
在 Web 級叢集中動態調整 Pod 資源限制
作者<br />阿里雲容器平臺技術專家 王程<br />阿里雲容器平臺技術專家 張曉宇(衷源)
<a name="Ga22a"></a>
引子
不知道大家有沒有過這樣的經歷,當我們擁有了一套 Kubernetes 叢集,然後開始部署應用的時候,我們應該給容器分配多少資源呢?很難說。由於 Kubernetes 自己的機制,我們可以理解容器的資源實質上是一個靜態的配置。如果我發發現資源不足,為了分配給容器更多資源,我們需要重建 Pod。如果分配冗餘的資源,那麼我們的 worker node 節點似乎又部署不了多少容器。試問,我們能做到容器資源的按需分配嗎?這個問題的答案,我們可以在本次分享中和大家一起進行探討。
首先允許我們根據我們的實際情況丟擲我們實際生產環境的挑戰。或許大家還記的,2018 的天貓雙 11,一天的總成交額達到了 2135 億。由此一斑可窺全豹,能夠支撐如此龐大規模的交易量背後的系統,其應用種類和數量應該是怎樣的一種規模。在這種規模下,我們常常聽到的容器排程,如:容器編排,負載均衡,叢集擴縮容,叢集升級,應用釋出,應用灰度等等這些詞,在被超大規模叢集這個詞修飾後,都不再是件容易處理的事情。規模本身也就是我們最大的挑戰。如何運營和管理好這麼一個龐大的系統,並遵循業界 dev-ops 宣傳的那樣效果,猶如讓大象去跳舞。但是馬老師說過,大象就該幹大象該乾的事情,為什麼要去跳舞呢。
<a name="1"></a>
Kubernetes的幫助
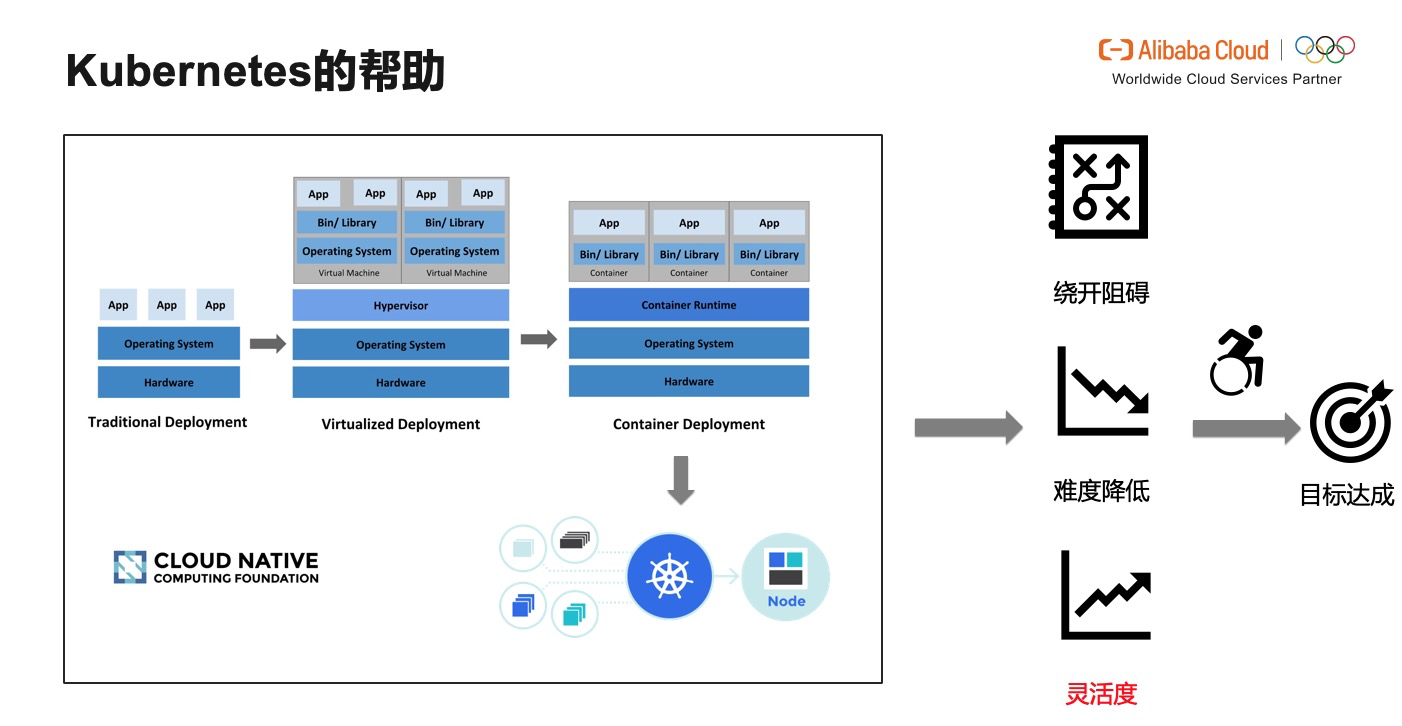
大象是否可以跳舞,帶著這個問題,我們需要從淘寶天貓等 APP 背後系統說起。這套網際網路系統應用部署大致可分為三個階段,傳統部署,虛擬機器部署和容器部署。相比於傳統部署,虛擬機器部署有了更好的隔離性和安全性,但是在效能少不可避免的產生了大量損耗。而容器部署又在虛擬機器部署實現隔離和安全的背景下,提出了更輕量化的解決方案。我們的系統也是沿著這麼一條主航道上執行的。假設底層系統好比一艘巨輪,面對巨量的集裝箱---容器,我們需要一個優秀的船長,對它們進行排程編排,讓系統這艘大船可以避開層層險阻,操作難度降低,且具備更多靈活性,最終達成航行的目的。
<a name="2"></a>
理想與現實
在開始之初,想到容器化和 Kubernetes 的各種美好場景,我們理想中的容器編排效果應該是這樣的:
- 從容:我們的工程師臉上更加從容的面對複雜的挑戰,不再眉頭緊鎖而是更多笑容和自信。
- 優雅:每一次線上變更操作都可以像品著紅酒一樣氣定神閒,優雅地按下執行的回車鍵。
- 有序:從開發到測試,再到灰度釋出,一氣呵成,行雲流水。
- 穩定:系統健壯性良好,任爾東西南北風,我們系統巋然不動。全年系統可用性N多個 9。
