
資料倉庫系列之資料質量管理
資料質量一直是資料倉庫領域一個比較令人頭疼的問題,因為資料倉庫上層對接很多業務系統,業務系統的髒資料,業務系統變更,都會直接影響資料倉庫的資料質量。因此資料倉庫的資料質量建設是一些公司的重點工作。
一、資料質量
資料質量的高低代表了該資料滿足資料消費者期望的程度,這種程度基於他們對資料的使用預期。資料質量必須是可測量的,把測量的結果轉化為可以理解的和可重複的數字,使我們能夠在不同物件之間和跨越不同時間進行比較。 資料質量管理是通過計劃、實施和控制活動,運用質量管理技術度量、評估、改進和保證資料的恰當使用。
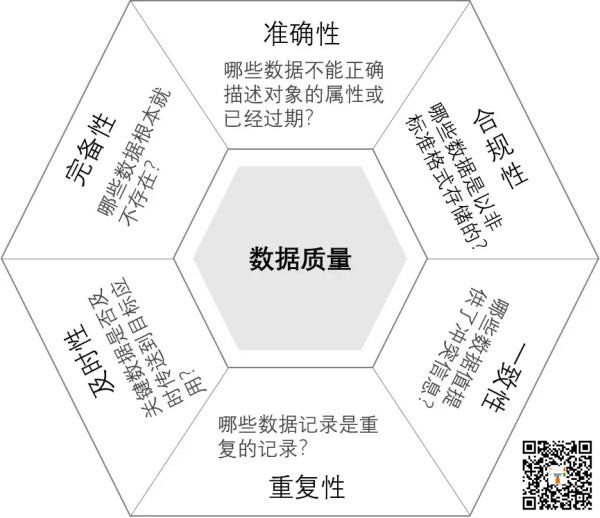
二、資料質量維度
1、準確性:資料不正確或描述物件過期
2、合規性:資料是否以非標準格式儲存
3、完備性:資料不存在
4、及時性:關鍵資料是否能夠及時傳遞到目標位置
5、一致性:資料衝突
6、重複性:記錄了重複資料
三、資料質量分析
資料質量分析的主要任務就是檢查資料中是否存在髒資料,髒資料一般是指不符合要求以及不能直接進行相關分析的資料。髒資料包括以下內容:
1、預設值
2、異常值
3、不一致的值
4、重複資料以及含有特殊符號(如#、¥、*)的資料
我們已經知道了髒資料有4個方面的內容,接下來我們逐一來看這些資料的產生原因,影響以及解決辦法。
第一、 預設值分析
產生原因:
1、有些資訊暫時無法獲取,或者獲取資訊的代價太大
2、有些資訊是被遺漏的,人為或者資訊採集機器故障
3、屬性值不存在,比如一個未婚者配偶的姓名、一個兒童的固定收入
影響:
1、會丟失大量的有用資訊
2、資料額挖掘模型表現出的不確定性更加顯著,模型中蘊含的規律更加難以把握
3、包含空值的資料回事建模過程陷入混亂,導致不可靠輸出
解決辦法:
通過簡單的統計分析,可以得到含有缺失值的屬性個數,以及每個屬性的未缺失數、缺失數和缺失率。刪除含有缺失值的記錄、對可能值進行插補和不處理三種情況。
第二、 異常值分析
產生原因:業務系統檢查不充分,導致異常資料輸入資料庫
影響:不對異常值進行處理會導致整個分析過程的結果出現很大偏差
解決辦法:可以先對變數做一個描述性統計,進而檢視哪些資料是不合理的。最常用的統計量是最大值和最小值,用力啊判斷這個變數是否超出了合理的範圍。如果資料是符合正態分佈,在原則下,異常值被定義為一組測定值中與平均值的偏差超過3倍標準差的值,如果不符合正態分佈,也可以用原理平均值的多少倍標準差來描述。
第三、 不一致值分析
產生原因:不一致的資料產生主要發生在資料整合過程中,這可能是由於被挖掘的資料是來自不同的資料來源、對於重複性存放的資料未能進行一致性更新造成。例如,兩張表中都儲存了使用者的電話號碼,但在使用者的號碼發生改變時只更新了一張表中的資料,那麼兩張表中就有了不一致的資料。
影響:直接對不一致的資料進行資料探勘,可能會產生與實際相悖的資料探勘結果。
解決辦法:注意資料抽取的規則,對於業務系統資料變動的控制應該保證資料倉庫中資料抽取最新資料
第四、 重複資料及特殊資料產生原因:
產生原因:業務系統中未進行檢查,使用者在錄入資料時多次儲存。或者因為年度資料清理導致。特殊字元主要在輸入時攜帶進入資料庫系統。
影響:統計結果不準確,造成資料倉庫中無法統計資料
解決辦法:在ETL過程中過濾這一部分資料,特殊資料進行資料轉換。
四、資料質量管理
