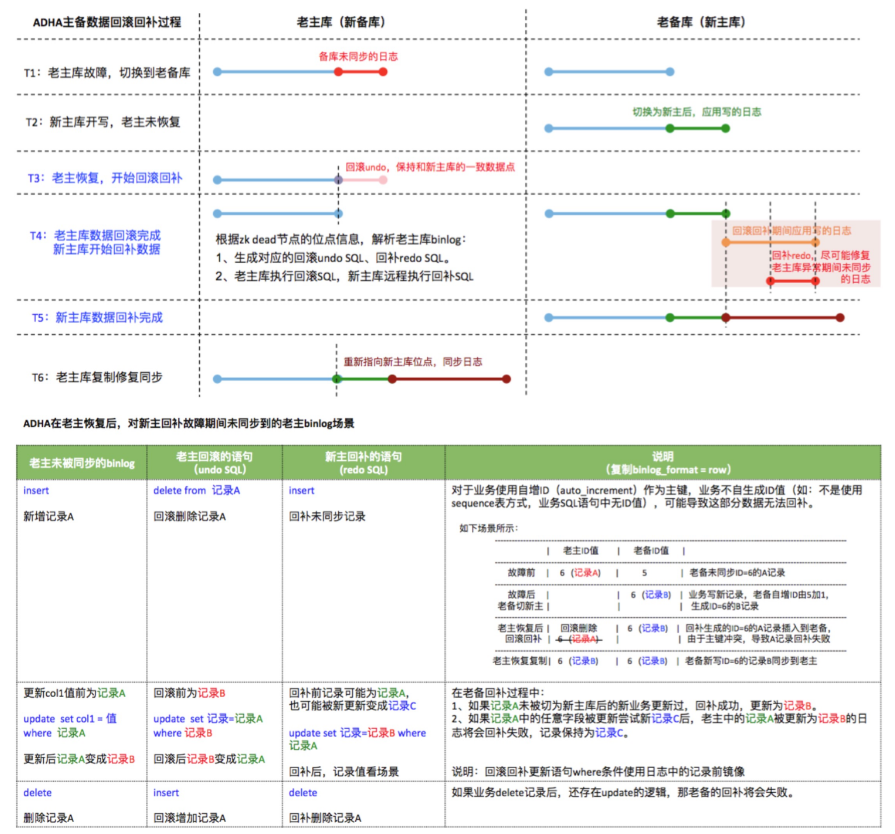
ADHA的回滾和回補的目的是儘量保證HA切換過程中的資料一致性。
3.主從一致性保障措施
複製衝突自動處理:MySQL 5.5/5.6/5.7的引數slave_exec_mode用於解決主從複製衝突和錯誤。預設值是STRICT適合於所有模式(不解決衝突),值IDEMPOTENT 會忽略duplicate-key和no-key-found錯誤,也不適合解決上面主從不一致問題。我們從5.6開始給slave_exec_mode增加了一個值smart,用於自動修復一些場景(包括PK衝突及UK衝突引起的HA_ERR_KEY_NOT_FOUND/HA_ERR_FOUND_DUPP_KEY/HA_ERR_END_OF_FILE),具體處理策略如下圖
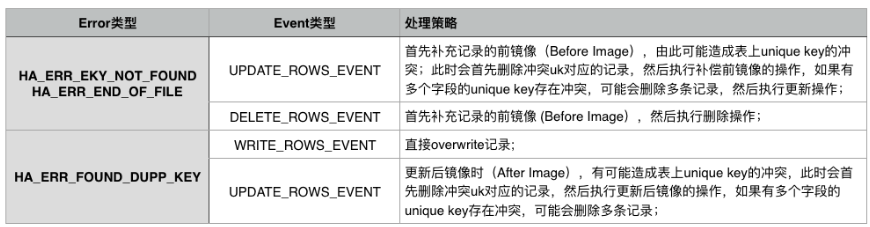
從庫複製開啟SMART模式,可以修復主從複製中斷錯誤,但不能嚴格保證主備一致,因此當使用smart模式修復複製問題後,需要儘快對主從庫做一個全量資料校驗(這裡包括TCP全量校驗+AMG增量校驗),以識別有差異的資料。
4.最大保護邏輯 Max Protection
為了保證主從強一致,我們增加了MySQL最大保護(maximum protection)模式功能,簡稱MP模式(這個是參照ORACLE資料庫的最大保護模式(maximum protection))設計做的,具體由引數 maximum_protection 控制,取值為 ON和OFF )。當配置半同步時,一旦判斷主從連線斷開了,會讓主庫停止對外服務,主庫所有當前連線會被KILL,並拒絕接受普通帳號新的連線請求。此刻如果有事務在等待從庫迴應binlog的同步資訊這一步,連線是無法被kill,該事務在等待超時後會繼續走完(Engine Commit),然後返回網路錯誤給客戶端。即該筆事務被提交了,需要ADHA介入回滾掉。MySQL的MP機制是需要ADHA一起實現的。
引入最大保護邏輯,滿足了對資料一致性要求非常高的業務場景,如金融業務。也給MySQL的高可用解決方案提出更大挑戰。
以上都是我們早期在MySQL主備時代關於“資料一致性”問題的部分對策,其目的都是為了儘可能的保證“資料一致性”,並沒有徹底解決“資料一致性”問題。然而我們相信技術的發展能帶來更大的運維便利性以及更好的使用者體驗,以Google Spanner以及Amazon Aruora 為代表的NewSQL系統為資料庫的“資料一致性”給出了與以往不同的思路: 基於一致性協議!基於一致性協議我們構建了高效能強一致MySQL資料庫,RDS三節點企業版。關於一致性協議和RDS三節點企業版相關知識下面的章節會給大家詳細介紹,敬請關注!
原文連結
本文為雲棲社群原創內容,未經