- 高效:節約出更多人力,實現“快樂工作,認真生活”。
然而理想很豐滿,現實很骨感。迎接我們的是雜亂和形態各異的窘迫。雜亂是因為:作為一個異軍突起的新型技術棧,很多配套工具和工作流的建設處於初級階段。Demo 版本中執行良好的工具,在真實場景下大規模鋪開,各種隱藏的問題就會暴露無遺,層出不窮。從開發到運維,所有的工作人員都在各種被動地疲於奔命。另外,“大規模鋪開”還意味著,要直接面對形態各異的生產環境:異構配置的機器,複雜的需求,甚至是適配使用者的既往的使用習慣等等。
 <br />除了讓人心力交瘁的混亂,系統還面臨著應用容器的各種崩潰問題:記憶體不足導致的 OOM, CPU quota 分配太少導致的,程序被 throttle,還有頻寬不足,響應時延大幅上升...甚至是交易量在面對訪問高峰時候由於系統不給力導致的斷崖式下跌等等。這些都使我們在大規模商用 Kubernetes 場景中積累非常多的經驗。
<br />除了讓人心力交瘁的混亂,系統還面臨著應用容器的各種崩潰問題:記憶體不足導致的 OOM, CPU quota 分配太少導致的,程序被 throttle,還有頻寬不足,響應時延大幅上升...甚至是交易量在面對訪問高峰時候由於系統不給力導致的斷崖式下跌等等。這些都使我們在大規模商用 Kubernetes 場景中積累非常多的經驗。
<a name="3"></a>
直面問題
<a name="4"></a>
穩定性
問題總要進行面對的。正如某位高人說過:如果感覺哪裡不太對,那麼肯定有些地方出問題了。於是我們就要剖析,問題究竟出在哪裡。針對於記憶體的 OOM,CPU 資源被 throttle,我們可以推斷我們給與容器分配的初始資源不足。
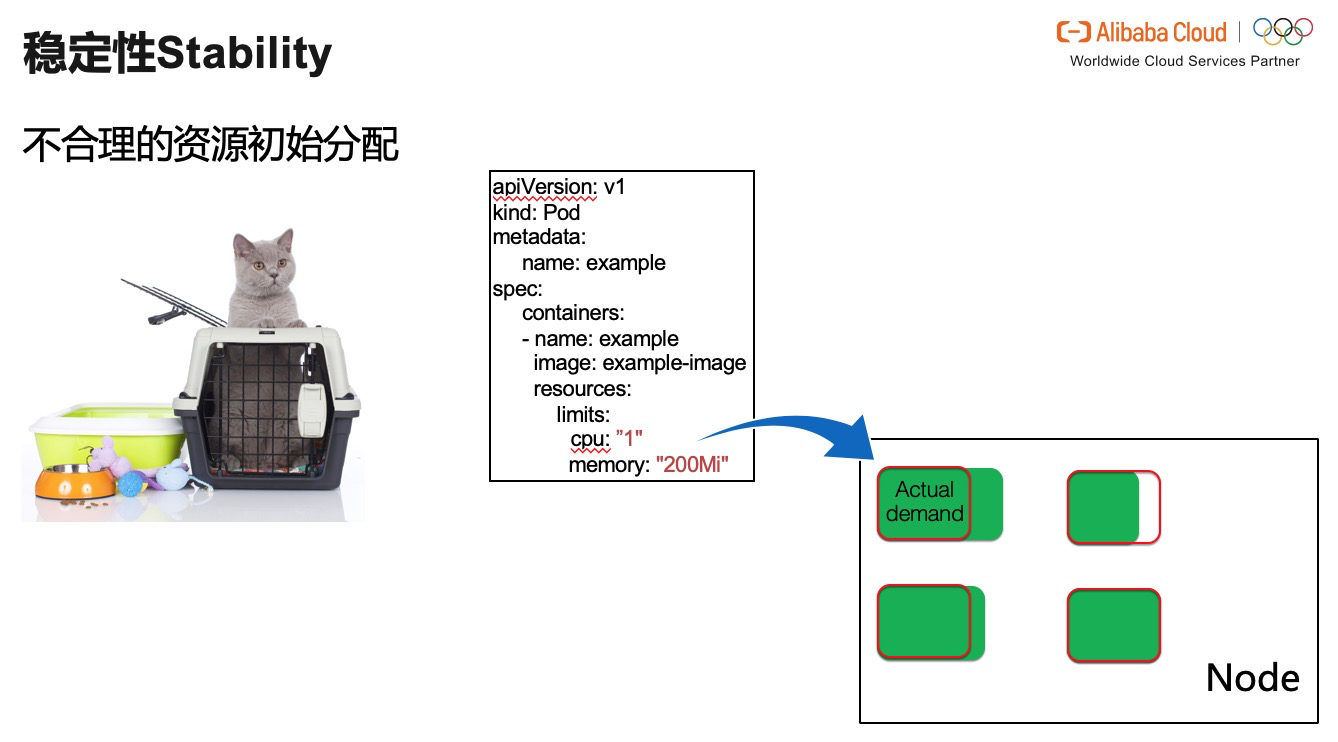
資源不足就勢必造成整個應用服務穩定性下降的問題。例如上圖的場景:雖然是同一種應用的副本,或許是由於負載均衡不夠強大,或者是由於應用自身的原因,甚至是由於機器本身是異構的,相同數值的資源,可能對於同一種應用的不同副本並具有相等的價值和意義。在數值上他們看似分配了相同的資源,然而在實際負載工作時,極有可能出現的現象是肥瘦不均的。
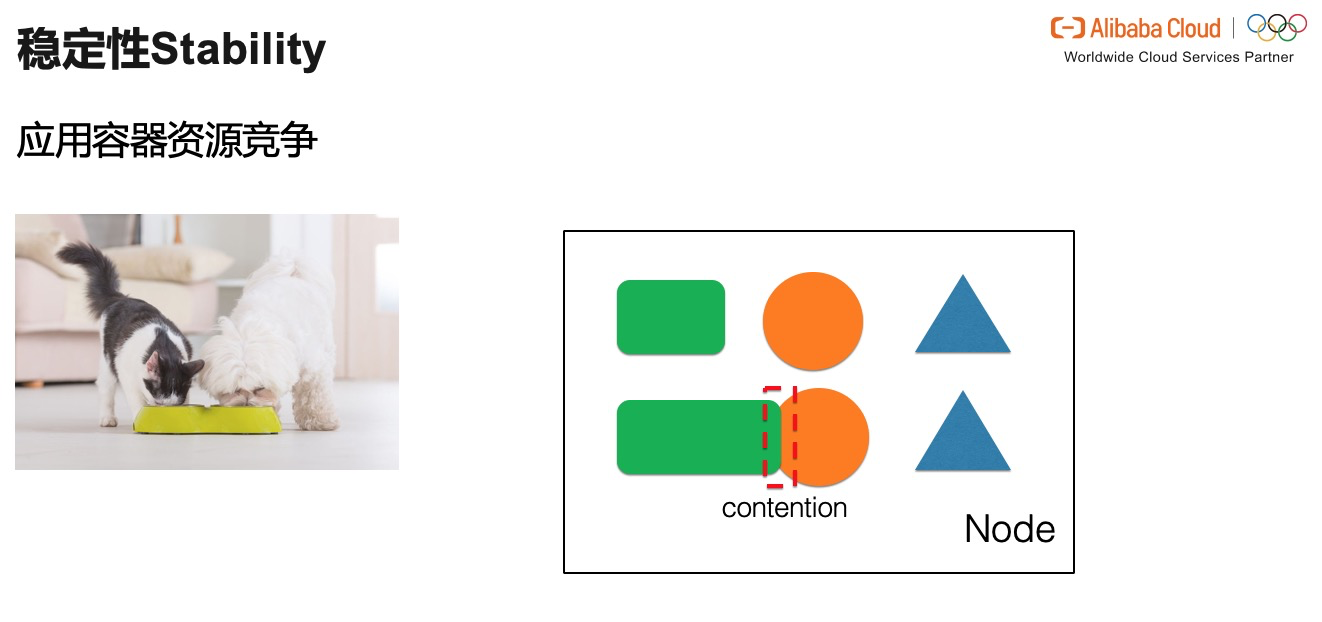 <br />而在資源 overcommit 的場景下,應用在整個節點資源不足,或是在所在的 CPU share pool 資源不足時,也會出現嚴重的資源競爭關係。資源競爭是對應用穩定性最大的威脅之一。所以我們要盡力在生產環境中清除所有的威脅。<br />我們都知道穩定性是件很重要的事情,尤其對於掌控上百萬容器生殺大權的一線研發人員。或許不經心的一個操作就有可能造成影響面巨大的生產事故。