大多數企業都沒有一個很好的資料質量管理的機制,因為他們不理解其資料的價值,並且他們不認為資料是一個組織的資產,而把資料看作建立它的部門領域內的東西。缺乏資料質量管理將導致髒資料、冗餘資料、不一致資料、無法整合、效能底下、可用性差、責任缺失、使用系統使用者日益不滿意IT的效能。
在做資料分析之前一般都應該初步對資料進行評估。初步資料評估通過資料報告來完成的,資料報告通常在準備把資料存入資料倉庫是做一次,它是全面跨資料集的,它描述了資料結構、內容、規則、和關係的概況。通過應用統計方法返回一組關於資料的標準特徵,包括資料型別、欄位長度、列基數、粒度、值、格式、模式、規則、跨列和跨表的資料關係,以及這些關係的基數。初步評估報告的目的是獲得對資料和環境的瞭解,並對資料的狀況進行描述。資料報告應該如下:
|
編號 |
資料質量維度 |
檢查物件 |
檢查項 |
檢查項說明 |
|
1 |
有效性 |
資料行數 |
有效性檢查,單欄位、詳細結果 |
將輸入資料的值與一個既定的值域作比較 |
|
2 |
有效性 |
彙總資料 |
有效性檢查,卷積彙總 |
彙總有效性檢查的詳細結果,將卷積的有效/無效值計數和百分比與歷史水平作比較 |
|
3 |
重複性 |
資料行數 |
重複性檢查,單欄位、詳細結果 |
將輸入資料的值與一個既定的值域資料作比較,檢查資料是否重複 |
|
4 |
重複性 |
彙總資料 |
重複性檢查,卷積彙總 |
彙總重複性檢查的詳細結果,將卷積的重複資料計數和百分比與歷史水平作比較 |
|
5 |
一致性 |
資料行數 |
一致性剖析 |
合理性檢查,將記錄資料的分佈,與國企填充相同的欄位的資料例項作比較 |
|
6 |
一致性 |
彙總資料 |
資料集內容的一致性,所表示的實體的不重複計數和記錄數比率 |
合理性檢查,將資料集內所表示的實體的不同值計數與閾值、歷史計數、或總記錄數作比較 |
|
7 |
一致性 |
彙總資料 |
資料集內容的一致性,二個所表示的實體的不重複計數的比率 |
合理性檢查,將重要欄位/實體的不同值計數的比率與閾值或歷史比率作比較 |
|
8 |
一致性 |
資料行數 |
一致性多列剖析 |
合理性檢查,為了測試業務規則,將跨多個欄位的值的記錄數分佈和歷史百分比作比較 |
|
9 |
一致性 |
日期時間型別檢查 |
表內時序與業務規則的一致性 |
合理性檢查,將日期與時序的業務規則作比較 |
|
10 |
一致性 |
日期時間型別檢查 |
用時一致性 |
合理性檢查,將經過的時間與過去填充相同欄位的資料的例項作比較 |
|
11 |
一致性 |
數值型別檢查 |
數額欄位跨二級欄位計算結果的一致性 |
合理性檢查,將跨一個或多個二級欄位的數額列的計算結果、數量總和、佔總數的百分比和平均數量與歷史計數和百分比作比較,用限定符縮小比較結果 |
|
12 |
完整性/有效性 |
資料行數 |
有效性檢查,表內多列,詳細結果 |
將同一個表中相關列的值與對映關係或業務規則中的值作比較 |
|
13 |
完整性/完備性 |
接收資料狀態 |
資料集的完備性——重複記錄的合理性檢查 |
合理性檢查,將資料集中重複記錄佔總記錄的比例與資料集以前的例項的這個比例作比較 |
|
14 |
完備性 |
資料接收 |
資料集的完備性——將大小與過去的大小作比較 |
合理性檢查,將輸入的大小與以前運行同樣的過程時的輸入大小、檔案記錄資料、訊息的數目或速率、彙總資料等作比較 |
|
15 |
完備性 |
接收資料狀態 |
欄位內容的完備性——來自資料來源的預設值 |
合理性檢查,將資料來源提供的關鍵欄位的預設值記錄資料和百分比與一個既定的閾值或歷史數量和百分比作比較 |
|
16 |
完備性 |
接收資料狀態 |
基於日期標準的資料集的合理性 |
確保關鍵日期欄位的最小和最大日期符合某個合理性規則 |
|
17 |
完備性 |
資料處理 |
資料集的完備性——拒絕記錄的理由 |
合理性檢查,將出於特定原因而被刪除的記錄資料和百分比與一個既定的閾值或歷史資料和百分比作比較 |
|
18 |
完備性 |
資料處理 |
經過一個流程的資料集的完備性——輸入和輸出的利率 |
合理性檢查,將處理的輸入和輸出之間的比率與資料集以前的例項的這個比率作比較 |
|
19 |
完備性 |
數值型別檢查 |
欄位內容的完備性——彙總的數額欄位數的比率 |
數額欄位合理性檢查,將輸入和輸出數額欄位彙總數的比率與資料集以前的例項的比率作比較,用於不完全平衡 |
|
20 |
完備性 |
資料處理 |
欄位內容的完備性——推導的預設值 |
合理性檢查,將推導欄位的預設值記錄數和百分比與一個既定的閾值或歷史數量和百分比作比較 |
|
21 |
及時性 |
流程處理檢查 |
用於處理的資料的交付及及時性 |
把資料交付的實際時間與計劃資料交付時間作比較 |
|
22 |
及時性 |
資料處理 |
資料處理用時 |
合理性檢查,將處理用時和歷史處理用時或一個既定的時間限制作比較 |
|
23 |
及時性 |
流程處理檢查情況 |
供訪問的資料的及時可用性 |
將資料實際可供資料的消費者訪問的時間與計劃的資料可用時間作比較 |
|
24 |
一致性 |
資料模型 |
一個欄位內的格式一致性 |
評估列屬性和資料在欄位內資料格式一致性 |
|
25 |
一致性 |
資料模型 |
一個欄位預設值使用的一致性 |
評估列屬性和資料在可被賦予預設值的每個欄位中的預設值 |
|
26 |
完整性/一致性 |
資料模型 |
跨表的格式一致性 |
評估列屬性和資料在整個資料庫中相同資料型別的欄位內資料格式的一致性 |
|
27 |
完整性/一致性 |
資料模型 |
跨表的預設值使用的一致性 |
評估列屬性和資料在相同資料型別的欄位預設值上的一致性 |
|
28 |
完備性 |
總體資料庫內容 |
資料集的完備性——元資料和參考資料的充分性 |
評估元資料和參考資料的充分性 |
|
29 |
一致性 |
彙總資料日期檢查 |
按聚合日期彙總的記錄數的一致性 |
合理性檢查,把與某個聚合日期關聯的記錄數和百分比與歷史記錄數和百分比作比較 |
|
30 |
一致性 |
彙總資料日期檢查 |
按聚合日期彙總的數額欄位資料的一致性 |
合理性檢查,把按聚合日期彙總的數額欄位資料總計和百分比與歷史總計和百分比 |
|
31 |
一致性 |
總體資料庫內容 |
與外部基準比較的一致性 |
把資料質量測量結果與一組基準,如行業或國家為類似的資料建立的外部測量基準作比較 |
|
32 |
一致性 |
總體資料庫內容 |
資料集的完備性——針對特定目的的總體充分性 |
把巨集觀資料庫內容(例如:資料域、記錄數、資料的歷史廣度、表示的實體)與特定資料用途的需求作比較 |
|
33 |
一致性 |
總體資料庫內容 |
資料集的完備性——測量和控制的總體充分性 |
評估測量和控制的成效 |
|
34 |
完整性/有效性 |
跨庫跨表資料檢查 |
有效性檢查,跨表,詳細結果 |
比較跨表的對映或業務規則的關係中的值,以保證資料關聯一致性 |
|
35 |
完整性/一致性 |
跨庫跨表資料檢查 |
跨表多列剖析一致性 |
跨表合理性檢查,將跨相關表的欄位的值的記錄資料分佈於歷史百分比作比較,用於測試遵從業務規則的情況 |