因此,我們也按照一般流程也做了系統預防和兜底工作。在預防維度,我們可以進行全鏈路的壓力測試,並且提前通過科學的手段預判應用需要的副本數和資源量。如果沒法準確預算資源,那就只採用冗餘分配資源的方式了。在兜底維度,我們可以在大規模訪問流量抵達後,對不緊要的業務做服務降級並同時對主要應用進行臨時擴容。但是對於陡然增加幾分鐘的突增流量,這麼多組合拳的花費不菲,似乎有些不划算。或許我們可以提出一些解決方案,達到我們的預期。
<br />而在資源 overcommit 的場景下,應用在整個節點資源不足,或是在所在的 CPU share pool 資源不足時,也會出現嚴重的資源競爭關係。資源競爭是對應用穩定性最大的威脅之一。所以我們要盡力在生產環境中清除所有的威脅。<br />我們都知道穩定性是件很重要的事情,尤其對於掌控上百萬容器生殺大權的一線研發人員。或許不經心的一個操作就有可能造成影響面巨大的生產事故。因此,我們也按照一般流程也做了系統預防和兜底工作。在預防維度,我們可以進行全鏈路的壓力測試,並且提前通過科學的手段預判應用需要的副本數和資源量。如果沒法準確預算資源,那就只採用冗餘分配資源的方式了。在兜底維度,我們可以在大規模訪問流量抵達後,對不緊要的業務做服務降級並同時對主要應用進行臨時擴容。但是對於陡然增加幾分鐘的突增流量,這麼多組合拳的花費不菲,似乎有些不划算。或許我們可以提出一些解決方案,達到我們的預期。
<a name="5"></a>
資源利用率
回顧一下我們的應用部署情況:節點上的容器一般分屬多種應用,這些應用本身不一定,也一般不會同時處於訪問的高峰。對於混合部署應用的宿主機,如果能都錯峰分配上面執行容器的資源或許更科學。<br />
應用的資源需求可能就像月亮一樣有陰晴圓缺,有周期變化。例如線上業務,尤其是交易業務,它們在資源使用上呈現一定的週期性,例如:在凌晨、上午時,它的使用量並不是很高而在午間、下午時會比較高。打個比方:對於 A 應用的重要時刻,對於 B 應用可能不那麼重要,適當打壓B應用,騰挪出資源給A應用,這是個不錯的選擇。這聽起來有點像是分時複用的感覺。但是如果我們按照流量峰值時的需求配置資源就會產生大量的浪費。
 <br />除了對於實時性要求很高的線上應用外,我們還有離線應用和實時計算應用等:離線計算對於 CPU 、Memory 或網路資源的使用以及時間不那麼敏感,所以在任何時間段它都可以執行。實時計算,可能對於時間敏感性就會很高。早期,我們業務是在不同的節點按照應用的型別獨立進行部署。從上面這張圖來看,如果它們進行分時複用資源,針對實時性這個需求層面,我們會發現它實際的最大使用量不是 2+2+1=5,而是某一時刻重要緊急應用需求量的最大值,也就是 3 。如果我們能夠資料監測到每個應用的真實使用量,給它分配合理值,那麼就能產生資源利用率提升的實際效果。