|
36 |
完整性/一致性 |
跨庫跨表時序檢查 |
跨表的時序與業務規則的一致性 |
跨表合理性檢查,對日期值與跨表的業務規則進行時序比較 |
|
37 |
完整性/一致性 |
跨表的數值型別檢查 |
跨表數額列計算結果的一致性 |
跨表合理性檢查,比較相關表的彙總數額欄位總計,佔總計百分比、平均值或它們之間的比率 |
|
38 |
完整性/一致性 |
跨表的彙總資料日期檢查 |
按聚合日期彙總跨表數額列的一致性 |
跨表合理性檢查,比較相關表的按聚合日期彙總的數額欄位總計、佔總計百分比 |
|
39 |
完整性/完備性 |
跨庫跨表資料檢查 |
父/子參考完整性 |
確定父表/子表之間的參考完整性,以找出無父記錄的子記錄和值 |
|
40 |
完整性/完備性 |
跨庫跨表資料檢查 |
子/父參考完整性 |
確定父表/子表之間的參考完整性,以找出無子記錄的父記錄和值 |
|
41 |
完整性/完備性 |
接收資料狀態 |
資料集的完備性——重複資料刪除 |
確定並刪除重複記錄 |
|
42 |
完備性 |
資料接收 |
資料集的完備性——對於處理的可用性 |
對於檔案,確認要處理的所有檔案都可用 |
|
43 |
完備性 |
資料接收 |
資料集的完備性——記錄數與控制記錄相比 |
對於檔案,對檔案中的記錄資料和在一個控制記錄中記載的記錄數作比較 |
|
44 |
完備性 |
資料接收 |
資料集的完備性——彙總數額欄位資料 |
對於檔案,對數額欄位的彙總值和在一個控制記錄中的彙總值作比較 |
|
45 |
完備性 |
接收資料狀態 |
記錄的完備性——長度 |
確保記錄的長度滿足已定義的期望 |
|
46 |
完備性 |
接收資料狀態 |
欄位的完備性——不可為空的欄位 |
確保所有不可為空的欄位都被填充 |
|
47 |
完備性 |
接收資料狀態 |
基於日期標準的資料集的完備性 |
確保關鍵日期欄位的最小和最大日期符合確定載入資料引數的規定範圍 |
|
48 |
完備性 |
接收資料狀態 |
欄位內容的完備性——接收到的資料缺少要處理的關鍵欄位 |
在處理記錄前檢測欄位的填充情況 |
|
49 |
完備性 |
資料處理 |
資料集的完備性——經過一個流程的記錄資料的平衡 |
整個資料處理過程的記錄數、被拒絕的記錄資料平衡,包括重複記錄數平衡,用於完全平衡的情況 |
|
50 |
完備性 |
資料處理 |
經過一個流程的資料集的完備性—— 數額欄位的平衡 |
整個過程中的數額欄位內容平衡,用於完全平衡的情況 |
五、總結
資料報告中列出了很多的檢查項都是圍繞資料質量管理相關的檢查,所以做一個數據分析專案前一定要知道客戶的資料質量情況。如果資料質量很糟糕,最終影響的是專案分析的實際效果。例如,使用者業務系統中客戶資訊只輸入了客戶名稱,要分析客戶型別就會存在預設值。當然有一些維度屬性我們可以通過事實表反算資料進入維度表來補充維度屬性。個人建議在資料分析專案中一定要對維度屬性進行評估,在專案處理前利用簡單的模型告訴客戶能夠出具的效果。
本文就講到這裡,文章中如有錯誤或誤導的地方歡迎大家指出糾正。 希望這篇文章能夠給大家帶來幫助,最後感謝大家的閱讀。下一篇資料倉庫系列之關於資料倉庫自動化技術。
歡迎大家關注我的公眾號:小黎子資料分析

相關推薦
資料倉庫系列之資料質量管理
資料質量一直是資料倉庫領域一個比較令人頭疼的問題,因為資料倉庫上層對接很多業務系統,業務系統的髒資料,業務系統變更,都會直接影響資料倉庫的資料質量。因此資料倉庫的資料質量建設是一些公司的重點工作。 一、資料質量 資料質量的高低代表了該資料滿足資料消費者期望的程度,這種程度基於他們對資料的使用預