<br />除了對於實時性要求很高的線上應用外,我們還有離線應用和實時計算應用等:離線計算對於 CPU 、Memory 或網路資源的使用以及時間不那麼敏感,所以在任何時間段它都可以執行。實時計算,可能對於時間敏感性就會很高。早期,我們業務是在不同的節點按照應用的型別獨立進行部署。從上面這張圖來看,如果它們進行分時複用資源,針對實時性這個需求層面,我們會發現它實際的最大使用量不是 2+2+1=5,而是某一時刻重要緊急應用需求量的最大值,也就是 3 。如果我們能夠資料監測到每個應用的真實使用量,給它分配合理值,那麼就能產生資源利用率提升的實際效果。
對於電商應用,對於採用了重量級 java 框架和相關技術棧的 web 應用,短時間內 HPA 或者 VPA 都不是件容易的事情。先說 HPA,我們或許可以秒級拉起了 Pod,建立新的容器,然而拉起的容器是否真的可用呢。從建立到可用,可能需要比較久的時間,對於大促和搶購秒殺-這種訪問量“洪峰”可能僅維持幾分鐘或者十幾分鐘的實際場景,如果我們等到 HPA 的副本全部可用,可能市場活動早已經結束了。至於社群目前的 VPA 場景,刪掉舊 Pod,建立新 Pod,這樣的邏輯更難接受。所以綜合考慮,我們需要一個更實際的解決方案彌補 HPA 和 VPA 的在這一單機資源排程的空缺。
<a name="6"></a>
解決方案
<a name="7"></a>
交付標準
我們首先要對解決方案設定一個可以交付的標準:那就是 “既要穩定性,也要利用率,還要自動化實施,當然如果能夠智慧化那就更好”。<br />然後再交付標準進行細化:
- 安全穩定:工具本身高可用。所用的演算法和實施手段必須做到可控。
- 業務容器按需分配資源:可以及時根據業務實時資源消耗對不太久遠的將來進行資源消耗預測,讓使用者明白業務接下來對於資源的真實需求。
- 工具本身資源開銷小:工具本身資源的消耗要儘可能小,不要成為運維的負擔。
- 操作方便,擴充套件性強:能做到無需接受培訓即可玩轉這個工具,當然工具還要具有良好擴充套件性,供使用者 DIY。
- 快速發現 & 及時響應:實時性,也就是最重要的特質,這也是和HPA或者VPA在解決資源排程問題方式不同的地方。 <a name="8"></a>
設計與實現
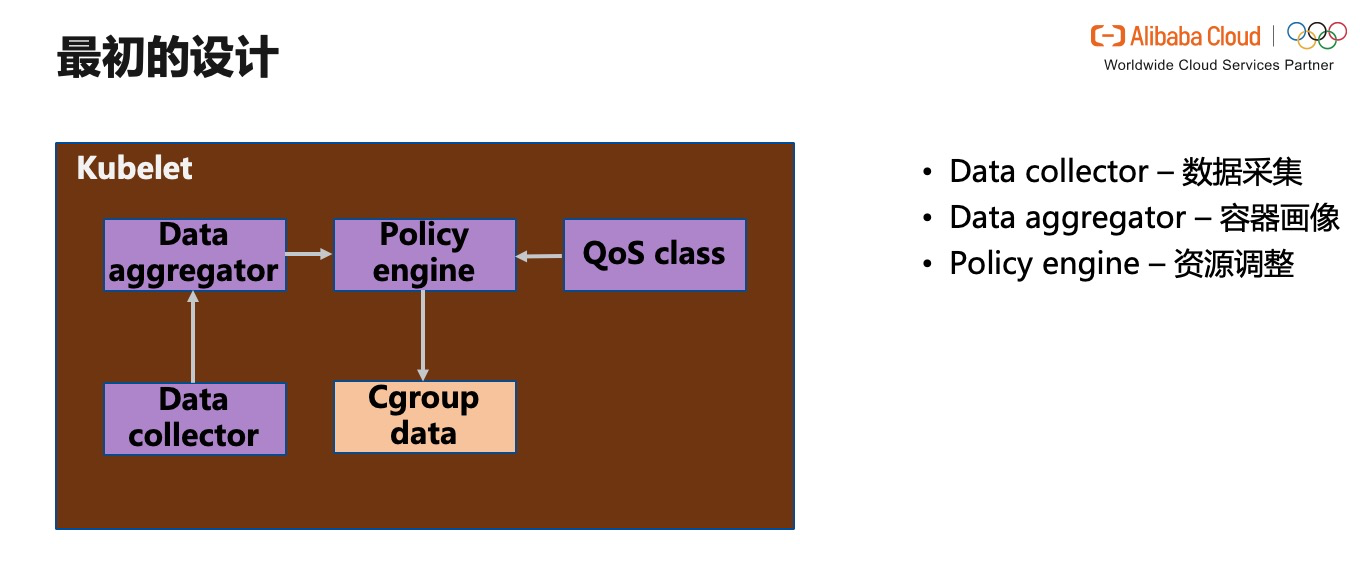
上圖是我們最初的工具流程設計:當一個應用面臨很高的業務訪問需求時,體現在 CPU、Memory 或其他資源型別需求量變大,我們根據 Data Collector 採集的實時基礎資料,利用 Data Aggregator 生成某個容器或整個應用的畫像,再將畫像反饋給 Policy engine。 Policy engine 會瞬時快速修改 容器 Cgroup 檔案目錄下的的引數。我們最早的架構和我們的想法一樣樸實,在 kubelet 進行了侵入式的修改。雖然我們只是加了幾個介面,但是這種方式確實不夠優雅。每次 kubenrnetes 升級,對於 Policy engine 相關元件升級也有一定的挑戰。
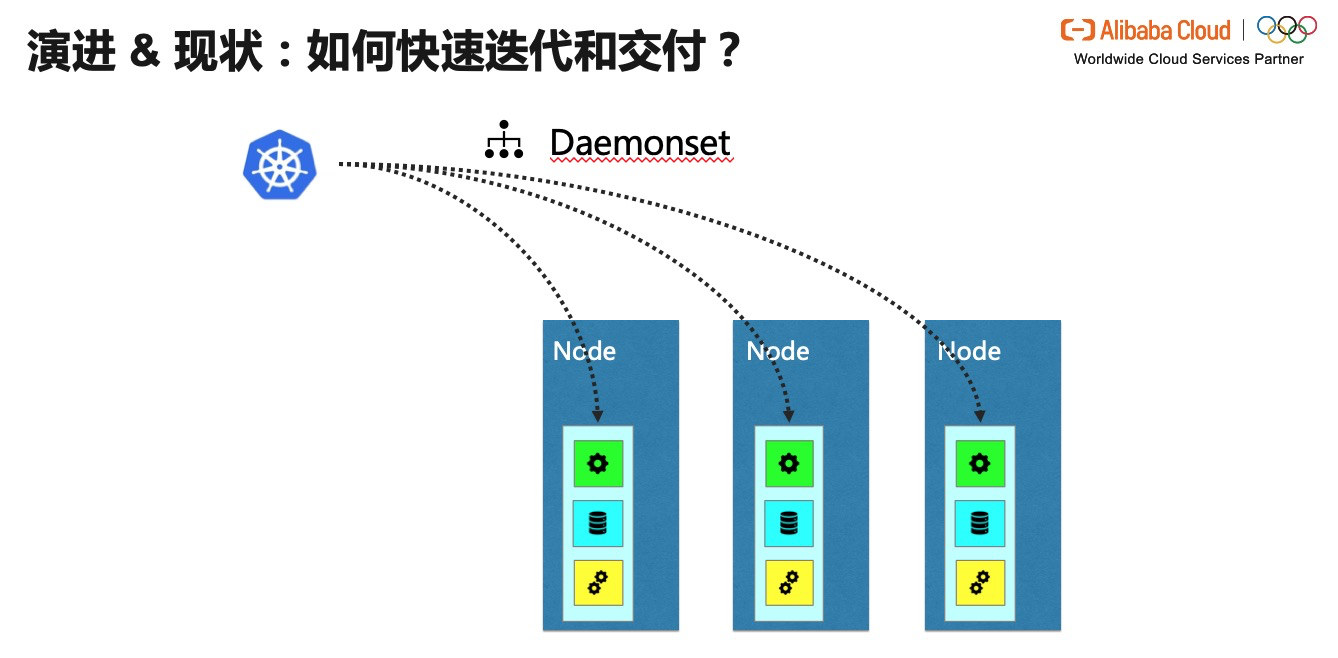 <br />為了做到快速迭代並和 Kubelet 解耦,我們對於實現方式進行了新的演進。那就是將關鍵應用容器化。這樣可以達到以下功效:
<br />為了做到快速迭代並和 Kubelet 解耦,我們對於實現方式進行了新的演進。那就是將關鍵應用容器化。這樣可以達到以下功效:
- 不侵入修改 K8s 核心元件
- 方便迭代&釋出
- 藉助於 Kubernetes 相關的 QoS Class 機制,容器的資源配置,資源開銷可控。
當然在後續演進中,我們也在嘗試和 HPA,VPA 進行打通,畢竟這些和 Policy engine 是存在著互補的關係。因此我們架構進一步演進成如下情形。當 Policy engine 在處理一些更多複雜場景搞到無力時,上報事件讓中心端做出更全域性的決策。水平擴容或是垂直增加資源。
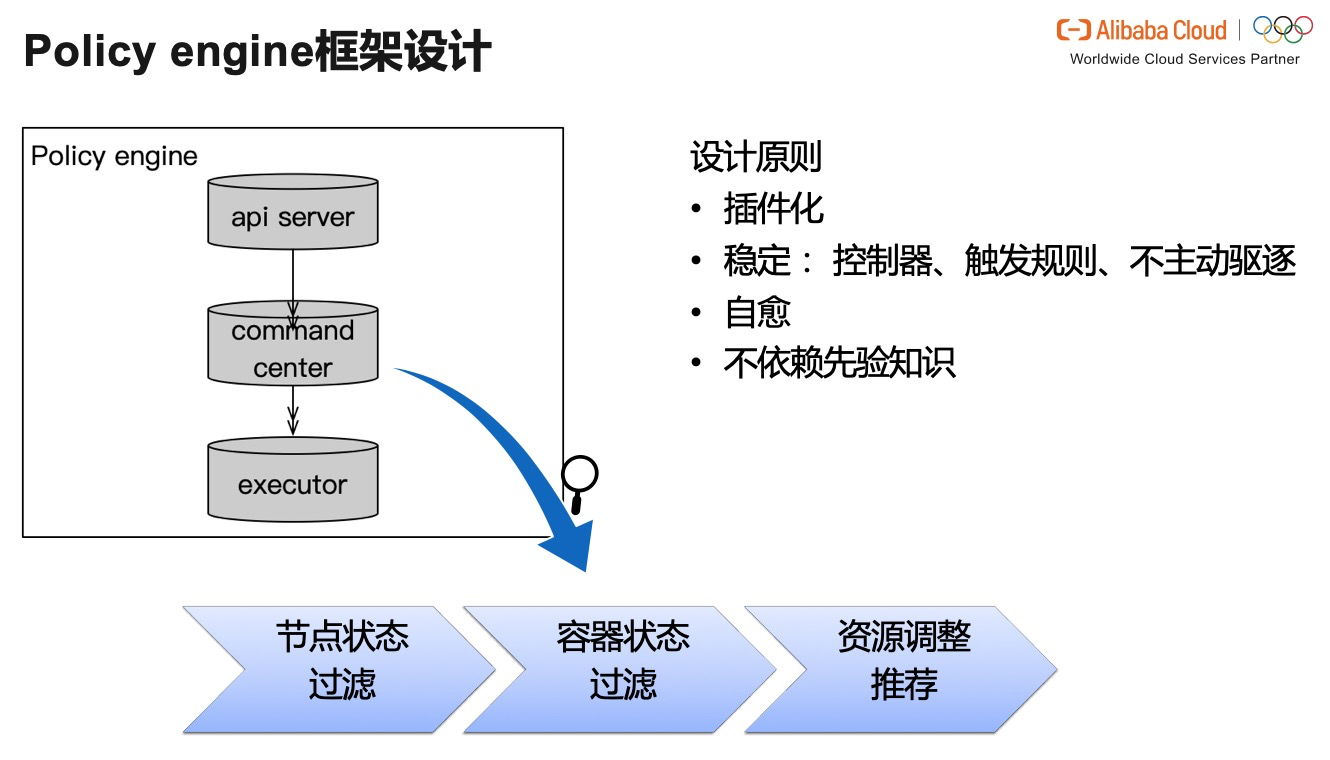
下面我們具體討論一下 Policy engine 的設計。Policy engine 是單機節點上進行智慧排程並執行 Pod 資源調整的核心元件。它主要包括 api server,指揮中心 command center 和執行層 executor。其中 api server 用於服務外界對於 policy engine 執行狀態的查詢和設定的請求;command center 根據實時的容器畫像和物理機本身的負載以及資源使用情況,作出 Pod 資源調整的決策。Executor 再根據 command center 的決策,對容器的資源限制進行調整。同時,executor 也把每次調整的 revision info 持久化,以便發生故障時可以回滾。
指揮中心定期從 data aggregator 獲取容器的實時畫像,包括聚合的統計資料和預測資料,首先判斷節點狀態,例如節點磁碟異常,或者網路不通,表示該節點已經發生異常,需要保護現場,不再對Pod進行資源調整,以免造成系統震盪,影響運維和除錯。如果節點狀態正常,指揮中心會策略規則,對容器資料進行再次過濾。比如容器 cpu 率飆高,或者容器的響應時間超過安全閾值。如果條件滿足,則對滿足條件的容器集合給出資源調整建議,傳遞給executor。
在架構設計上,我們遵循了以下原則:
- 外掛化:所有的規則和策略被設計為可以通過配置檔案來修改,儘量與核心控制流程的程式碼解耦,與 data collector 和 data aggregator 等其他元件的更新和釋出解耦,提升可擴充套件性。