資料倉庫系列之維度建模
上一篇文章我已經簡單介紹了資料分析中為啥要建立資料倉庫,從本週開始我們開始一起學習資料倉庫。學習資料倉庫,你一定會了解到兩個人:資料倉庫之父比爾·恩門(Bill Inmon)和資料倉庫權威專家Ralph Kimball。Inmon和Kimball兩種DW
資料倉庫系列之維度建模二
在上一篇文章中我們簡單介紹了什麼是維度建模以及維度建模的基本要素,這篇文章中我們依然學習瞭解維度建模中的基本要素事實表和維度表的型別以及維度設計方法。首先裡瞭解維度建模中的事實表型別,在依次介紹維度型別,一致性維度和一致性事實,維度設計方法。接下來進入正題。 &nb
資料倉庫系列之匯流排架構
匯流排架構是資料倉庫建設的總體規劃,從整體視角描述瞭解決方案的維度模型,描述了各個子系統的功能以及關係,描述資料從源系統到決策系統的資料流程,提供建立企業資料倉庫系統的增量式方法。業務需求回答了要做什麼,匯流排架構就是回答怎麼做的問題。 一、整體解決方案架構: &
資料倉庫系列之關於資料倉庫自動化技術
目前市面上的BI工具都在提及敏捷BI解決方案。敏捷BI解決方案所提供的自動化技術支援主要是從資料來源取數到BI前端工具展現。這樣的敏捷BI解決方案在企業資料量不是很龐大的情況下,還是很好的支撐執行。PowerBI可以支援大量的資料處理,但是對於硬體裝置的要求也是非常高的。但是資料量變得越來越龐大就會導致B
資料倉庫系列——5.資料倉庫與資料集市建模
前言 本文將詳細介紹資料倉庫維度建模技術,並重點討論三種基於ER建模/關係建模/維度建模的資料倉庫總體建模體系:規範化資料倉庫,維度建模資料倉庫,以及獨立資料集市。 維度建模的基本概念 維度建模(dimensional modeling
大資料Hive系列之Hive使用者許可權管理
1. 角色 * 建立角色 create role role_name; * 顯示角色 show roles; * 刪除角色 drop role role_name; 2. 使用者 * 使用者進入admin角色許可權 set hive.users.in.admin.role;
大資料系列之資料倉庫Hive知識整理(四)Hive的嚴格模式,動態分割槽,排序,事務,調優
1.Hive的嚴格模式Hive提供了一個嚴格模式,可以防止使用者執行那些產生意想不到的不好的影響的查詢。想想看在那麼大的資料量的前提下,如果我們在分割槽上表上使用查詢所有,或是使用了笛卡爾積查詢資料等等不良情況,那得花費我們多少時間和資源成本,Hive在預設情況下會開啟一種模
Aerospike-Architecture系列之資料管理概述
資料管理概述 Aerospike支援增強的鍵值對操作。除了基本的put()和get()操作,Aerospike支援"CAS"(安全讀/修改/寫)操作,資料庫內計數器,快取操作。資料被結構化放入bin(型別傳統資料庫中的列),每個bin有一個型別。型別可以是整型,字串,二進
大資料Zookeeper系列之Zookeeper服務開機自啟動配置
1. 編寫執行指令碼 $ sudo cd /etc/init.d $ sudo vi zookeeper #!/bin/bash #chkconfig:2345 20 90 #description:zookeeper #processname:zookeeper