- 穩定,這包括以下幾個方面:
- 控制器穩定性。指揮中心的決策以不影響單機乃至全域性穩定性為前提,包括容器的效能穩定和資源分配穩定。例如,目前每個控制器僅負責一種 cgroup 資源的控制,即在同一時間視窗內,Policy engine 不同時調整多種資源,以免造成資源分配震盪,干擾調整效果。
- 觸發規則穩定性。例如,某一條規則的原始觸發條件為容器的效能指標超出安全閾值,但是為避免控制動作被某一突發峰值觸發而導致震盪,我們把觸發規則定製為,過去一段時間視窗內效能指標的低百分位超出安全閾值;如果規則滿足,說明這段時間內絕大部分的效能指標值都已經超出了安全閾值,就需要觸發控制動作了。
- 另外,與社群版 Vertical-Pod-Autoscaler 不同,Policy engine 不主動驅逐騰挪容器,而是直接修改容器的 cgroup 檔案。
- 自愈:資源調整等動作的執行可能會產生一些異常,我們在每個控制器內都加入了自愈回滾機制,保證整個系統的穩定性。
- 不依賴應用先驗知識:為所有不同的應用分別進行壓測、定製策略,或者提前對可能排部在一起的應用進行壓測,會導致巨大開銷,可擴充套件性降低。我們的策略在設計上儘可能通用,儘量採用不依賴於具體平臺、作業系統、應用的指標和控制策略。
在資源調整方面,Cgroup 支援我們對各個容器的 CPU、記憶體、網路和磁碟 IO 頻寬資源進行,目前我們主要對容器的 CPU 資源進行調整,同時在測試中探索在時分複用的場景下動態調整 memory limit 和 swap usage 而避免 OOM 的可行性;在未來我們將支援對容器的網路和磁碟 IO 的動態調整。 <a name="9"></a>
<a name="d7WS0"></a>
調整效果
 <br />上圖展示了我們在測試叢集得到的一些實驗結果。我們把高優先順序的線上應用和低優先順序的離線應用混合部署在測試叢集裡。SLO 是 250ms,我們希望線上應用的 latency 的 95 百分位值低於閾值 250ms。在實驗結果中可以看到,在大約90s前,線上應用的負載很低;latency 的均值和百分位都在 250ms 以下。到了 90s後,我們給線上應用加壓,流量增加,負載也升高,導致線上應用 latency 的 95 百分位值超過了 SLO。在大約 150s 左右,我們的小步快跑控制策略被觸發,漸進式地 throttle 與線上應用發生資源競爭的離線應用。到了大約 200s 左右,線上應用的效能恢復正常,latency 的 95 百分位回落到 SLO 以下。這說明了我們的控制策略的有效性。