大資料Hadoop系列之Hadoop服務開機自啟動配置
1. 編寫執行指令碼 $ sudo cd /etc/init.d $ sudo vi hadoop #!/bin/bash #chkconfig:35 95 1 #description:script to start/stop hadoop su - hadoop
大資料HBase系列之HBase分散式資料庫部署
一、部署準備 1. 依賴框架 大資料Hadoop系列之Hadoop分散式叢集部署:https://blog.csdn.net/volitationLong/article/details/80285123 大資料Zookeeper系列之Zookeeper叢集部署:https://
大資料Zookeeper系列之Zookeeper分散式協調服務部署
一、部署準備 1. 安裝介質 zookeeper-3.4.13:http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz 2. 主機規劃 192.168.233.13
大資料Hive系列之Hive MapReduce
1. JOIN 1.1 join操作 INSERT OVERWRITE TABLE pv_users SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON (pv.userid = u.userid);
大資料HBase系列之初識HBase
1. HBase簡介 1.1 為什麼使用HBase 傳統的RDBMS關係型資料庫(MySQL/Oracle)儲存一定量資料時進行資料檢索沒有問題,可當資料量上升到非常巨大規模的資料(TB/PB)級別時,傳統的RDBMS已無法支撐,這時候就需要一種新型的資料庫系統更好更
大資料Hive系列之Hive常用SQL
1. hive匯出資料到hdfs 語法:export table 表名 to '輸出路徑'; 例子:export table cloud.customer to '/tmp/hive/customer'; 2. beeline連線 $ beeline 語法:beeline> !
大資料Flume系列之Flume叢集搭建
1. 概念 叢集的意思是多臺機器,最少有2臺機器,一臺機器從資料來源中獲取資料,將資料傳送到另一臺機器上,然後輸出。接下來就要實現Flume叢集搭建。叢集如下圖所示。 2. Flume搭建 2.1 部署準備 部署主機 192.168.9.139 host14
大資料Hive系列之Hive API
Maven依賴配置 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://ma
資料倉庫研究之二--mondrian入門
原文:http://blog.csdn.net/infowain/archive/2006/06/24/829074.aspx 以前一直是用MS Anylize Service的,最近要做的專案是java的,小專案預算有限,所以想找一個開源的java的資料倉庫解決方案來用用。
大資料專案實戰之 --- 某App管理平臺的手機app日誌分析系統(三)
一、建立hive分割槽表 ---------------------------------------------------- 1.建立資料庫 $hive> create database applogsdb; 2.建立分割槽表 編寫指令碼。