<br />上圖展示了我們在測試叢集得到的一些實驗結果。我們把高優先順序的線上應用和低優先順序的離線應用混合部署在測試叢集裡。SLO 是 250ms,我們希望線上應用的 latency 的 95 百分位值低於閾值 250ms。在實驗結果中可以看到,在大約90s前,線上應用的負載很低;latency 的均值和百分位都在 250ms 以下。到了 90s後,我們給線上應用加壓,流量增加,負載也升高,導致線上應用 latency 的 95 百分位值超過了 SLO。在大約 150s 左右,我們的小步快跑控制策略被觸發,漸進式地 throttle 與線上應用發生資源競爭的離線應用。到了大約 200s 左右,線上應用的效能恢復正常,latency 的 95 百分位回落到 SLO 以下。這說明了我們的控制策略的有效性。
<a name="10"></a>
經驗和教訓
下面我們總結一下在整個專案的進行過程中,我們收穫的一些經驗和教訓,希望這些經驗教訓能夠對遇到類似問題和場景的人有所幫助。
- 避開硬編碼,元件微服務化,不僅便於快速演進和迭代,還有利於熔斷異常服務。
- 儘可能不要呼叫類庫中還是 alpha 或者 beta 特性的介面。 例如我們曾經直接呼叫 CRI 介面讀取容器的一些資訊,或者做一些更新操作,但是隨著介面欄位或者方法的修改,共建有些功能就會變得不可用,或許有時候,呼叫不穩定的介面還不如直接獲取某個應用的列印資訊可能更靠譜。
- 基於 QoS 的資源動態調整方面:如我們之前所講,阿里集團內部有上萬個應用,應用之間的呼叫鏈相當複雜。應用 A 的容器效能發生異常,不一定都是在單機節點上的資源不足或者資源競爭導致,而很有可能是它下游的應用 B、應用 C,或者資料庫、cache 的訪問延遲導致的。由於單機節點上這種資訊的侷限性,基於單機節點資訊的資源調整,只能採用“盡力而為”,也就是 best effort 的策略了。在未來,我們計劃打通單機節點和中心端的資源調控鏈路,由中心端綜合單機節點上報的效能資訊和資源調整請求,統一進行資源的重新分配,或者容器的重新編排,或者觸發 HPA,從而形成一個叢集級別的閉環的智慧資源調控鏈路,這將會大大提高整個叢集維度的穩定性和綜合資源利用率。
- 資源v.s.效能模型:可能有人已經注意到,我們的調整策略裡,並沒有明顯地提出為容器建立“資源v.s.效能”的模型。這種模型在學術論文裡非常常見,一般是對被測的幾種應用進行了離線壓測或者線上壓測,改變應用的資源分配,測量應用的效能指標,得到效能隨資源變化的曲線,最終用在實時的資源調控演算法中。在應用數量比較少,呼叫鏈比較簡單,叢集裡的物理機硬體配置也比較少的情況下,這種基於壓測的方法可以窮舉到所有可能的情況,找到最優或者次優的資源調整方案,從而得到比較好的效能。但是在阿里集團的場景下,我們有上萬個應用,很多重點應用的版本釋出也非常頻繁,往往新版本釋出後,舊的壓測資料,或者說資源效能模型,就不適用了。另外,我們的叢集很多是異構叢集,在某一種物理機上測試得到的效能資料,在另一臺不同型號的物理機上就不會復現。這些都對我們直接應用學術論文裡的資源調控演算法帶來了障礙。所以,針對阿里集團內部的場景,我們採用了這樣的策略:不對應用進行離線壓測,獲取顯示的資源效能模型。而是建立實時的動態容器畫像,用過去一段時間視窗內容器資源使用情況的統計資料作為對未來一小段時間內的預測,並且動態更新;最後基於這個動態的容器畫像,執行小步快跑的資源調整策略,邊走邊看,盡力而為。 <a name="11"></a>
<a name="G7TgI"></a>
總結與展望
總結起來,我們的工作主要實現了以下幾方面的收益:
- 通過分時複用以及將不同優先順序的容器(也就是線上和離線任務)混合部署,並且通過對容器資源限制的動態調整,保證了線上應用在不同負載情況下都能得到足夠的資源,從而提高叢集的綜合資源利用率。
- 通過對單機節點上的容器資源的智慧動態調整,降低了應用之間的性能干擾,保障高優先順序應用的效能穩定性
- 各種資源調整策略通過 Daemonset 部署,可以自動地、智慧地在節點上執行,減少人工干預,降低了運維的人力成本。
展望未來,我們希望在以下幾個方面加強和擴充套件我們的工作:
- 閉環控制鏈路:前面已經提到,單機節點上由於缺乏全域性資訊,對於資源的調整有其侷限性,只能盡力而為。未來,我們希望能夠打通與 HPA 和 VPA 的通路,使單機節點和中心端聯動進行資源調整,最大化彈性伸縮的收益。
- 容器重新編排:即使是同一個應用,不同容器的負載和所處的物理環境也是動態變化的,單機上調整 pod 的資源,不一定能夠滿足動態的需求。我們希望單機上實時容器畫像,能夠為中心端提供更多的有效資訊,幫助中心端的排程器作出更加智慧的容器重編排決策。
- 策略智慧化:我們現在的資源調整策略仍然比較粗粒度,可以調整的資源也比較有限;後續我們希望讓資源調整策略更加智慧化,並且考慮到更多的資源,比如對磁碟和網路IO頻寬的調整,提高資源調整的有效性。
- 容器畫像精細化:目前的容器畫像也比較粗糙,僅僅依靠統計資料和線性預測;刻畫容器效能的指標種類也比較侷限。我們希望找到更加精確的、通用的、反映容器效能的指標,以便更加精細地刻畫容器當前的狀態和對不同資源的需求程度。
- 查詢干擾源:我們希望能找到在單機節點上找到行之有效的方案,來精準定位應用效能受損時的干擾源;這對策略智慧化也有很大意義。 <a name="12"></a>
<a name="RrmTn"></a>
開源計劃
如果大家對於我們的專案程式碼感興趣的話,預計 2019 年 9 月份,我們的工作也將出現在阿里巴巴開源專案OpenKruise (https://github.com/openkruise)